Tento článek poskytuje pokyny pro implementaci inteligentního vrstvení pro optimalizaci nákladů v segmentu S3.
Co je to inteligentní vrstvení v S3 Bucket?
Data rostou exponenciálně po celém světě. Některá z těchto dat jsou přístupná denně, zatímco ostatní jsou vyžadována pouze příležitostně. Vzhledem k tomu, že S3 je jednou z nejoblíbenějších služeb AWS pro ukládání dat, AWS zavedlo třídu úložiště známou jako 'Inteligentní vrstvení' snížit výdaje na S3 kvůli ukládání dat. Další informace o různých třídách úložiště bucketů S3 naleznete v tomto článku: „Přehled různých tříd úložiště na S3“ .
Intelligent-Tiering může optimalizovat výdaje S3 sledováním vzorců přístupu k datům. Tato funkce je dostatečně účinná, aby určila, ke kterým datům se přistupuje často nebo příležitostně. Na základě těchto vzorů je automaticky identifikuje a umístí je do nákladově nejefektivnější vrstvy bez provozní režie nebo snížení výkonu.
Jak optimalizovat náklady na ukládání dat v Amazon S3 pomocí inteligentního vrstvení?
V závislosti na vzorech přístupu k datům budou objekty, ke kterým se málokdy přistupuje, umístěny do úroveň přístupu s nižšími náklady pro účely optimálních nákladů. Pokud k objektu přistoupí uživatel, bude automaticky a okamžitě přesunut zpět do Úroveň častého přístupu pro dostupnost bez dalších poplatků:
