Porovnání dat v SQL je běžný úkol, se kterým se občas setká každý vývojář databází. Naštěstí porovnání dat přichází v široké škále formátů, jako je doslovné srovnání, booleovské srovnání atd.
Jedním z reálných scénářů porovnávání dat, se kterými se můžete setkat, je porovnávání dvou tabulek. Hraje zásadní roli v úkolech, jako je ověřování dat, identifikace chyb, duplikace nebo zajištění integrity dat.
V tomto tutoriálu prozkoumáme všechny různé metody a techniky, které můžeme použít k porovnání dvou databázových tabulek v SQL.
Ukázkové nastavení dat
Než se ponoříme do každé z metod, nastavíme základní nastavení dat pro demonstrační účely.
Máme dvě tabulky s ukázkovými daty, jak je uvedeno v příkladu.
Ukázková tabulka 1:
Následující text obsahuje dotazy pro vytvoření první tabulky a vložení ukázkových dat do tabulky:
CREATE TABLE sample_tb1 (
zamestnanec_id INT PRIMARY KEY AUTO_INCREMENT,
jméno VARCHAR ( padesáti ) ,
příjmení VARCHAR ( padesáti ) ,
oddělení VARCHAR ( padesáti ) ,
plat DESETINNÝ ( 10 , 2 )
) ;
INSERT INTO sample_tb1 ( jméno, příjmení, oddělení, plat )
HODNOTY
( 'Penelope' , 'Honit' , 'HR' , 55 000,00 ) ,
( 'Matthew' , 'Klec' , 'TO' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finance' , 50 000,00 ) ,
( 'Kirsten' , 'fawcet' , 'TO' , 62 000,00 ) ,
( 'Cameron' , 'costner' , 'Finance' , 48 000,00 ) ;
To by mělo vytvořit novou tabulku s názvem „sample_tb1“ s různými informacemi, jako jsou jména, oddělení a plat.
Výsledná tabulka je následující:

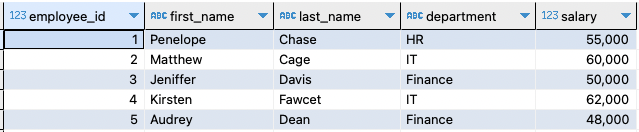
Ukázková tabulka 2:
Pokračujme a vytvořte dvě vzorové tabulky. Předpokládejme, že se jedná o záložní kopii první tabulky. Můžeme vytvořit tabulku a vložit ukázková data, jak je znázorněno v následujícím:
CREATE TABLE sample_tb2 (zamestnanec_id INT PRIMARY KEY AUTO_INCREMENT,
jméno VARCHAR ( padesáti ) ,
příjmení VARCHAR ( padesáti ) ,
oddělení VARCHAR ( padesáti ) ,
plat DESETINNÝ ( 10 , 2 )
) ;
INSERT INTO sample_tb2 ( jméno, příjmení, oddělení, plat )
HODNOTY
( 'Penelope' , 'Honit' , 'HR' , 55 000,00 ) ,
( 'Matthew' , 'Klec' , 'TO' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finance' , 50 000,00 ) ,
( 'Kirsten' , 'fawcet' , 'TO' , 62 000,00 ) ,
( 'Audrey' , 'Děkan' , 'Finance' , 48 000,00 ) ;
To by mělo vytvořit tabulku a vložit ukázková data, jak je uvedeno v předchozím dotazu. Výsledná tabulka je následující:
Porovnejte dvě tabulky pomocí Except
Jedním z nejběžnějších způsobů porovnání dvou tabulek v SQL je použití operátoru EXCEPT. To najde řádky, které existují v první tabulce, ale ne ve druhé tabulce.
Můžeme jej použít k porovnání s ukázkovými tabulkami takto:
VYBRAT *FROM sample_tb1
AŽ NA
VYBRAT *
FROM sample_tb2;
V tomto příkladu operátor EXCEPT vrátí všechny odlišné řádky z prvního dotazu (sample_tb1), které se neobjeví ve druhém dotazu (sample_tb2).
Porovnejte dvě tabulky pomocí Union
Druhou metodou, kterou můžeme použít, je operátor UNION ve spojení s klauzulí GROUP BY. To pomáhá identifikovat záznamy, které existují v jedné tabulce, nikoli v druhé, při zachování duplicitních záznamů.
Vezměte dotaz, který je znázorněn v následujícím:
VYBRATzaměstnanec_id,
jméno,
příjmení,
oddělení,
plat
Z
(
VYBRAT
zaměstnanec_id,
jméno,
příjmení,
oddělení,
plat
Z
sample_tb1
UNION VŠECHNY
VYBRAT
zaměstnanec_id,
jméno,
příjmení,
oddělení,
plat
Z
sample_tb2
) AS kombinovaná_data
SKUPINA VYTVOŘENÁ
zaměstnanec_id,
jméno,
příjmení,
oddělení,
plat
MÍT
POČET ( * ) = 1 ;
V uvedeném příkladu používáme operátor UNION ALL ke spojení dat z obou tabulek při zachování duplicit.
Potom použijeme klauzuli GROUP BY k seskupení kombinovaných dat podle všech sloupců. Nakonec použijeme klauzuli HAVING, abychom zajistili, že budou vybrány pouze záznamy s počtem jedna (žádné duplikáty).
Výstup:

Tato metoda je trochu složitější, ale poskytuje mnohem lepší přehled, protože získáte skutečná data, která v obou tabulkách chybí.
Porovnejte dva stoly pomocí INNER JOIN
Pokud jste přemýšleli, proč nepoužít INNER JOIN? Byli byste na místě. K porovnání tabulek a nalezení společných záznamů můžeme použít INNER JOIN.
Vezměte si například následující dotaz:
VYBRATsample_tb1. *
Z
sample_tb1
INNER JOIN sample_tb2 ON
sample_tb1.employee_id = sample_tb2.employee_id;
V tomto příkladu používáme SQL INNER JOIN k nalezení záznamů, které existují v obou tabulkách na základě daného sloupce. Ačkoli to funguje, může to být někdy zavádějící, protože si nejste jisti, zda data skutečně chybí nebo jsou přítomna v obou tabulkách nebo pouze v jedné.
Závěr
V tomto tutoriálu jsme se dozvěděli o všech metodách a technikách, které můžeme použít k porovnání dvou tabulek v SQL.