Pandas Set_Option Method
Dnes se podíváme na to, jak použít funkci „pd.set_option()“ k zobrazení všech sloupců v datovém rámci Pandas při jeho prezentaci v nástroji Spyder. Pro použití „pd.set_option()“ se řídíme danou syntaxí:

Začněme se učit koncept s pomocí praktické implementace programu Python.
Příklad: Využití metody Pandas Set_Option k zobrazení všech sloupců
Tato ukázka je vodítkem pro zobrazení všech sloupců v DataFrame pomocí Pandas „set_option()“. Ujasníme si podrobnosti každého kroku implementace této metody Pythonu.
Prvním požadavkem pro praktickou implementaci skriptu Python je najít nejlepší nástroj, kde spouštíte svůj program. Nástroj, který jsme použili pro naši ilustraci, je nástroj „Spyder“. Spustili jsme nástroj a začali pracovat na skriptu Python.
Počínaje kódem musíme zpočátku importovat nezbytné knihovny, které v tomto programu potřebujeme. První knihovna, kterou jsme nahráli do našeho souboru Python, je knihovna Pandas, protože funkce, které zde používáme, poskytuje Pandas. Tuto knihovnu jsme nazvali „pd“. Druhá knihovna, kterou jsme nahráli, je knihovna NumPy. NumPy (Numerical Python) je numerický výpočetní balíček vyvinutý přes programování v Pythonu. Sekce Import NumPy kódu nasměruje Python k integraci modulu NumPy do vašeho aktuálního souboru Python. Část skriptu „as np“ pak instruuje Python, aby přiřadil NumPy zkratku „np“. Umožňuje vám používat metody NumPy zadáním „np.function_name“ místo NumPy.
Nyní začneme s hlavním kódem. Prvořadou a základní potřebou našeho programu je Pandas DataFrame. Zobrazíme tedy všechny sloupce, které obsahuje. Nyní je zcela na vás, zda chcete vytvořit DataFrame se zadanými hodnotami, nebo zda potřebujete importovat soubor CSV. Pro tuto instanci jsme zvolili vytvoření DataFrame s hodnotami NaN. Vyvolali jsme metodu „pd.DataFrame()“, abychom vytvořili DataFrame. Zde jsme uvedli dva parametry – „index“ a „sloupce“. Argument „index“ odkazuje na řádky, což znamená, že nastavujeme řádky pro DataFrame.
Přiřadili jsme parametru „index“ a funkci NumPy „np.arange() s počtem hodnot „6“. Generuje šest řádků pro DataFrame. Vyplní všechny položky hodnotami NaN, protože jsme mu žádnou hodnotu neposkytli. Argument „columns“, jak název udává, se používá k nastavení sloupců pro DataFrame. Je mu také přiřazena funkce „np.arange()“ s počtem hodnot „25“ pro sloupce. Vytvoří tedy 25 sloupců pro DataFrame.
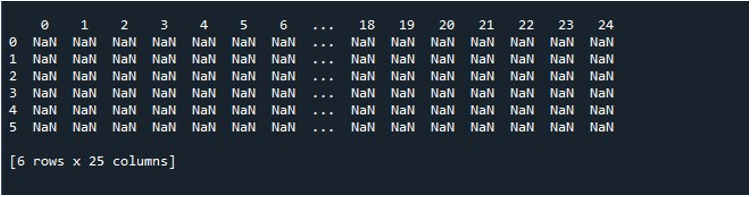
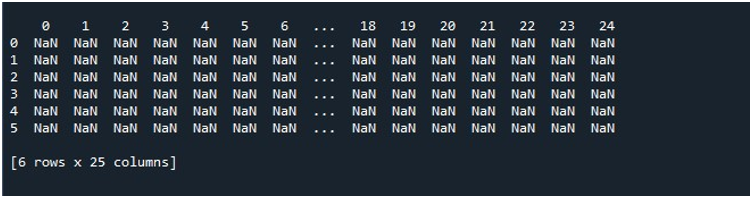
Když tedy zavoláme funkci „pd.DataFrame()“, máme DataFrame s 25 sloupci a 6 řádky vyplněnými hodnotami null. Pro potřebu zachování tohoto DataFrame jsme povinni vytvořit objekt DataFrame, který uchovává jeho obsah. Proto jsme vytvořili objekt DataFrame „random“ a přiřadili mu výsledek, který získáme z metody „pd.DataFrame()“. Nyní jistě chcete vidět generování DataFrame. Python nám poskytuje metodu, jak zobrazit výstup na obrazovce, což je funkce „print()“. Tuto metodu jsme vyvolali předáním objektu DataFrame „random“ jako jeho parametru.
Když spustíme tento fragment kódu, dostaneme náš DataFrame s hodnotami NaN zobrazenými na terminálu. Zde můžeme pozorovat, že jsou vidět některé z prvních sloupců a jen několik z konce. Všechny sloupce mezi nimi jsou zkráceny. Ve výchozím nastavení skryje některé řádky a sloupce, aby se zabránilo frustraci uživatele zobrazením obrovských datových sad.
Můžete dokonce zkontrolovat celkový počet sloupců v DataFrame pomocí funkce „len()“ Pandas. Napište funkci „len()“ na konzolu vašeho nástroje „Spyder“. Napište název DataFrame do závorek pomocí vlastnosti „.columns“. Vrátí nám celkovou délku sloupců ve vašem DataFrame.