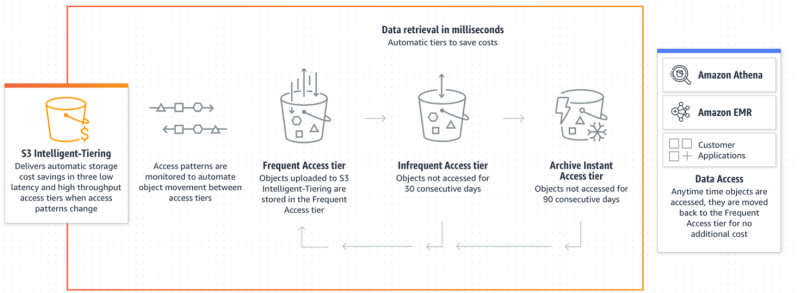
Inteligentní vrstvení je proveditelná a ideální volba pro uživatele, pokud jde o optimalizaci nákladů pro nepředvídatelné vzorce přístupu k datům. Níže jsou uvedeny kroky, ve kterých můžeme implementovat třídu Intelligent-Tiering Storage pro úsporu nákladů:
Krok 1: Ovládací panel S3
Chcete-li dosáhnout nákladově optimálního řešení pro ukládání dat pomocí bucketu S3, vyhledejte 'S3' ve vyhledávací liště AWS a klikněte na ni ze zobrazených výsledků:
Krok 2: Vytvořte kbelík
Klikněte na 'Vytvořit kbelík' tlačítko na Konzole S3 :
Krok 3: Obecné konfigurace
Ze zobrazeného rozhraní zadejte a unikátní identifikátor pro kbelík S3 v 'Obecné konfigurace' sekce:
Krok 4: Klepněte na tlačítko „Vytvořit kbelík“.
Při zachování výchozích hodnot klikněte na 'Vytvořit kbelík' tlačítko umístěné ve spodní části rozhraní:
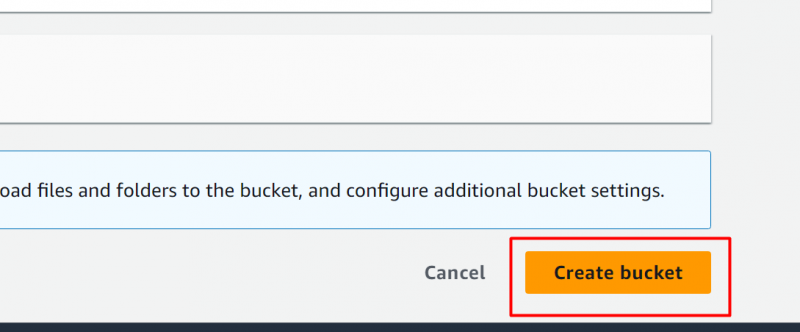
Kbelík byl úspěšně vytvořen. Dále do tohoto bucketu nahrajeme soubor. Kliknutím na název segmentu přejdete do rozhraní pro nahrání souboru:
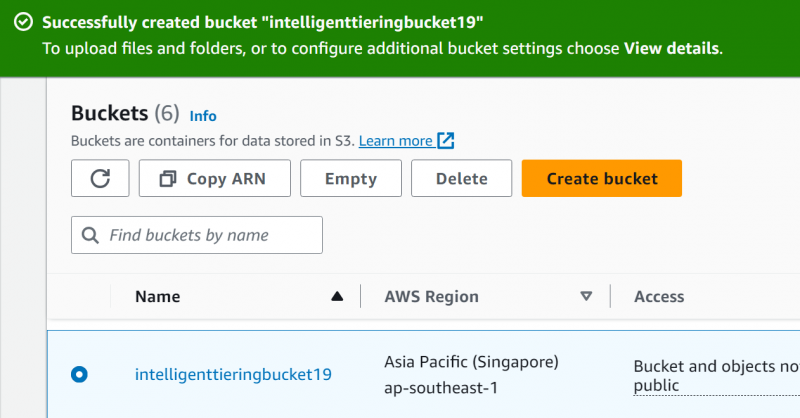
Krok 5: Nahrajte soubory
Klikněte na 'Nahrát' tlačítko na zobrazeném rozhraní:
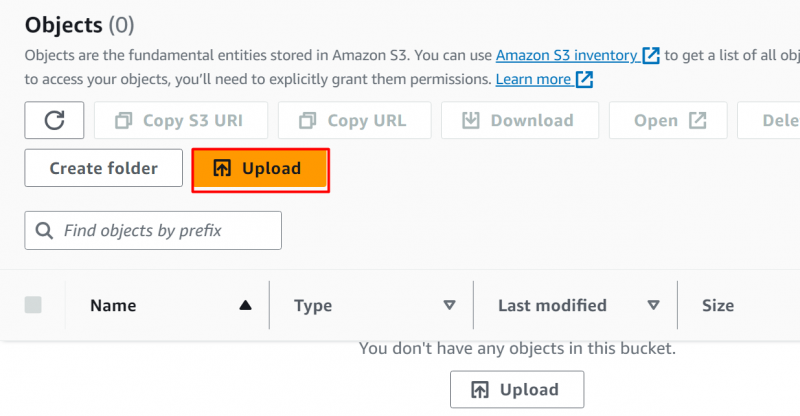
Chcete-li vybrat soubory, klepněte na 'Přidat soubory' a poté vyberte soubory/složky z vašeho zařízení. Soubor byl nahrán do bucketu S3:
