„Pandas“ je skvělý jazyk pro provádění analýzy dat díky svému skvělému ekosystému balíčků python zaměřených na data. To usnadňuje analýzu a import obou faktorů. Směrodatná odchylka je „typická“ odchylka odvozená od průměru. Používá se hodně, protože vrací původní měrné jednotky datového rámce. Pandy použily std() pro výpočet směrodatné odchylky. Směrodatnou odchylku lze vypočítat z daných hodnot, které mohou být v datovém rámci ve formě řádku nebo sloupce. Budeme implementovat všechny možné způsoby, jak se používá standardní odchylka pandy. Pro implementaci kódu použijeme nástroj „spyder“, protože je napsán v prostředí přátelském k pythonům.“
Syntax
'df.std ( ) “
Následující syntaxe se používá pro výpočet směrodatné odchylky v datovém rámci. „df“ v datovém rámci je zkratka „dataframe“. Co dělá směrodatná odchylka? Měří, jak rozšířená jsou požadovaná data. Čím více rozšířených vysokých hodnot, tím vyšší by měla nastat standardní odchylka.
Vrátit se
Směrodatná odchylka pandy vrací datový rámec, pokud je úroveň specifikována na základě požadavku.
Pamatujte, že funkce „std()“ bude při výpočtu standardní odchylky pandy automaticky ignorovat hodnoty „NaN“ v „df“. „NaN“ lze vysvětlit jako „není číslo“, což znamená, že žádnému konkrétnímu není přiřazena žádná hodnota.
Níže jsou uvedeny metody, které budou provedeny s příklady standardní odchylky pand:
-
- Výpočet směrodatné odchylky pandy v jednom sloupci.
- Výpočet směrodatné odchylky pandy ve více sloupcích.
- Výpočet směrodatné odchylky pandy pro všechny číselné sloupce.
- standardní odchylka pandy pomocí osy = 1.
- standardní odchylka pandy pomocí osy = 0.
Vytvoření datového rámce pro výpočet směrodatné odchylky v Pandas
Nejprve otevřete software „spyder“. Nyní importujte knihovnu pandas jako pd. Vytvoříme datový rámec, který se skládá z výsledkové tabulky s výrazy „x“, „y“ a „z“ s jejich body jako „22“, „10“, „11“, „16“, „12“, „45“. “, „36“ a „40“. Máme jejich hodnoty asistencí jako „8“, „9“, „13“, „7“, „22“, „24“, „4“ a „6“, také s hodnotou doskoků „17“, „ 14“, „3“, 5, „9“, „8“, „7“ a „4“.
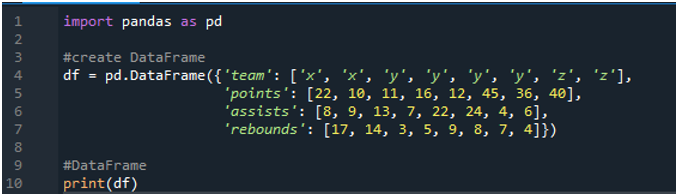
Displeje zobrazují vytvořený datový rámec podle hodnot přiřazených v kódu:

Příklad č. 01: Výpočet standardní odchylky Pandas v jednom sloupci
V tomto příkladu vypočítáme směrodatnou odchylku jednoho sloupce v datovém rámci pandy. Datový rámec má hodnoty týmu jako „u“, „v“ a „b“ s jejich body jako „44“, „33“, „22“, „44“, „45“, „88“, „96“. “ a „78“. Hodnoty asistencí jsou „7“, „8“, „9“, „10“, „11“, „14“, „18“ a „17“, přičemž hodnoty doskoků jsou také „11“, „ 9“, „8“, „7“, „6“, „5“, „4“ a „3“. Sloupec „body“ je vybrán z datového rámce pro výpočet směrodatné odchylky jednoho sloupce.
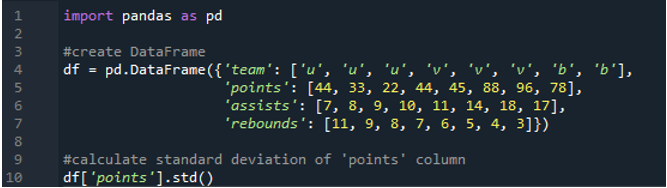
Výstup ukazuje směrodatnou odchylku vypočtenou ze sloupce „body“:

Příklad č. 02: Výpočet standardní odchylky Pandas ve více sloupcích
V tomto příkladu provedeme výpočty směrodatné odchylky pandy ve více sloupcích. V tomto datovém rámci jsou data opět ze sportovní výsledkové tabulky s hodnotami týmu jako „n“, „w“ a „t“ se skóre jako „33“, „22“, „66“, „55“, „44“, „88“, „99“ a „77“. Asistence jako „9“, „7“, „8“, „11“, „16“, „14“, „12“ a „13“ a doskoky jako „5“, „8“, „1“, „ 2“, „3“, „4“, „6“ a „7“. Zde vypočítáme směrodatnou odchylku dvou sloupců „body“ a „odskoky“ pomocí funkce std() aplikované na datový rámec.
