„V „pandách“ můžeme snadno přečíst textový soubor pomocí metody „pandy“. „Pandy“ nám poskytují možnost číst textový soubor. „Pandas“ poskytuje různé vestavěné metody pro čtení textového souboru. V tomto tutoriálu probereme všechny metody spolu se všemi parametry a podrobně je vysvětlíme. Také budeme číst textový soubor v „pandách“ pomocí metod „pandas“ v našich kódech zde.
Metody pro čtení textového souboru v „pandách“
V „pandách“ máme tři metody, které nám pomáhají při čtení textového souboru. Udělali jsme zde také několik příkladů, ve kterých čteme textový soubor. Metody, které „pandy“ poskytují, jsou popsány níže:
-
- Použitím metody pd.read_csv() .
- Použitím metody pd.read_table() .
- Použitím metody pd.read_fwf() .
Nyní vysvětlujeme syntaxi všech těchto metod a také podrobně diskutujeme o parametrech všech metod v tomto tutoriálu.
Syntaxe read_csv()
pd.read_csv ( 'název_souboru.txt', září =' ', záhlaví = Žádné, jména = [ “Col_name1”, “Col_name2, “Col_name2”, ………….. ] )
V této metodě nejprve přidáme název textového souboru, jehož data chceme číst, a je to první parametr této metody. Potom umístíme „sep“, což je oddělovač v této metodě, a jako znak zde umístíme mezeru, takže bude mezeru považovat za oddělovač. Poté máme parametr header a použije se hodnota „None“ tohoto parametru, takže vytvoří výchozí záhlaví, a pokud tento parametr nepřidáme, bude uvažovat první řádek textového souboru jako záhlaví. V parametru „names“ můžeme přidat názvy sloupců, které musíme přidat jako záhlaví.
Syntaxe read_table()
pd.read_table ( 'název_souboru.txt' , oddělovač = ' ' )
V této metodě uvedeme jako první parametr název textového souboru. Když do oddělovače umístíme „ “, pak bude jako oddělovač použit znak mezery.
Syntaxe read_fwf()
pd.read_fwf ( 'název_souboru.txt' )
Tato metoda přebírá pouze jeden parametr, kterým je název textového souboru.
Nyní použijeme tyto metody pro čtení textových souborů v kódech „pandy“ a zobrazení dat textového souboru na terminálu.
Příklad #01
Zde je aplikace „Spyder“, ve které jsme provedli všechny tyto kódy, které jsou uvedeny v tomto tutoriálu. Textový soubor, jehož data chceme číst, je zobrazen níže. Pro čtení tohoto textového souboru v „pandách“ použijeme metodu „read_csv()“.
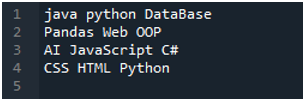
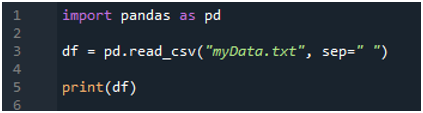
Nejprve importujeme knihovnu „pandy“, protože chceme použít metodu „read_csv()“, a je to metoda „pandy“. K této metodě přistupujeme pouze tehdy, když jsme importovali knihovnu „pand“. Zde zmiňujeme „pandy jako pd“, takže toto „pd“ je umístěno s názvem metody pro jeho použití. Poté zde vytvoříme proměnnou „df“, která slouží k uložení dat textového souboru po přečtení. Zde umístíme metodu „pd.read_csv()“, která pomáhá při čtení textového souboru a převodu dat textového souboru do DataFrame a jejich uložení do proměnné „df“.
Zde jsme předali název souboru, který je „myData.txt“, a poté použijeme „sep“ a tomuto „sep“ přiřadíme prázdný znak. Tento prázdný znak tedy funguje jako oddělovač v textovém souboru. Poté jsme použili níže uvedenou „print()“, která se používá pro tisk dat textového souboru. Zobrazí data textového souboru ve formuláři DataFrame.
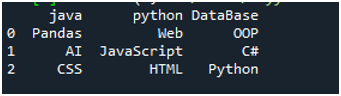
Pro provedení tohoto kódu musíme stisknout „Shift+Enter“ a výstup se vykreslí na terminálu „Spyder“. Výsledek výše uvedeného kódu je zobrazen na daném snímku obrazovky a můžete vidět, že data textového souboru jsou zobrazena jako DataFrame a první řádek našeho textového souboru je zde prezentován jako názvy sloupců tohoto DataFrame. Také odděluje data, kde je v textovém souboru přítomen znak mezery.
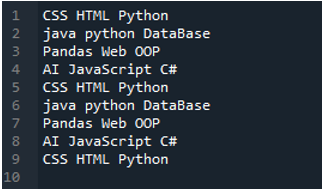
Příklad #02
Zde je ukázán textový soubor, který budeme číst v tomto příkladu, a opět použijeme metodu „read_csv()“, ale s jinými parametry.
Používá se metoda „pandy“ „pd.read_csv()“ a zde předáváme tři parametry. Nejprve umístíme název souboru, což je „Record.txt“. Druhý parametr je parametr „sep“ a přiřadí mu prázdný znak, a pak máme třetí parametr, ve kterém nastavíme „header“ a upravíme ho na „None“, takže vytvoří výchozí záhlaví DataFrame. když tento kód spustíme. To vše jsme uložili do proměnné “My_Record” a pro tisk přidali i “My_Record” do funkce “print()”.

