Příklad 1: Získejte pozici vzoru z řetězce pomocí funkce Grep() v R
K extrakci pozice zadaného vzoru z řetězce se použije funkce grep() z R.
grep('i+', c('opravit', 'rozdělit', 'kukuřice n', 'barva'), perl=TRUE, value=FALSE)Zde používáme funkci grep(), kde je vzor „+i“ specifikován jako argument, který se má porovnat ve vektoru řetězců. Nastavíme znakové vektory, které obsahují čtyři řetězce. Poté nastavíme argument „perl“ s hodnotou TRUE, která označuje, že R používá knihovnu regulárních výrazů kompatibilní s perl, a parametr „value“ je specifikován s hodnotou „FALSE“, která se používá k načtení indexů prvků. ve vektoru, který odpovídá vzoru.
Pozice vzoru „+i“ z každého řetězce vektorových znaků se zobrazí v následujícím výstupu:

Příklad 2: Porovnejte vzor pomocí funkce Gregexpr() v R
Dále získáme pozici indexu spolu s délkou konkrétního řetězce v R pomocí funkce gregexpr().
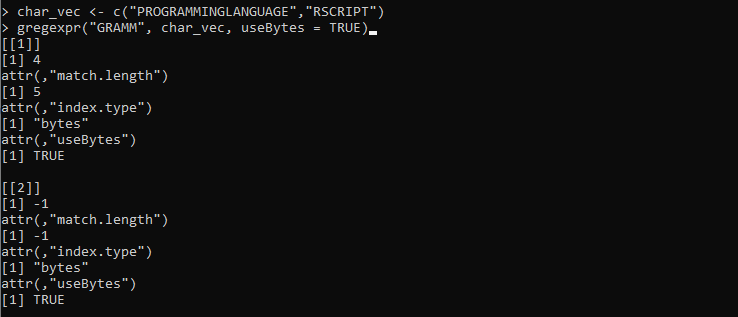
char_vec <- c('PROGRAMOVACÍ JAZYK','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
Zde nastavíme proměnnou „char_vect“, kde jsou řetězce opatřeny různými znaky. Poté definujeme funkci gregexpr(), která převezme řetězec „GRAMM“ tak, aby byl porovnán s řetězci uloženými v „char_vec“. Poté nastavíme parametr useBytes na hodnotu „TRUE“. Tento parametr označuje, že shody by mělo být dosaženo spíše bajt po bajtu než znak po znaku.
Následující výstup, který je načten z funkce gregexpr() představuje indexy a délku obou vektorových řetězců:
Příklad 3: Počítání celkového počtu znaků v řetězci pomocí funkce Nchar() v R
Metoda nchar(), kterou implementujeme v následujícím textu, nám také umožňuje určit, kolik znaků je v řetězci:
Res <- nchar('Počítej každý znak')tisk (Res)
Zde zavoláme metodu nchar(), která je nastavena v proměnné „Res“. Metoda nchar() je poskytována s dlouhým řetězcem znaků, který je počítán metodou nchar() a poskytuje počet znaků čítače v zadaném řetězci. Poté předáme proměnnou „Res“ metodě print(), abychom viděli výsledky metody nchar().
Výsledek je přijat v následujícím výstupu, který ukazuje, že zadaný řetězec obsahuje 20 znaků:

Příklad 4: Extrahujte podřetězec z řetězce pomocí funkce Substring() v R
K extrahování konkrétního podřetězce z řetězce používáme metodu substring() s argumenty „start“ a „stop“.
str <- podřetězec('MORNING', 2, 4)tisknout (str)
Zde máme proměnnou „str“, kde je volána metoda substring(). Metoda substring() bere řetězec „MORNING“ jako první argument a hodnotu „2“ jako druhý argument, což znamená, že se má extrahovat druhý znak z řetězce, a hodnota argumentu „4“ znamená, že čtvrtý znak se má extrahovat. Metoda substring() extrahuje znaky z řetězce mezi zadanou pozicí.
Následující výstup zobrazuje extrahovaný podřetězec, který leží mezi druhou a čtvrtou pozicí v řetězci:

Příklad 5: Zřetězení řetězce pomocí funkce Paste() v R
Funkce paste() v R se také používá pro manipulaci s řetězci, která zřetězí zadané řetězce oddělením oddělovačů.
msg1 <- 'Obsah'msg2 <- 'Psaní'
vložit (msg1, msg2)
Zde specifikujeme řetězce proměnných „msg1“ a „msg2“. Potom použijeme metodu paste() jazyka R ke zřetězení poskytnutého řetězce do jediného řetězce. Metoda paste() bere proměnnou strings jako argument a vrací jeden řetězec s výchozí mezerou mezi řetězci.
Po provedení metody paste() výstup představuje jeden řetězec s mezerou v něm.

