Tato příručka ilustruje proces používání shrnutí konverzace v LangChain.
Jak používat shrnutí konverzace v LangChain?
LangChain poskytuje knihovny jako ConversationSummaryMemory, které dokážou extrahovat kompletní shrnutí chatu nebo konverzace. Lze jej použít k získání hlavních informací konverzace, aniž byste museli číst všechny zprávy a text dostupný v chatu.
Chcete-li se naučit proces používání shrnutí konverzace v LangChain, jednoduše přejděte do následujících kroků:
Krok 1: Nainstalujte moduly
Nejprve nainstalujte rámec LangChain, abyste získali jeho závislosti nebo knihovny pomocí následujícího kódu:
pip install langchain
Nyní nainstalujte moduly OpenAI po instalaci LangChain pomocí příkazu pip:
pip install openai 
Po instalaci modulů jednoduše nastavit prostředí pomocí následujícího kódu po získání klíče API z účtu OpenAI:
import vyimport getpass
vy . přibližně [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Klíč OpenAI API:' )
Krok 2: Použití shrnutí konverzace
Dostaňte se do procesu používání shrnutí konverzace importem knihoven z LangChain:
z langchain. Paměť import Souhrn konverzacePaměť , ChatMessageHistoryz langchain. llms import OpenAI
Nakonfigurujte paměť modelu pomocí metod ConversationSummaryMemory() a OpenAI() a uložte do ní data:
Paměť = Souhrn konverzacePaměť ( llm = OpenAI ( teplota = 0 ) )Paměť. uložit_kontext ( { 'vstup' : 'Ahoj' } , { 'výstup' : 'Ahoj' } )
Spusťte paměť voláním load_memory_variables() způsob, jak extrahovat data z paměti:
Paměť. load_memory_variables ( { } ) 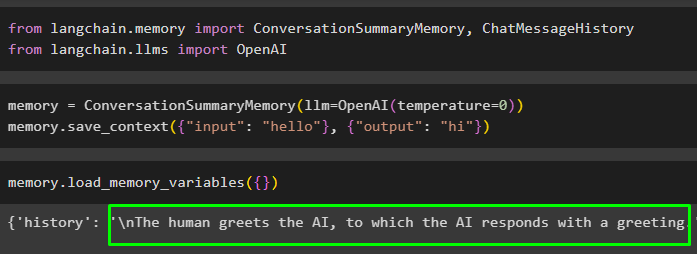
Uživatel může také získat data ve formě konverzace jako každá entita se samostatnou zprávou:
