Tato příručka ilustruje proces načítání řetězů z LangChain Hub.
Jak přidat stav paměti v řetězci pomocí LangChain?
Stav paměti lze použít k inicializaci řetězců, protože může odkazovat na nedávnou hodnotu uloženou v řetězcích, která bude použita při vracení výstupu. Chcete-li se naučit proces přidávání stavu paměti v řetězcích pomocí rámce LangChain, jednoduše projděte tohoto snadného průvodce:
Krok 1: Nainstalujte moduly
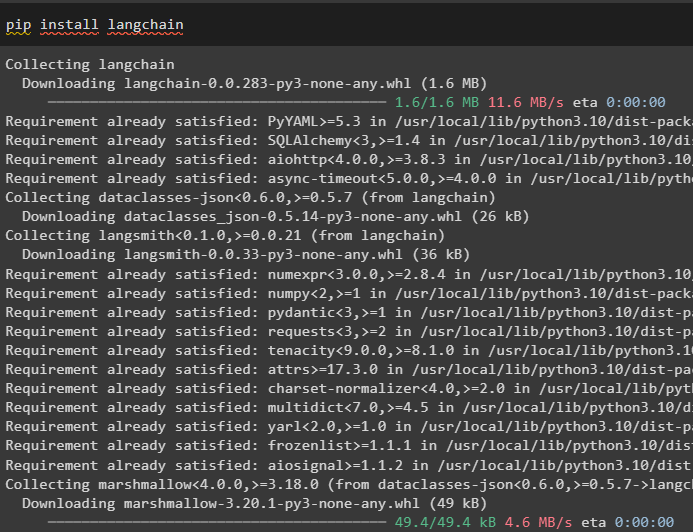
Nejprve se do procesu dostanete instalací rámce LangChain s jeho závislostmi pomocí příkazu pip:
pip install langchain
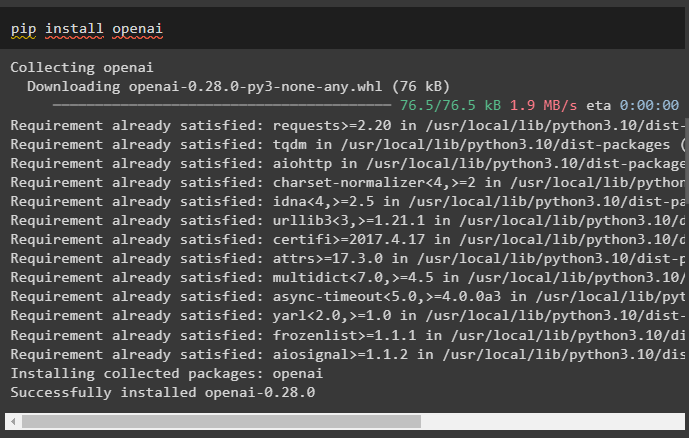
Nainstalujte také modul OpenAI, abyste získali jeho knihovny, které lze použít k přidání stavu paměti v řetězci:
pip install openai
Získejte klíč API z účtu OpenAI a nastavit prostředí pomocí toho, aby k němu měly řetězce přístup:
import vy
import getpass
vy . přibližně [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Klíč OpenAI API:' )
Tento krok je důležitý pro správnou funkci kódu.