Příklad 6: Upravte řetězec pomocí funkce Substring() v R
Kromě toho můžeme také aktualizovat řetězec přidáním podřetězce nebo jakéhokoli znaku do řetězce pomocí funkce substring() pomocí následujícího skriptu:
str1 <- 'Hrdinové'substring(str1, 5, 6) <- 'ic'
cat(' Modified String:', str1)
Řetězec „Heroes“ nastavíme do proměnné „str1“. Poté nasadíme metodu substring(), kde je zadáno „str1“ spolu s hodnotami indexu „start“ a „stop“ podřetězce. Metodě substring() je přiřazen podřetězec „iz“, který je umístěn na pozici, která je pro daný řetězec specifikována ve funkci. Poté použijeme funkci cat() R, která představuje aktualizovanou hodnotu řetězce.
Výstup, který zobrazuje řetězec, je aktualizován novým pomocí metody substring ():

Příklad 7: Formátování řetězce pomocí funkce Format() v R
Operace manipulace s řetězci v R však také zahrnuje odpovídající formátování řetězce. K tomu používáme funkci format(), kde lze řetězec zarovnat a nastavit šířku konkrétního řetězce.
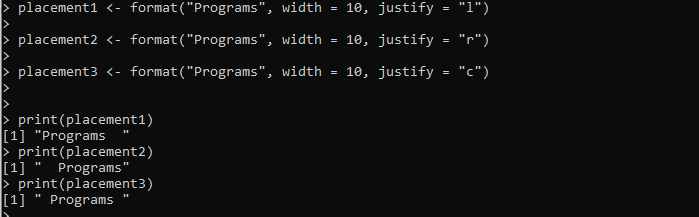
umístění1 <- format('Programy', width = 10, justify = 'l')umístění2 <- format('Programy', width = 10, justify = 'r')
umístění3 <- format('Programy', width = 10, justify = 'c')
tisk (umístění1)
tisk (umístění2)
tisk (umístění3)
Zde nastavíme proměnnou „placement1“, kterou poskytuje metoda format(). Řetězec „programs“, který má být zformátován, předáme metodě format(). Šířka je nastavena a zarovnání řetězce je nastaveno doleva pomocí argumentu „zarovnat“. Podobně vytvoříme další dvě proměnné, „placement2“ a „placement2“, a použijeme metodu format() k odpovídajícímu formátování poskytnutého řetězce.
Výstup zobrazuje tři styly formátování pro stejný řetězec na následujícím obrázku včetně zarovnání vlevo, vpravo a na střed:
Příklad 8: Transformujte řetězec na malá a velká písmena v R
Kromě toho můžeme také transformovat řetězec na malá a velká písmena pomocí funkcí tolower() a toupper() následovně:
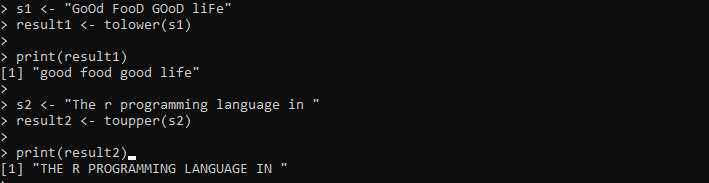
s1 <- 'DOBRÉ JÍDLO DOBRÝ ŽIVOT'výsledek1 <- tolower(s1)
tisknout (výsledek 1)
s2 <- 'Programovací jazyk r v '
result2 <- toupper(s2)
tisknout (výsledek 2)
Zde uvádíme řetězec, který obsahuje velká a malá písmena. Poté je řetězec udržován v proměnné „s1“. Poté zavoláme metodu tolower() a předáme do ní řetězec „s1“, aby se všechny znaky uvnitř řetězce transformovaly na malá písmena. Poté vytiskneme výsledky metody tolower(), která je uložena v proměnné „result1“. Dále do proměnné „s2“ nastavíme další řetězec, který obsahuje všechny znaky malými písmeny. Na tento řetězec „s2“ aplikujeme metodu toupper() a transformujeme existující řetězec na velká písmena.
Výstup zobrazuje oba řetězce v zadaném případě na následujícím obrázku:
Závěr
Naučili jsme se různé způsoby, jak spravovat a analyzovat řetězce, což se nazývá manipulace s řetězci. Extrahovali jsme pozici znaku z řetězce, zřetězili jsme různé řetězce a transformovali řetězec na zadaný případ. Také jsme naformátovali řetězec, upravili řetězec a provádějí se zde různé další operace pro manipulaci s řetězcem.