V tomto článku budeme diskutovat o tom, jak alokovat ODLIŠNÝ paměť přes „ pytorch_cuda_alloc_conf “ metoda.
Co je metoda „pytorch_cuda_alloc_conf“ v PyTorch?
V zásadě platí, že „ pytorch_cuda_alloc_conf ” je proměnná prostředí v rámci PyTorch. Tato proměnná umožňuje efektivní správu dostupných zdrojů zpracování, což znamená, že modely běží a produkují výsledky v co nejkratším možném čase. Pokud není provedeno správně, „ ODLIŠNÝ “výpočetní platforma zobrazí “ nedostatek paměti ” a ovlivní dobu běhu. Modely, které mají být trénovány pro velké objemy dat nebo mají velké „ velikosti dávek ” může způsobit chyby za běhu, protože výchozí nastavení na ně nemusí stačit.
' pytorch_cuda_alloc_conf 'proměnná používá následující' možnosti ” pro zpracování alokace zdrojů:
- rodák : Tato možnost využívá již dostupná nastavení v PyTorch k přidělení paměti probíhajícímu modelu.
- max_split_size_mb : Zajišťuje, že žádný blok kódu větší než zadaná velikost nebude rozdělen. Jedná se o účinný nástroj, jak zabránit „ fragmentace “. Tuto možnost použijeme pro demonstraci v tomto článku.
- roundup_power2_divisions : Tato možnost zaokrouhlí velikost alokace na nejbližší „ síla 2 ” dělení v megabajtech (MB).
- roundup_bypass_threshold_mb: Může zaokrouhlit velikost alokace nahoru pro jakýkoli požadavek, který uvádí více než zadaný práh.
- garbage_collection_threshold : Zabraňuje latenci využitím dostupné paměti z GPU v reálném čase, aby bylo zajištěno, že nebude spuštěn protokol reclaim-all.
Jak alokovat paměť pomocí metody „pytorch_cuda_alloc_conf“?
Každý model s velkou datovou sadou vyžaduje další přidělení paměti, které je větší, než je výchozí nastavení. Vlastní alokaci je třeba specifikovat s ohledem na požadavky modelu a dostupné hardwarové zdroje.
Postupujte podle níže uvedených kroků pro použití „ pytorch_cuda_alloc_conf ” metodu v IDE Google Colab k přidělení více paměti složitému modelu strojového učení:
Krok 1: Otevřete Google Colab
Vyhledejte Google Spolupráce v prohlížeči a vytvořte „ Nový notebook “ začít pracovat:
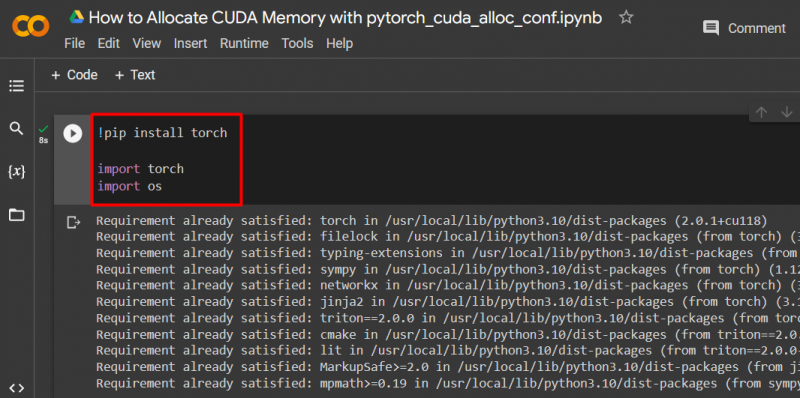
Krok 2: Nastavte vlastní model PyTorch
Nastavte model PyTorch pomocí „ !pip “ instalační balíček pro instalaci “ pochodeň knihovna a import 'příkaz pro import' pochodeň ' a ' vy ” knihovny do projektu:
dovozní pochodeň
importujte nás
Pro tento projekt jsou potřeba následující knihovny:
- Pochodeň – Toto je základní knihovna, na které je PyTorch založen.
- VY – „ operační systém Knihovna se používá ke zpracování úloh souvisejících s proměnnými prostředí, jako je např. pytorch_cuda_alloc_conf ” a také systémový adresář a oprávnění k souboru:
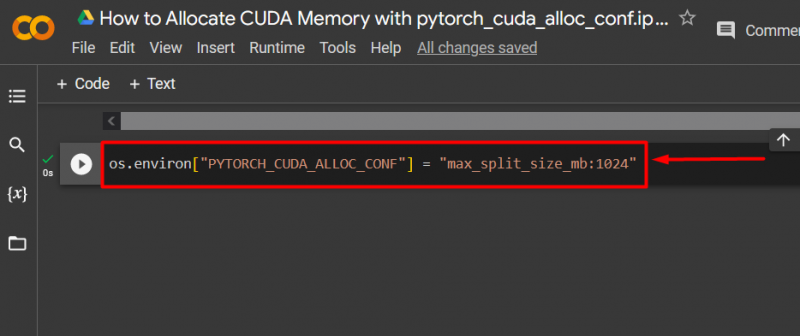
Krok 3: Přidělte paměť CUDA
Použijte „ pytorch_cuda_alloc_conf “ metoda pro určení maximální velikosti rozdělení pomocí “ max_split_size_mb “:
Krok 4: Pokračujte ve svém projektu PyTorch
Po upřesnění „ ODLIŠNÝ 'přidělení prostoru pomocí ' max_split_size_mb “, pokračujte v práci na projektu PyTorch jako obvykle bez obav z “ nedostatek paměti “chyba.
Poznámka : K našemu zápisníku Google Colab můžete přistupovat zde odkaz .
Profesionální tip
Jak již bylo zmíněno dříve, „ pytorch_cuda_alloc_conf ” může mít kteroukoli z výše uvedených možností. Použijte je podle konkrétních požadavků vašich projektů hlubokého učení.
Úspěch! Právě jsme ukázali, jak používat „ pytorch_cuda_alloc_conf “ metoda k určení “ max_split_size_mb “ pro projekt PyTorch.
Závěr
Použijte „ pytorch_cuda_alloc_conf ” metoda alokace paměti CUDA pomocí kterékoli z dostupných možností podle požadavků modelu. Každá z těchto možností je určena ke zmírnění určitého problému se zpracováním v projektech PyTorch pro lepší běh a plynulejší operace. V tomto článku jsme předvedli syntaxi pro použití „ max_split_size_mb ” pro definování maximální velikosti rozdělení.