Krok 2: Import knihoven
Po nastavení prostředí jednoduše importujte knihovny pro přidání stavu paměti, jako je LLMCain, ConversationBufferMemory a mnoho dalších:
z langchain. řetězy import ConversationChainz langchain. Paměť import ConversationBufferMemory
z langchain. chat_models import ChatOpenAI
z langchain. řetězy . llm import LLMCain
z langchain. vyzve import PromptTemplate
Krok 3: Budování řetězů
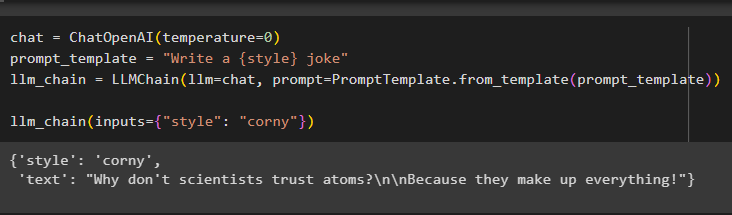
Nyní jednoduše vytvořte řetězce pro LLM pomocí metody OpenAI() a šablony výzvy pomocí dotazu k volání řetězce:
povídat si = ChatOpenAI ( teplota = 0 )prompt_template = 'Napiš {style} vtip'
llm_chain = LLMCain ( llm = povídat si , výzva = PromptTemplate. from_template ( prompt_template ) )
llm_chain ( vstupy = { 'styl' : 'ohraný' } )
Model zobrazil výstup pomocí modelu LLM, jak je zobrazeno na níže uvedeném snímku obrazovky:
Krok 4: Přidání stavu paměti
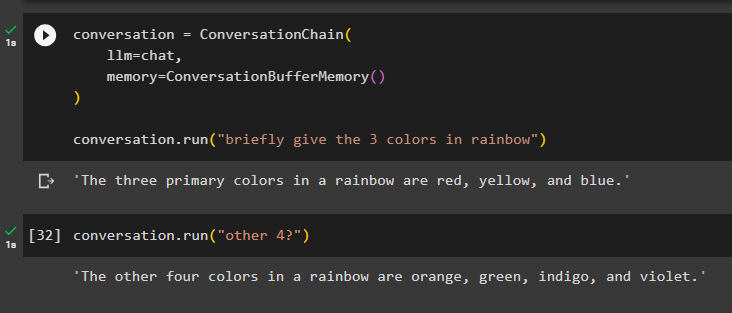
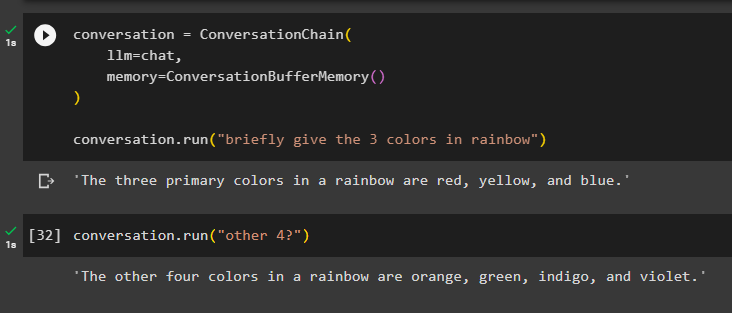
Zde přidáme stav paměti do řetězce pomocí metody ConversationBufferMemory() a spustíme řetězec, abychom získali 3 barvy z duhy:
konverzace = ConversationChain (llm = povídat si ,
Paměť = ConversationBufferMemory ( )
)
konverzace. běh ( 'stručně dejte 3 barvy duhy' )
Model zobrazuje pouze tři barvy duhy a kontext je uložen v paměti řetězu:
Zde spouštíme řetězec s nejednoznačným příkazem jako „ další 4? ” takže samotný model získá kontext z paměti a zobrazí zbývající barvy duhy:
konverzace. běh ( 'další 4?' )Model udělal přesně to, protože pochopil kontext a vrátil zbývající čtyři barvy ze sady duhy:
To je vše o načítání řetězců z LangChain Hub.
Závěr
Chcete-li přidat paměť v řetězcích pomocí frameworku LangChain, jednoduše nainstalujte moduly pro nastavení prostředí pro budování LLM. Poté importujte knihovny potřebné k sestavení řetězců v LLM a poté do nich přidejte stav paměti. Po přidání stavu paměti do řetězce jednoduše zadejte příkaz řetězci, aby získal výstup, a poté zadejte další příkaz v kontextu předchozího, abyste získali správnou odpověď. Tento příspěvek rozpracoval proces přidávání stavu paměti v řetězcích pomocí rámce LangChain.