Vrátí délku našeho DataFrame, která je 25.
Nyní je dalším a základním úkolem změnit výchozí možnost zobrazení výstupu. Mohou nastat situace, kdy budete chtít zobrazit celý DataFrame na terminálu. Kvůli výchozím hodnotám je mnoho položek zkráceno, což způsobuje zklamání pro uživatele. Zde se dozvíte, jak tento problém překonat. Pandas nám poskytuje funkci „pd.set_option()“ pro změnu výchozího nastavení zobrazení. Hned po zobrazení DataFrame na konzoli vyvoláme metodu „pd.set_option()“. Mezi závorkami této funkce specifikujeme parametr, který potřebujeme použít k zobrazení všech sloupců DataFrame.
Zde jsme použili „display.max_columns“ k zobrazení maximálního počtu sloupců v našem DataFrame. Můžeme také definovat hodnotu tohoto parametru, tedy maximální počet sloupců, které chcete zobrazit. Na druhou stranu jsme nastavili „display.max_columns“ na „None“, což zobrazuje všechny sloupce z DataFrame s maximální délkou. Nakonec jsme použili funkci „print()“ k zobrazení výsledného DataFrame se všemi sloupci viditelnými na terminálu.
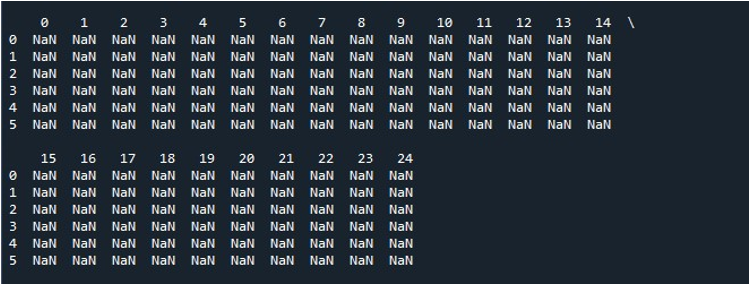
Když stiskneme možnost „Spustit soubor“ v nástroji „Spyder“, můžeme zobrazit vystavený DataFrame. Tento DataFrame má šest řádků a počet sloupců, které obsahuje, je 25. Nejsou zde žádné sloupce, které by byly zkráceny, protože je nyní povolena funkce „pd.set_option()“ s maximální délkou sloupce.
Můžeme dokonce resetovat možnost zobrazení, protože jakmile nastavíme délku zobrazení na maximum, bude se nadále zobrazovat DataFrames se všemi sloupci v tomto konkrétním souboru Python. K tomu využíváme Pandas „pd.reset_option()“. Tuto funkci vyvoláme a jako parametr této funkce poskytneme „display.max_columns“.

Tím získáme počáteční nastavení zobrazení pro poskytnutý DataFrame.
Závěr
Zobrazení kompletního výstupu na terminálu s obrovským souborem dat nás někdy dostane do problémů, když výchozí nastavení nástroje kontrastují s potřebami uživatele. K vyřešení tohoto neúspěchu nám Pandas poskytuje metodu „pd.set_option()“. V této výukové příručce jsme vás seznámili s touto metodou a nutností ji používat. Toto téma jsme demonstrovali na prakticky zkompilovaných a provedených ukázkových kódech Pythonu. Vykreslili jsme výsledky ilustrace provedené na „Spyder“. Vysvětlili jsme, jak zobrazit všechny sloupce DataFrame na konzole změnou výchozích nastavení a také resetováním všech nastavení na výchozí. Věnování plně soustředěné pozornosti praktické implementaci modulu vám umožní jej použít, kdykoli se setkáte s takovým problémem.