Rychlý přehled
Tento příspěvek obsahuje následující sekce:
- Jak používat agenta Async API v LangChain
- Metoda 1: Použití sériového spouštění
- Metoda 2: Použití souběžného spouštění
- Závěr
Jak používat agenta Async API v LangChain?
Chatovací modely provádějí více úkolů současně, jako je porozumění struktuře výzvy, její složitosti, extrahování informací a mnoho dalších. Použití agenta Async API v LangChain umožňuje uživateli vytvářet efektivní modely chatu, které mohou odpovídat na více otázek najednou. Chcete-li se naučit proces používání agenta Async API v LangChain, postupujte podle tohoto průvodce:
Krok 1: Instalace frameworků
Nejprve nainstalujte rámec LangChain, abyste získali jeho závislosti ze správce balíčků Python:
pip install langchain
Poté nainstalujte modul OpenAI pro vytvoření jazykového modelu, jako je llm, a nastavte jeho prostředí:
pip install openai
Krok 2: Prostředí OpenAI
Dalším krokem po instalaci modulů je nastavení prostředí pomocí klíče API OpenAI a Serper API vyhledání dat z Googlu:
import vy
import getpass
vy . přibližně [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Klíč OpenAI API:' )
vy . přibližně [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Serper API Key:' )
Krok 3: Import knihoven
Nyní, když je prostředí nastaveno, jednoduše importujte požadované knihovny jako asyncio a další knihovny pomocí závislostí LangChain:
z langchain. agenti import inicializovat_agenta , load_toolsimport čas
import asyncio
z langchain. agenti import Typ agenta
z langchain. llms import OpenAI
z langchain. zpětná volání . stdout import StdOutCallbackHandler
z langchain. zpětná volání . tracery import LangChainTracer
