Tento článek pojednává o tom, jak používat rozhraní Elasticsearch multi-get API k načítání více dokumentů JSON na základě jejich ID. Kromě toho vám Elasticsearch umožňuje použít jediný dotaz k získání dokumentů z indexů pouze pomocí ID dokumentů.
Pojďme prozkoumat.
Syntaxe požadavku
Následuje syntaxe rozhraní Elasticsearch multi-get API:
GET /_mget
GET /
Multi-get API podporuje více indexů, což vám umožňuje načítat dokumenty, i když nejsou ve stejném indexu.
Požadavek podporuje následující parametry cesty:
-
– Název indexu, ze kterého se mají načíst dokumenty podle jejich ID.
Můžete také zadat další parametry dotazu, jak je uvedeno:
- Přednost – Definuje preferovaný uzel nebo fragment.
- Reálný čas – Pokud je nastaveno na hodnotu true, operace se provádí v reálném čase.
- Obnovit – Vynutí operaci obnovit cílové fragmenty před načtením zadaných dokumentů.
- Směrování – Hodnota, která se používá ke směrování operací do konkrétního datového fragmentu.
- Store_fields – Načte pole dokumentu uložená v rejstříku místo dokumentu.
- _zdroj – Booleovská hodnota, která definuje, zda má požadavek vrátit pole _source nebo ne.
Dotaz vyžaduje tělo, které obsahuje následující hodnoty:
- Docs – Určuje dokumenty, které chcete načíst. Kromě toho tato část podporuje následující atributy:
- _id – Jedinečné ID cílového dokumentu.
- _index – Index, který obsahuje cílový dokument.
- Směrování – Klíč pro primární fragment dokumentu.
- _zdroj – Pokud je true, zahrnuje všechna zdrojová pole; jinak je vylučuje.
- _uložená_pole – Uložená_pole, která chcete zahrnout.
- ID – ID dokumentů, které chcete načíst.
Příklad 1: Načtení více dokumentů ze stejného rejstříku
Následující příklad ukazuje, jak použít rozhraní Elasticsearch multi-get API k načtení dokumentů se specifickými ID z indexu Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Daný požadavek by měl načíst dokumenty se zadanými ID z indexu Netflix. Výsledný výstup je následující:
{'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'nalezeno': pravda,
'_source': {
'duration': '90 min',
'listed_in': 'Dokumenty',
'country': 'Spojené státy',
'date_added': '25. září 2021',
'show_id': 's1',
'ředitel': 'Kirsten Johnson',
'release_year': 2020,
'rating': 'PG-13',
'description': 'Jak se její otec blíží ke konci života, filmařka Kirsten Johnson zinscenuje jeho smrt vynalézavými a komickými způsoby, aby jim oběma pomohla čelit nevyhnutelnému.',
'type': 'Film',
'title': 'Dick Johnson je mrtvý'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'nalezeno': pravda,
'_source': {
'country': 'Německo, Česká republika',
'show_id': 's13',
'ředitel': 'Christian Schwochow',
'release_year': 2021,
'rating': 'TV-MA',
'description': 'Poté, co je většina její rodiny zavražděna při teroristickém bombovém útoku, je mladá žena nevědomky nalákána, aby se přidala právě ke skupině, která je zabila.',
'type': 'Film',
'title': 'Jsem Karel',
'duration': '127 min',
'listed_in': 'Drama, mezinárodní filmy',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Melání Fouché, Elizaveta Maximová',
'date_added': '23. září 2021'
}
}
]
}
Požadavek můžeme také zjednodušit vložením ID dokumentů do jednoduchého pole, jak je znázorněno v následujícím:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Předchozí požadavek by měl provést podobnou akci.
Příklad 2: Načtení dokumentů z více indexů
V následujícím příkladu požadavek načte více dokumentů z různých indexů, jak je znázorněno:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Výsledný výstup je následující:

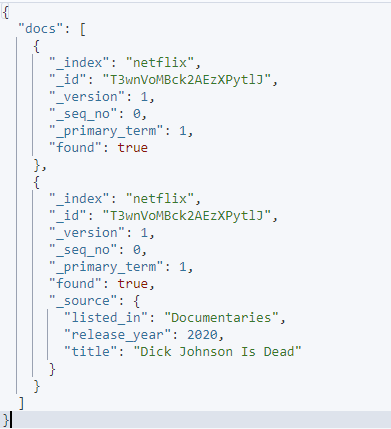
Příklad 3: Vyloučení konkrétních polí
Konkrétní pole můžeme z daného požadavku vyloučit pomocí parametrů source_include a source_exclude.
Příklad je uveden:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: reporting' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': nepravda
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
Daný požadavek používá zdrojové zahrnutí a vyloučení k určení, která pole chcete v daném dokumentu načíst.
Výsledný výstup je následující:
Závěr
V tomto příspěvku jsme diskutovali o základech práce s rozhraním Elasticsearch multi-get API, které vám umožňuje načítat více dokumentů z různých zdrojů na základě jejich ID. Neváhejte a prozkoumejte další dokumenty pro více informací.
Šťastné kódování!