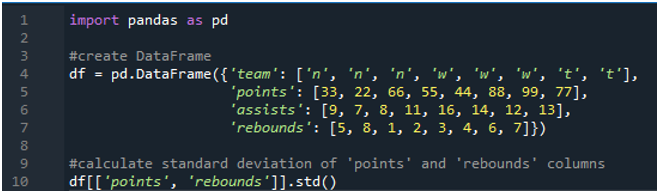
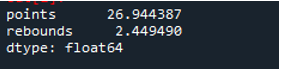
Jak vidíme, výstup ukazuje směrodatnou odchylku 26,944387 ve sloupci bodů a 2,449490 ve sloupci odrazu.
Příklad č. 03: Výpočet standardní odchylky Pandas pro všechny číselné sloupce
Nyní jsme se naučili, jak vypočítat směrodatnou odchylku jednoho a více řádků. Co když nechceme specifikovat všechny názvy sloupců v datovém rámci a vypočítat celý datový rámec? To je možné pouze pomocí jednoduché funkce implementace směrodatné odchylky pandas pro výpočet kompletního datového rámce ve výsledcích. Datový rámec se zde skládá z „l“, „m“ a „o“ s hodnotami bodování „33“, „36“, „79“, „78“, „58“, „55“ a dva týmy mají stejné skóre. to je '25'. Asistence jsou „1“, „2“, „3“, „4“, „6“, „9“, „5“ a „7“ a jejich doskoky jako „14“, „10“, „2“ , „5“, „8“, „3“, „6“ a „9“. Můžeme vypočítat všechny standardní odchylky sloupců podle pand v datovém rámci pomocí funkce pandas „std()“.
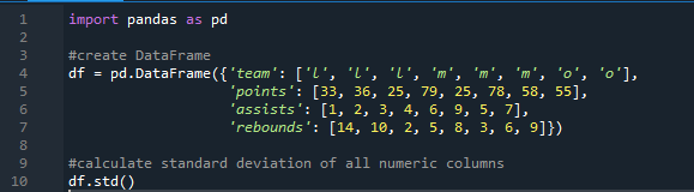
Displej má vypočtenou směrodatnou odchylku celého „df“ uvedenou níže; můžeme si také všimnout, že pandy nevypočítaly směrodatnou odchylku prvního sloupce, který je „tým“, protože se nejedná o číselný sloupec.
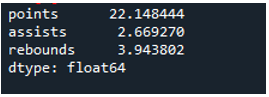
Příklad # 04: Směrodatná odchylka Pandy s použitím osy = 0
V tomto příkladu mají datové rámce týmy sportů jako „g“, „h“ a „k“ s dalšími údaji. Zde vypočítáme směrodatnou odchylku pomocí osy jako „0“, parametru používaného ve směrodatné odchylce pandy. Tento argument vypočítá směrodatnou odchylku po sloupcích datového rámce.
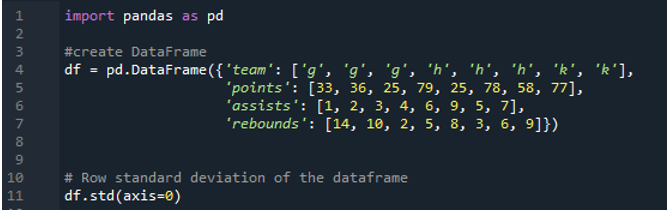
Následující výstup zobrazuje výsledky ve sloupcích vypočtené směrodatné odchylky. Sloupec bodů má vypočtenou směrodatnou odchylku „24,0313062“, sloupec asistencí má vypočítanou směrodatnou odchylku „2,669270“ a vypočtená směrodatná odchylka sloupce odrazu je uvedena jako „3,943802“.
Příklad č. 05: Standardní odchylka Pandy pomocí osy = 1
Zde použijeme parametr osy přiřazený jako „1“ k výpočtu standardní odchylky u pand. Jaký rozdíl může mít osa „1“? Argument osy „1“ vypočítá směrodatnou odchylku po řádcích číselných hodnot v datovém rámci. Datový rámec má tři týmy jako „s“, „d“ a „e“, s přidáním datových sloupců vytvořených jako body týmu, asistence týmu a doskoky týmu. Všechny směry mají v datovém rámci přiřazeny různé hodnoty. Tento parametr osy je takovým předělem hry, protože časem potřebujeme pracovat s daty tam, kde je chceme, ve sloupci plus bod vypočítaný z provedené směrodatné odchylky.
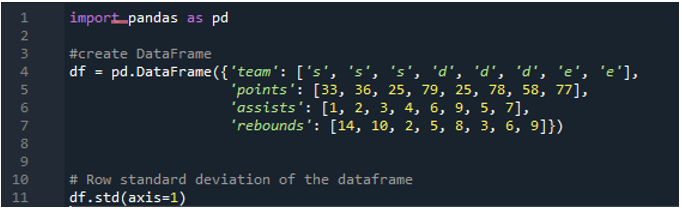
Následující výstup zobrazuje směrodatnou odchylku vypočítanou v řádku datového rámce:
Závěr
Směrodatná odchylka Pandas je velmi technická funkce, která je velmi přínosnou funkcí, protože zjišťuje standardní odchylku paktu nadšení datových rámců pandy. V tomto úvodníku jsme studovali metody výpočtu směrodatné odchylky u pand. Provedli jsme jednosloupcové výpočty směrodatné odchylky a více sloupců a také společně vypočítali směrodatnou odchylku celého datového rámce. Všechny strategie fungují dobře, pokud jsou používány konzistentně a s požadovanými výsledky.