z aiohttp import ClientSession
Krok 4: Otázky k nastavení
Nastavte datovou sadu otázek obsahující více dotazů souvisejících s různými doménami nebo tématy, které lze vyhledávat na internetu (Google):
otázky = [„Kdo je vítězem šampionátu US Open v roce 2021“ ,
„Jaký je věk přítele Olivie Wildeové“ ,
„Kdo je vítězem světového titulu formule 1“ ,
„Kdo vyhrál finále US Open žen v roce 2021“ ,
„Kdo je manžel Beyonce a jaký je jeho věk“ ,
]
Metoda 1: Použití sériového spouštění
Jakmile jsou všechny kroky dokončeny, jednoduše spusťte otázky, abyste získali všechny odpovědi pomocí sériového spuštění. Znamená to, že bude spuštěna/zobrazena jedna otázka najednou a také vrátí celý čas potřebný k provedení těchto otázek:
llm = OpenAI ( teplota = 0 )nástroje = load_tools ( [ 'google-header' , 'llm-matematika' ] , llm = llm )
činidlo = inicializovat_agenta (
nástroje , llm , činidlo = Typ agenta. ZERO_SHOT_REACT_DESCRIPTION , podrobný = Skutečný
)
s = čas . perf_counter ( )
#configuring time counter pro získání času použitého pro celý proces
pro q v otázky:
činidlo. běh ( q )
Uplynulý = čas . perf_counter ( ) - s
#print celkový čas, který agent použil k získání odpovědí
tisk ( F 'Seriál byl spuštěn za {elapsed:0,2f} sekund.' )
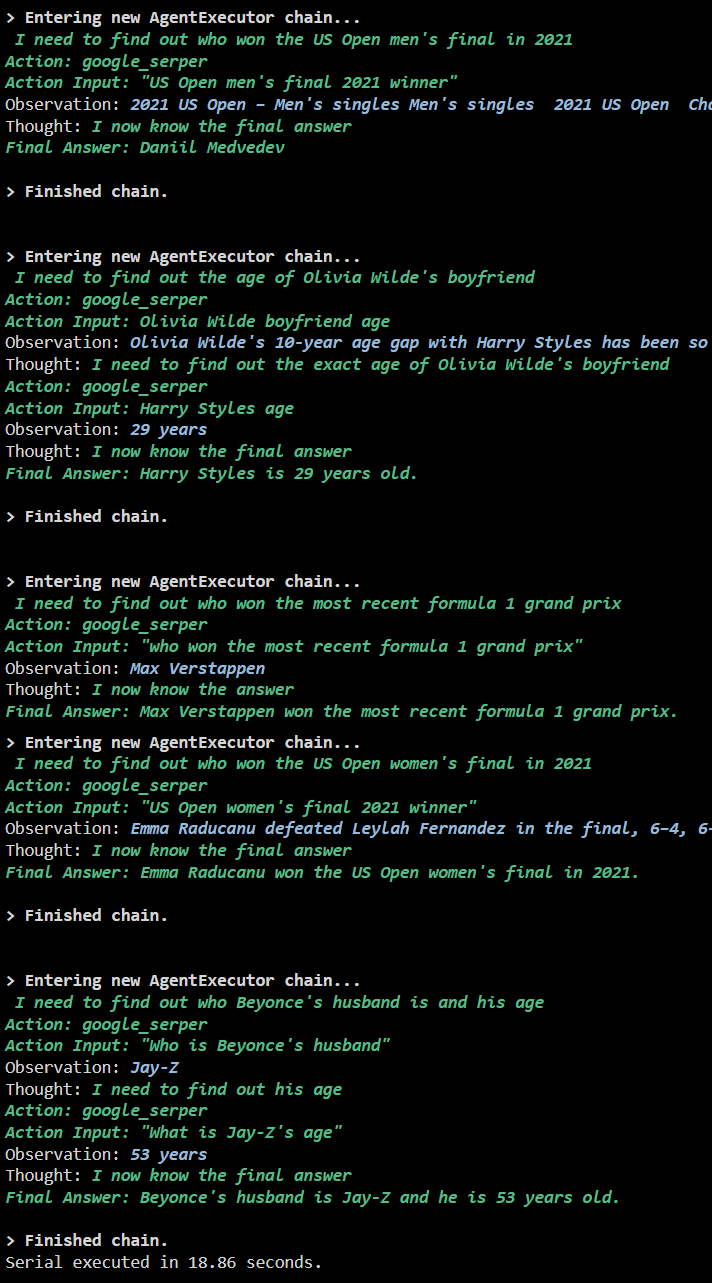
Výstup
Následující snímek obrazovky ukazuje, že každá otázka je zodpovězena v samostatném řetězci a po dokončení prvního řetězce se aktivuje druhý řetězec. Sériové provádění trvá déle, než získáte všechny odpovědi jednotlivě:
Metoda 2: Použití souběžného spouštění
Metoda souběžného provádění bere všechny otázky a dostává jejich odpovědi současně.