Paměť = Souhrn konverzacePaměť ( llm = OpenAI ( teplota = 0 ) , návratové_zprávy = Skutečný )Paměť. uložit_kontext ( { 'vstup' : 'Ahoj' } , { 'výstup' : 'Ahoj jak se máš' } )
Chcete-li získat zprávu AI a lidí odděleně, spusťte metodu load_memory_variables():
Paměť. load_memory_variables ( { } ) 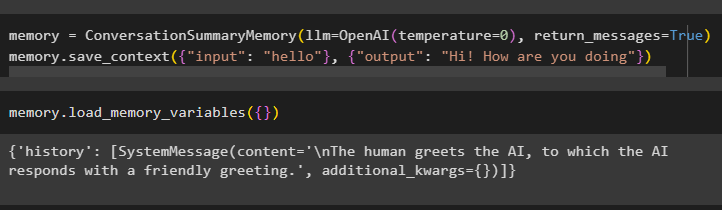
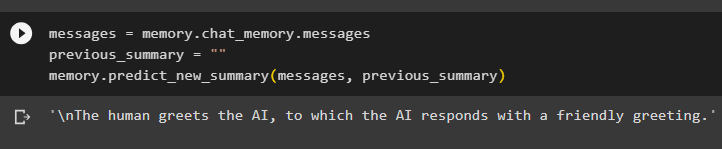
Uložte shrnutí konverzace do paměti a poté spusťte paměť, aby se na obrazovce zobrazil souhrn chatu/konverzace:
zprávy = Paměť. chat_memory . zprávypředchozí_shrnutí = ''
Paměť. předpovídat_nové_shrnutí ( zprávy , předchozí_shrnutí )
Krok 3: Použití souhrnu konverzace se stávajícími zprávami
Uživatel může také získat souhrn konverzace, která existuje mimo třídu nebo chat pomocí zprávy ChatMessageHistory(). Tyto zprávy lze přidat do paměti, aby bylo možné automaticky vygenerovat souhrn celé konverzace:
Dějiny = ChatMessageHistory ( )Dějiny. přidat_uživatelskou_zprávu ( 'Ahoj' )
Dějiny. add_ai_message ( 'Ahoj!' )
Sestavte model, jako je LLM, pomocí metody OpenAI() pro spouštění existujících zpráv v chat_memory proměnná:
Paměť = Souhrn konverzacePaměť. od_zpráv (llm = OpenAI ( teplota = 0 ) ,
chat_memory = Dějiny ,
návratové_zprávy = Skutečný
)
Spusťte paměť pomocí vyrovnávací paměti, abyste získali souhrn existujících zpráv:
Paměť. vyrovnávací paměť 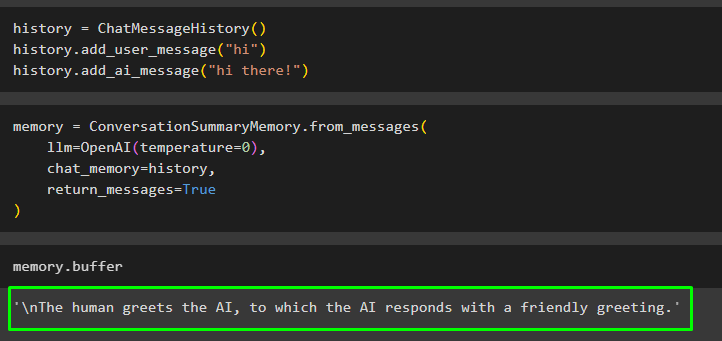
Spusťte následující kód pro sestavení LLM konfigurací vyrovnávací paměti pomocí zpráv chatu:
Paměť = Souhrn konverzacePaměť (llm = OpenAI ( teplota = 0 ) ,
vyrovnávací paměť = '''Člověk se ptá stroje na sebe
Systém odpovídá, že umělá inteligence je vytvořena pro dobro, protože může pomoci lidem dosáhnout jejich potenciálu''' ,
chat_memory = Dějiny ,