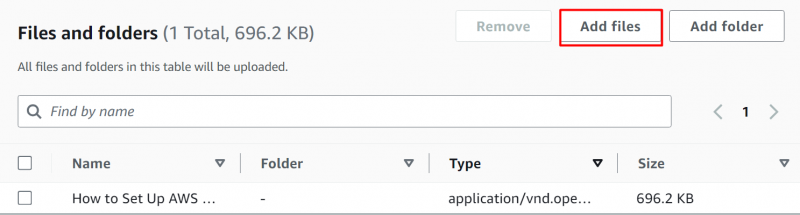
Přejděte na 'Vlastnosti' zablokujte a vyberte „ Inteligentní vrstvení” možnost z Třída úložiště sekce :
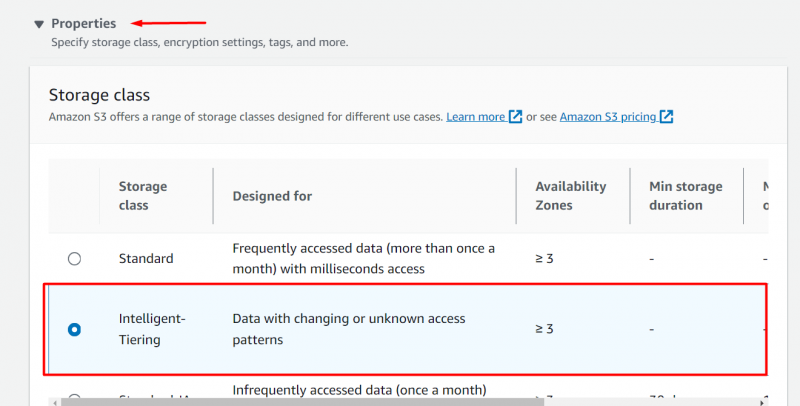
Ponecháním zbytku nastavení beze změny , klikněte na 'Nahrát' tlačítko umístěné ve spodní části rozhraní:
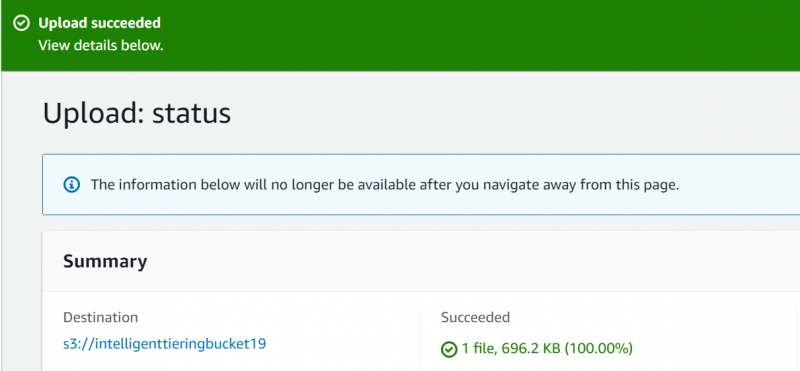
AWS zobrazí a potvrzovací zprávu což znamená, že soubor byl úspěšně nahrán:
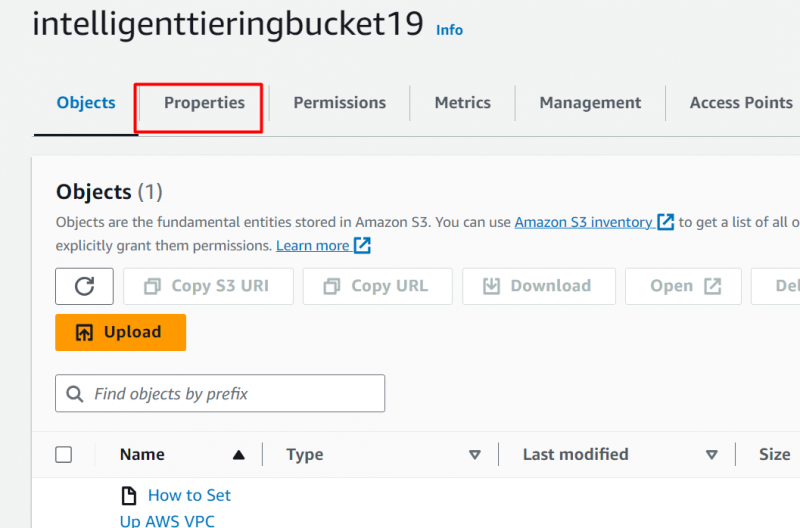
Krok 6: Klepněte na kartu „Vlastnosti“.
Po nahrání souboru klikněte na 'Vlastnosti' karta:
Krok 7: Konfigurace archivu inteligentního vrstvení
z Vlastnosti rozhraní, přejděte dolů na 'Konfigurace inteligentního vrstveného archivu' a klikněte na 'Vytvořit konfigurace' knoflík:
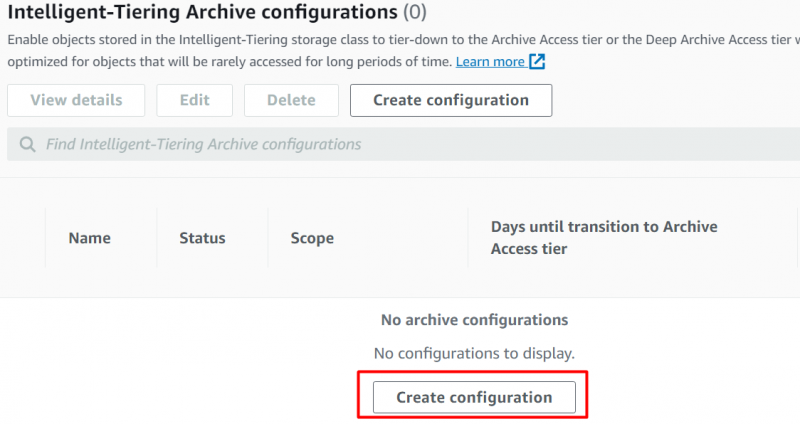
Poskytněte 'Název' a 'Předpona' pro konfigurace na dalším zobrazeném rozhraní:
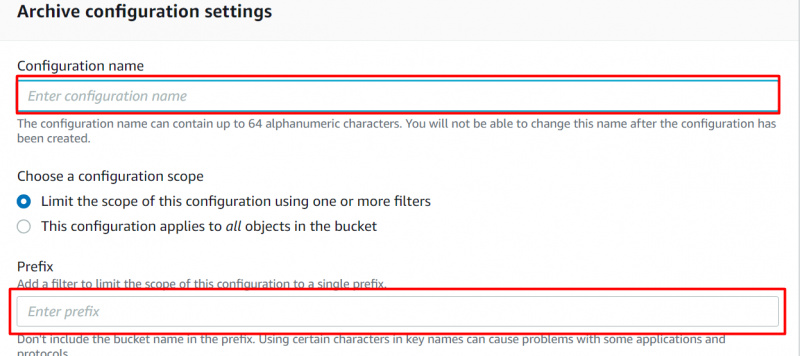
Krok 8: Úroveň přístupu k archivu
Přejděte na 'Akce pravidel archivace' sekce pro konfiguraci, kdy mají být objekty přesunuty. Povolte následující možnost a zadejte počet po sobě jdoucích dnů, po kterých chcete objekty přesunout do Úroveň přístupu k archivu :
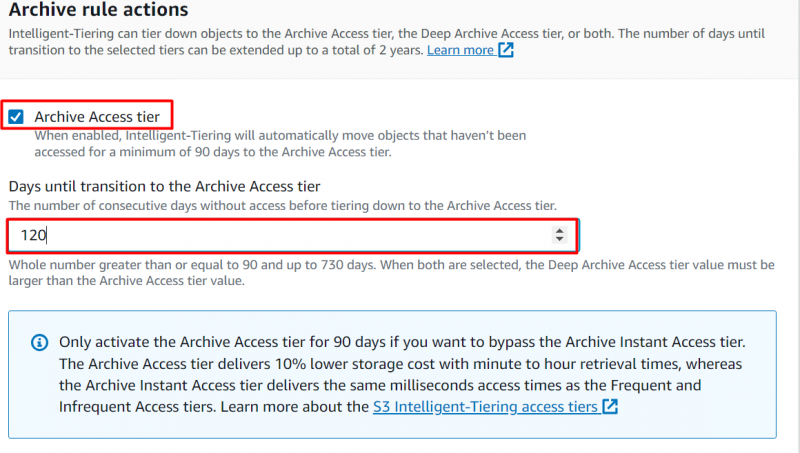