Všechna data jsou uložena v DataFrame a odděluje data tam, kde je v datech textového souboru přítomen znak mezery. Také zde vytvořila výchozí záhlaví DataFrame, protože jsme upravili parametr „header“ na „None“.
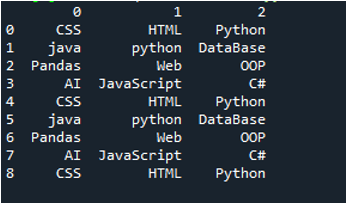
Příklad #03
Zobrazí se textový soubor tohoto příkladu a znovu použijeme metodu „read_csv()“ s upravenými parametry.
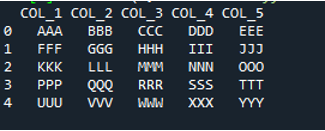
V tomto kódu jsou zde čtyři parametry předány metodě „pandy“ „pd.read_csv()“. Název textového souboru je prvním parametrem. Parametr „sep“ má ve druhém parametru prázdný znak. Parametr „header“ je ve třetím argumentu nastaven na „None“ a jako čtvrtý parametr jsme nastavili „names“, které se objeví jako názvy sloupců DataFrame po přečtení textového souboru, a tyto názvy sloupců jsou „COL_1, COL_2, COL_3, COL_4 a COL_5“. Všechny tyto informace byly uloženy do proměnné „My_Record“ a „My_Record“ byl také přidán do metody „print()“, takže se vytiskne na terminálu.

Všechny informace textového souboru jsou zde vykresleny jako DataFrame a také odděluje data, do kterých jsou v textovém souboru přidány mezery. Podle toho také přidá názvy sloupců, které jsme přidali výše v kódu.
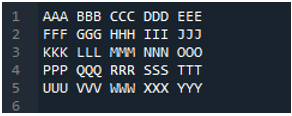
Příklad #04
Toto je textový soubor, který v tomto příkladu přečteme pomocí jiné metody, metody „pd.read_table()“.
Zde je přidána metoda „pd.read_table()“ pro čtení textového souboru a přidáme „ABC.txt“, což je název textového souboru. Tato metoda pomáhá při čtení textového souboru a také jsme upravili parametr „oddělovač“ na znak mezery, takže bude fungovat také jako oddělovač, který jsme vysvětlili výše. Poté se všechna data textového souboru uloží do proměnné „My_Data“ a zde se také vytisknou.

Počáteční řádek našeho textového souboru je zde zobrazen jako názvy sloupců DataFrame a data textového souboru jsou vytištěna jako DataFrame. Navíc odděluje data textového souboru, kde je v něm přítomen znak mezery.
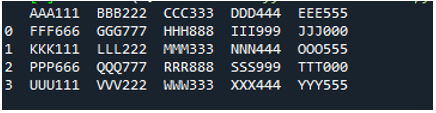
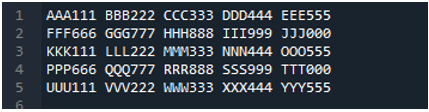
Příklad #05
Nyní textový soubor obsahuje data, která jsou zobrazena níže. Tentokrát použijeme „read_fwf()“ a ukážeme, jak vykresluje data po přečtení textového souboru.
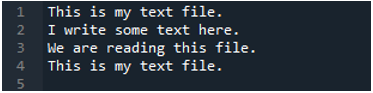
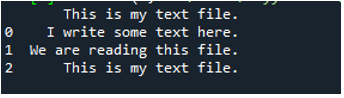
Jak víme, tato metoda „read_fwf()“ bere pouze jeden parametr, což je název souboru, který chceme číst. Zde přidáme „textfile.txt“, což je název našeho textového souboru a tuto metodu pandas přiřadíme do proměnné „File_Data“, která bude ukládat data tohoto textového souboru. Poté zadáme „print(File_Data)“, takže tato data také vytiskne.

Zde jsou zobrazena všechna data textového souboru. Neoddělila data, kde jsou přítomny mezery, protože v této funkci není žádný parametr jako „Sep“ nebo „oddělovač“.
Závěr
Tento tutoriál vysvětluje, jak číst textový soubor v „pandách“ a jaké metody se používají pro čtení textového souboru v „pandách“. Probrali jsme všechny metody, které nám pomáhají při čtení textového souboru v „pandách“. V tomto tutoriálu jsme prozkoumali tři různé metody „pandy“ pro čtení našich textových souborů v „pandách“. Také jsme zde podrobně vysvětlili syntaxi všech metod a také parametry všech metod a přečetli jsme mnoho textových souborů použitím různých metod se všemi možnými parametry v tomto tutoriálu.