Jako správci databází musíme být posedlí nástroji a metodami zvyšování výkonu databáze.
V PostgreSQL máme přístup k příkazu EXPLAIN ANALYZE, který nám umožňuje analyzovat plán provádění a výkon daného databázového dotazu. Příkaz vrací podrobné informace o tom, jak databázový stroj zpracovává dotaz. To zahrnuje posloupnost provedených operací, odhadované náklady na dotazy, načasování provádění a další.
Tyto informace pak můžeme použít k identifikaci databázových dotazů a také k identifikaci a opravě potenciálních úzkých míst výkonu.
Tento výukový program popisuje, jak použít příkaz EXPLAIN ANALYZE v PostgreSQL k zobrazení a optimalizaci výkonu dotazu.
PostgreSQL EXPLAIN ANALYZE
Příkaz je docela přímočarý. Nejprve musíme na začátek dotazu, který chceme analyzovat, přidat příkaz EXPLAIN ANALYZE.
Syntaxe příkazu je následující:
EXPLAIN ANALYZEJakmile příkaz spustíte, PostgreSQL vrátí podrobný výstup o poskytnutém dotazu.
Vysvětlení výstupu dotazu EXPLAIN ANALYZE
Jak již bylo zmíněno, jakmile spustíme příkaz EXPLAIN ANALYZE, PostgreSQL vygeneruje podrobnou zprávu o plánu dotazů a statistiky provádění.
Výstup se skládá ze sady sloupců, které obsahují užitečné informace. Výsledné sloupce jsou znázorněny s příslušným významem:
PLÁN DOTAZŮ – Tento sloupec zobrazuje plán provádění zadaného dotazu. Plán provádění odkazuje na posloupnost operací, které databázový stroj provádí k úspěšnému dokončení dotazu.
PLÁN – Druhý sloupec je sloupec PLAN. Obsahuje textovou reprezentaci každé operace nebo kroku v prováděcím plánu. Opět je každá operace odsazena, aby indikovala hierarchii operací.
CELKOVÉ NÁKLADY – Sloupec celkových nákladů představuje odhadované celkové náklady na dotaz. Náklady se týkají relativní míry, kterou plánovač databázových dotazů používá k určení optimálního plánu provádění.
AKTUÁLNÍ ŘÁDKY – Tento sloupec zobrazuje přesný počet řádků, které jsou zpracovány v každém kroku provádění dotazu.
AKTUÁLNÍ ČAS – Tento sloupec zobrazuje skutečný čas potřebný pro každou operaci, který zahrnuje jak dobu provedení operace, tak čas strávený na zdrojích.
ČAS PLÁNOVÁNÍ – Tento sloupec zobrazuje čas, který plánovač dotazů potřebuje k vygenerování plánu provádění. To zahrnuje celkový čas optimalizace dotazu a generování plánu.
DOBA PROVEDENÍ – Tento sloupec zobrazuje celkový čas na provedení dotazu. To také zahrnuje čas strávený plánováním a dobou provádění dotazu.
PostgreSQL EXPLAIN ANALYZE Příklad
Podívejme se na některé základní příklady použití příkazu EXPLAIN ANALYZE.
Příklad 1: Vyberte příkaz
Použijme příkaz EXPLAIN ANALYZE k ukázce provádění jednoduchého příkazu select v PostgreSQL.
Jakmile spustíme předchozí příkaz, měli bychom získat výstup takto:
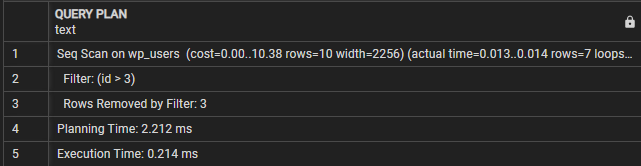
PLÁN DOTAZŮ-------------------------------------------------- ------------------
Seq Scan on wp_users (cena=0,00..10,38 řádků=10 šířka=2256) (skutečný čas=0,009..0,010 řádků=7 smyček=1)
Filtr: (id > 3)
Řádky odstraněné filtrem: 3
Plánovací čas: 0,995 ms
Doba provedení: 0,021 ms
(5 řádků)
V tomto případě můžeme vidět, že sekce Query plan označuje, že dotaz provádí sekvenční skenování tabulky wp_users. Řádek filtru označuje podmínku, která se používá k filtrování výsledných řádků.