návratové_zprávy = Skutečný
)
Krok 4: Použití souhrnu konverzace v řetězci
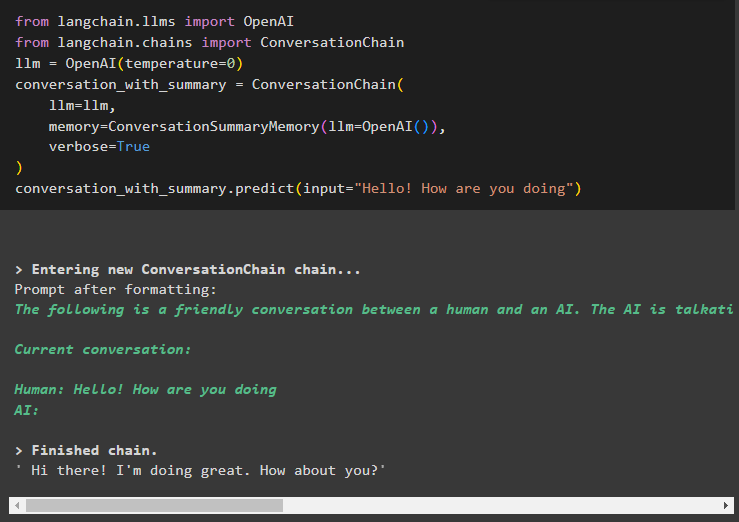
Další krok vysvětluje proces použití shrnutí konverzace v řetězci pomocí LLM:
z langchain. llms import OpenAIz langchain. řetězy import ConversationChain
llm = OpenAI ( teplota = 0 )
konverzace_se_souhrnem = ConversationChain (
llm = llm ,
Paměť = Souhrn konverzacePaměť ( llm = OpenAI ( ) ) ,
podrobný = Skutečný
)
konverzace_se_souhrnem. předpovědět ( vstup = 'Ahoj, jak se máš' )
Zde jsme začali budovat řetězce zahájením konverzace zdvořilým dotazem:
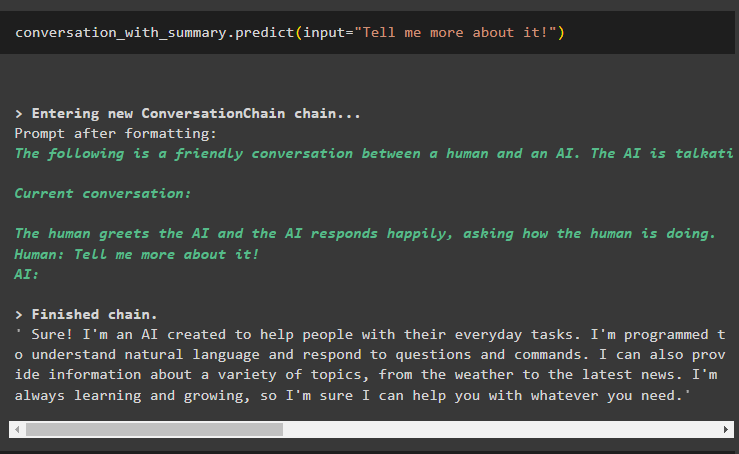
Nyní se zapojte do konverzace tím, že se zeptáte trochu více na poslední výstup, abyste jej rozšířili:
konverzace_se_souhrnem. předpovědět ( vstup = 'Řekni mi o tom víc!' )Model vysvětlil poslední zprávu podrobným úvodem do technologie AI nebo chatbota:
Extrahujte bod zájmu z předchozího výstupu a nasměrujte konverzaci konkrétním směrem:
konverzace_se_souhrnem. předpovědět ( vstup = 'Úžasné Jak dobrý je tento projekt?' )Zde dostáváme podrobné odpovědi od robota pomocí knihovny souhrnné paměti konverzace:
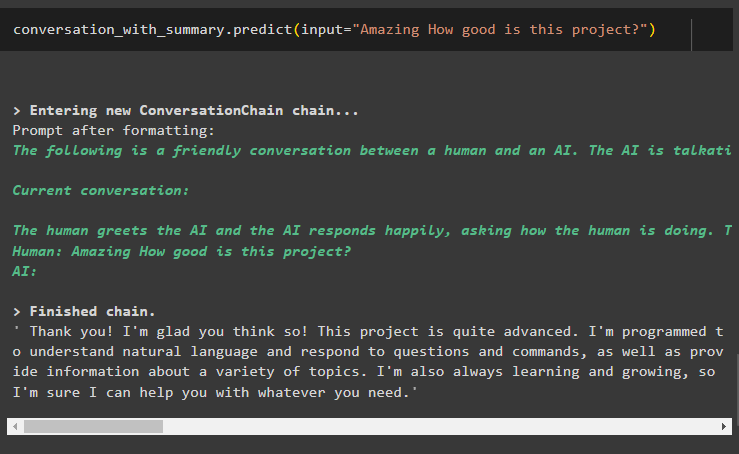
To je vše o použití shrnutí konverzace v LangChain.
Závěr
Chcete-li použít souhrnnou zprávu konverzace v LangChain, jednoduše nainstalujte moduly a rámce potřebné k nastavení prostředí. Jakmile je prostředí nastaveno, importujte soubor Souhrn konverzacePaměť knihovna pro vytváření LLM pomocí metody OpenAI(). Poté jednoduše použijte shrnutí konverzace k extrahování podrobného výstupu z modelů, což je shrnutí předchozí konverzace. Tato příručka podrobně popisuje proces používání paměti shrnutí konverzace pomocí modulu LangChain.