Poznámka : Pokud k objektu není přistupováno minimálně 90 dní, objekt bude automaticky přesunut do úrovně přístupu k archivu. Uživatelé mohou toto období prodloužit na a maximum z 730 dní.
Krok 9: Úroveň přístupu k hlubokému archivu
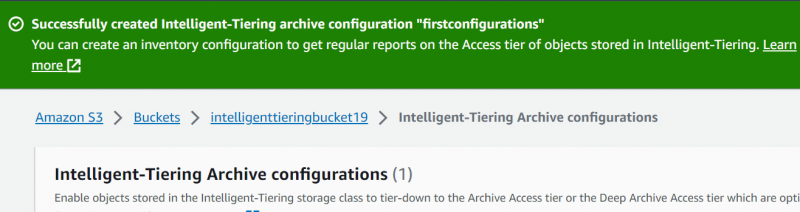
Stejně jako úroveň přístupu k archivu může uživatel nakonfigurovat úroveň přístupu k hlubokému archivu. Povolením následující možnosti zadejte počet dní, po kterých by se měl objekt přesunout do úrovně přístupu k hlubokému archivu. Po zadání počtu dní klikněte na 'Vytvořit' knoflík:
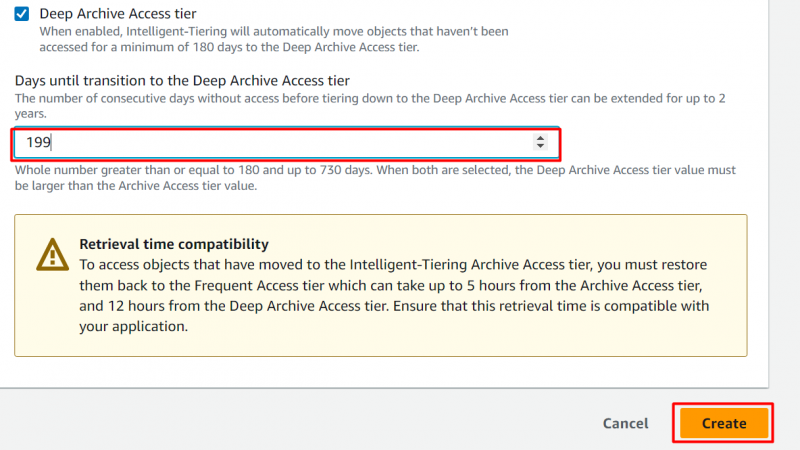
Poznámka : V úrovni přístupu k hlubokému archivu jsou objekty, ke kterým nebylo přistupováno po dobu a minimálně 180 dní jsou přesunuty do této úrovně. Uživatelé mohou tento počet dní upravit na a maximálně 730 dní .
Konfigurace jsou úspěšně provedeny. Nyní, když uživatel nemá k nahraným objektům přístup po určenou dobu, data se automaticky přesunou do různých úrovní, aby se minimalizovaly výdaje:
To je z tohoto průvodce vše.
Závěr
Pro optimalizaci nákladů s bucketem S3 vyberte Třída Intelligent-Tiering při nahrávání souborů a poté uveďte čas pro příslušné úrovně. Intelligent-Tiering šetří náklady tím, že určuje často a zřídka používané objekty do příslušných úrovní. Tento článek poskytuje podrobné pokyny pro dosažení nákladově optimálního řešení s lopatou S3.