llm = OpenAI ( teplota = 0 )nástroje = load_tools ( [ 'google-header' , 'llm-matematika' ] , llm = llm )
#Konfigurace agenta pomocí výše uvedených nástrojů pro souběžné získávání odpovědí
činidlo = inicializovat_agenta (
nástroje , llm , činidlo = Typ agenta. ZERO_SHOT_REACT_DESCRIPTION , podrobný = Skutečný
)
#configuring time counter pro získání času použitého pro celý proces
s = čas . perf_counter ( )
úkoly = [ činidlo. choroba ( q ) pro q v otázky ]
čekat asyncio. shromáždit ( *úkoly )
Uplynulý = čas . perf_counter ( ) - s
#print celkový čas, který agent použil k získání odpovědí
tisk ( F 'Souběžně spuštěn za {elapsed:0,2f} sekund' )
Výstup
Souběžné provádění extrahuje všechna data současně a trvá mnohem méně času než sériové spuštění:
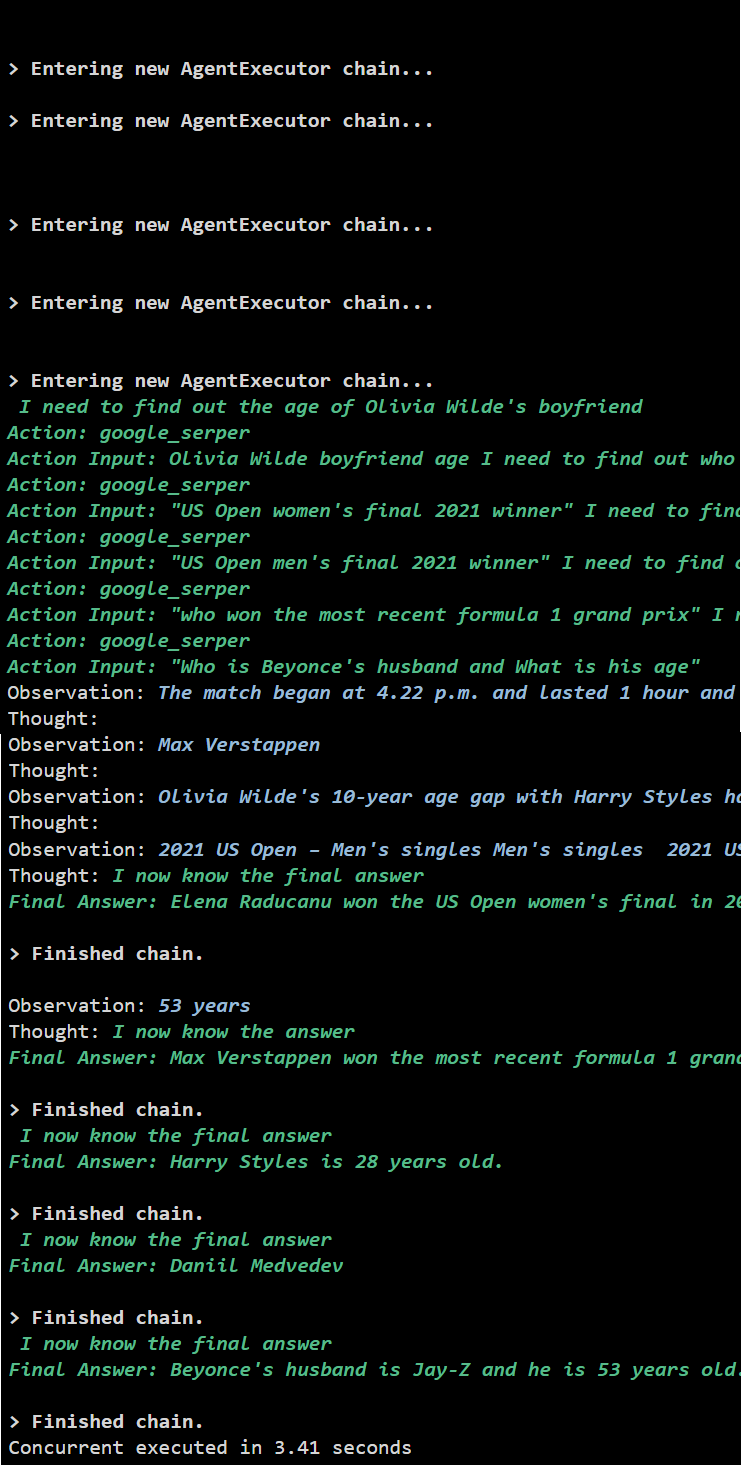
To je vše o použití agenta Async API v LangChain.
Závěr
Chcete-li použít agenta Async API v LangChain, jednoduše nainstalujte moduly pro import knihoven z jejich závislostí, abyste získali knihovnu asyncio. Poté nastavte prostředí pomocí klíčů OpenAI a Serper API přihlášením k jejich příslušným účtům. Nakonfigurujte sadu otázek souvisejících s různými tématy a spouštějte řetězce sériově a souběžně, abyste získali čas jejich provedení. Tato příručka podrobně popisuje proces použití agenta Async API v LangChain.