Duplicitní data mohou často vést ke zmatkům, chybám a zkresleným informacím. Naštěstí nám Tabulky Google poskytují mnoho nástrojů a technik, které zjednodušují identifikaci a odstraňování těchto nadbytečných záznamů. Od základních porovnávání buněk až po pokročilé přístupy založené na vzorcích budete připraveni přeměnit nepřehledné listy na organizované cenné zdroje.
Ať už zpracováváte seznamy zákazníků, výsledky průzkumů nebo jakýkoli jiný soubor dat, odstranění duplicitních záznamů je základním krokem ke spolehlivé analýze a rozhodování.
V této příručce se ponoříme do dvou metod, které vám umožní identifikovat a odstranit duplicitní hodnoty.
Vytvoření tabulky
Nejprve jsme vytvořili tabulku v Tabulkách Google, která bude použita v příkladech dále v tomto článku. Tato tabulka má 3 sloupce: Sloupec A se záhlavím „Name“ ukládá názvy; Sloupec B má záhlaví „Věk“, které obsahuje věk lidí; a nakonec sloupec C, záhlaví „City“, obsahuje města. Pokud si všimneme, některé položky v této tabulce jsou duplicitní, například položky pro „John“ a „Sara“.
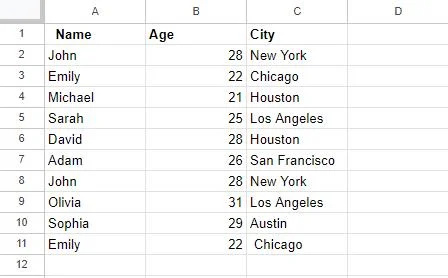
Budeme pracovat na této tabulce, abychom odstranili tyto duplicitní hodnoty různými metodami.
Metoda 1: Použití funkce „Odebrat duplikáty“ v Tabulkách Google
První metodou, kterou zde diskutujeme, je odstranění duplicitních hodnot pomocí funkce „Odstranit duplikáty“ v Tabulce Google. Tato metoda trvale odstraní duplicitní položky z vybraného rozsahu buněk.
Abychom tuto metodu demonstrovali, znovu uvážíme výše vygenerovanou tabulku.
Abychom mohli začít pracovat na této metodě, musíme nejprve vybrat celý rozsah obsahující naše data, včetně záhlaví. V tomto scénáři jsme vybrali buňky A1:C11 .
V horní části okna Tabulek Google uvidíte navigační panel s různými nabídkami. Najděte a klikněte na možnost „Data“ v navigační liště.
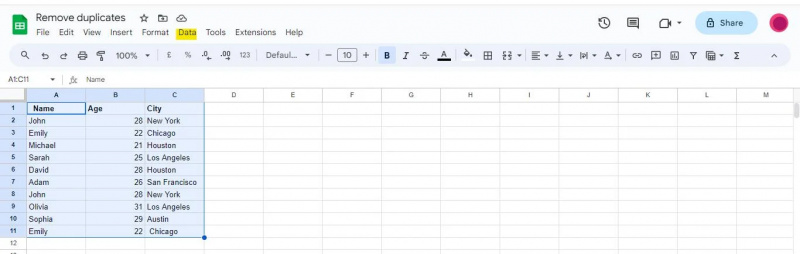
Po kliknutí na možnost „Data“ se zobrazí rozbalovací nabídka, která vám nabídne různé nástroje a funkce související s daty, které lze použít k analýze, čištění a manipulaci s vašimi daty.
V tomto příkladu budeme muset vstoupit do nabídky „Data“, abychom mohli přejít na možnost „Vyčištění dat“, která obsahuje funkci „Odstranit duplikáty“.
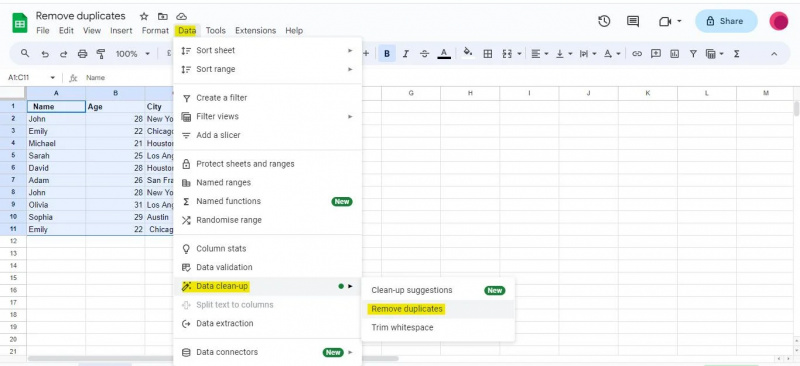
Poté, co vstoupíme do dialogového okna „Odstranit duplikáty“, zobrazí se nám seznam sloupců v naší datové sadě. Na základě těchto sloupců budou nalezeny a odstraněny duplikáty. V dialogovém okně označíme odpovídající zaškrtávací políčka podle toho, které sloupce chceme použít pro identifikaci duplikátů.
V našem příkladu máme tři sloupce: „Jméno“, „Věk“ a „Město“. Protože chceme identifikovat duplikáty na základě všech tří sloupců, zaškrtli jsme všechna tři zaškrtávací políčka. Kromě toho musíte zaškrtnout políčko „Data má řádek záhlaví“, pokud má tabulka záhlaví. Protože ve výše uvedené tabulce máme záhlaví, zaškrtli jsme políčko „Data mají řádek záhlaví“.
Jakmile vybereme sloupce k identifikaci duplikátů, můžeme přistoupit k odstranění těchto duplikátů z naší datové sady.
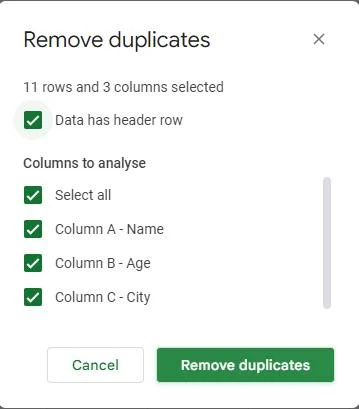
V dolní části dialogového okna „Odstranit duplikáty“ najdete tlačítko označené „Odstranit duplikáty“. Klikněte na toto tlačítko.
Po kliknutí na „Odstranit duplikáty“ zpracují Tabulky Google váš požadavek. Sloupce budou prohledány a všechny řádky s duplicitními hodnotami v těchto sloupcích budou odstraněny, čímž se úspěšně odstraní duplicitní položky.
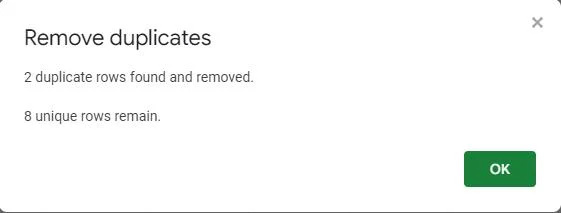
Vyskakovací okno potvrdí, že duplicitní hodnoty byly odstraněny z tabulky. Ukazuje, že byly nalezeny a odstraněny dva duplicitní řádky, takže v tabulce zůstalo osm jedinečných položek.
Po použití funkce „Odstranit duplikáty“ se naše tabulka aktualizuje následovně:
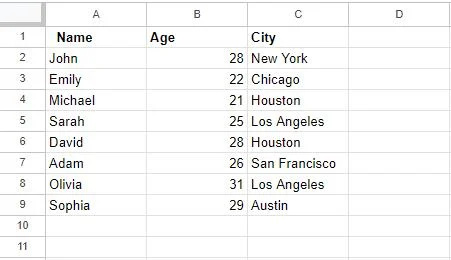
Zde je důležité vzít v úvahu, že odstranění duplikátů pomocí této funkce je trvalou akcí. Duplicitní řádky budou smazány z vaší datové sady a tuto akci nebudete moci vrátit zpět, pokud nemáte zálohu dat. Ujistěte se tedy, že jste vybrali správné sloupce k nalezení duplikátů tím, že svůj výběr znovu zkontrolujete.
Metoda 2: Použití funkce UNIQUE k odebrání duplicit
Druhá metoda, kterou zde probereme, je použití UNIKÁTNÍ funkce v Tabulkách Google. The UNIKÁTNÍ Funkce načte odlišné hodnoty ze zadaného rozsahu nebo sloupce dat. I když přímo neodstraňuje duplikáty z původních dat, vytváří seznam jedinečných hodnot, které můžete použít pro transformaci nebo analýzu dat bez duplikátů.
Vytvořme příklad pro pochopení této metody.
Použijeme tabulku, která byla vygenerována v úvodní části tohoto tutoriálu. Jak již víme, tabulka obsahuje určitá data, která jsou duplicitní. Vybrali jsme tedy buňku „E2“ k zápisu UNIKÁTNÍ vzorec do. Vzorec, který jsme napsali, je následující:
= UNIQUE(A2:A11)
Při použití v Tabulkách Google vzorec UNIQUE načítá jedinečné hodnoty v samostatném sloupci. Tento vzorec jsme tedy poskytli s rozsahem od buňky A2 na A11 , který bude použit ve sloupci A. Tento vzorec tedy extrahuje jedinečné hodnoty ze sloupce A a zobrazí je ve sloupci, kde byl zapsán vzorec.
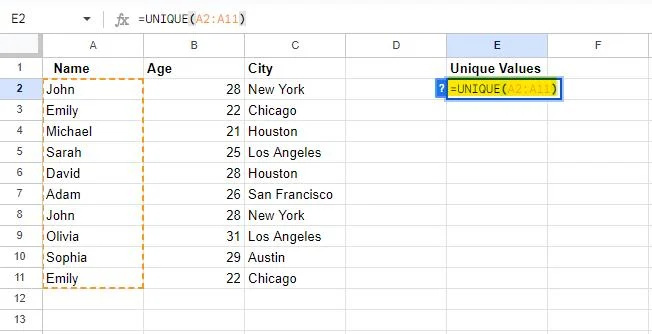
Vzorec bude aplikován na určený rozsah, když stisknete klávesu Enter.
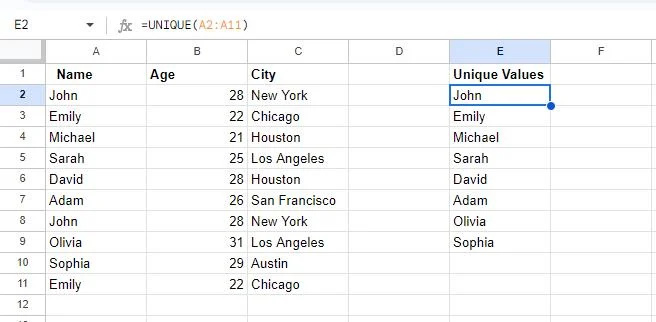
Na tomto snímku vidíme, že dvě buňky jsou prázdné. Je to proto, že v tabulce byly duplikovány dvě hodnoty, a to John a Emily. The UNIKÁTNÍ zobrazí pouze jednu instanci každé hodnoty.
Tato metoda neodstranila duplicitní hodnoty přímo ze zadaného sloupce, ale vytvořila jiný sloupec, který nám poskytne jedinečné položky tohoto sloupce, čímž se odstraní duplikáty.
Závěr
Odstranění duplikátů v Tabulkách Google je užitečná metoda pro analýzu dat. Tato příručka demonstrovala dvě metody, které vám umožní snadno odstranit duplicitní položky z vašich dat. První metoda vysvětlila použití Tabulek Google k odstranění duplicitní funkce. Tato metoda skenuje zadaný rozsah buněk a eliminuje duplikáty. Další metodou, kterou jsme diskutovali, je použití vzorce pro získání duplicitních hodnot. Přestože duplikáty přímo neodstraňuje z rozsahu, místo toho zobrazuje jedinečné hodnoty v novém sloupci.