Poté uvidíme „Řádky odstraněné filtrem“, které ukazuje počet řádků, které byly odstraněny podmínkou filtru.
Nakonec doba provádění ukazuje celkovou dobu provádění dotazu. V tomto případě dotaz trvá 0,021 ms.
Příklad 2: Analýza spojení
Vezměme si složitější dotaz, který zahrnuje spojení SQL. K tomu používáme vzorovou databázi Pagila. Vzorovou databázi si můžete stáhnout a nainstalovat na svůj počítač pro účely demonstrace.
Můžeme spustit jednoduché spojení, jak je znázorněno v následujícím:
vysvětlit analyzovat SELECT titul, jménoZ filmu f
PŘIPOJTE SE k filmové_kategorii fc ON f.film_id = fc.film_id
JOIN kategorie c ON fc.category_id = c.category_id;
Jakmile spustíme daný dotaz, měli bychom vidět výstup takto:
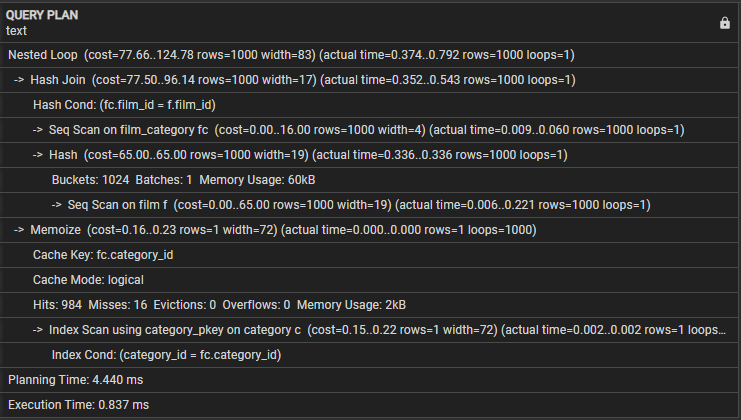
Pojďme prozkoumat následující plán dotazů:
- Vnořená smyčka – označuje, že spojení používá strategii spojení vnořené smyčky.
- Hash Join – Tato operace spojuje film_category a filmové tabulky pomocí algoritmu Hash join. Tato operace stojí 77,50 a odhaduje se na 1000 řádků. Skutečný čas potřebný pro tuto operaci je však 0,254 až 0,439 milisekundy a načte 1000 řádků.
- Hash Cond – Označuje, že podmínka spojení používá spojení Hash, aby odpovídala sloupcům film_id a sloupcům film_category v tabulkách filmu.
- Seq Scan on film_category – Tato operace provede sekvenční skenování v tabulce film_category s cenou 16,00 a odhadem 1000 řádků. Skutečná doba potřebná pro tuto operaci je 0,008 až 0,056 milisekundy a načte 1000 řádků.
- Seq Scan on film – Dotaz provede sekvenční skenování na filmové tabulce s výslednými odhadovanými a skutečnými náklady a řádky v této operaci.
- Memoize – Tato operace ukládá do mezipaměti výsledky spojení mezi film_category a filmovými tabulkami pro následné použití.
- Klíč mezipaměti – Označuje, že klíč mezipaměti, který se používá k zapamatování, je založen na sloupci category_id z film_category.
- Režim mezipaměti – Označuje, že dotaz používá režim logické mezipaměti.
- Zásahy, Chyby, Vystěhování, Přetečení – Tři řádky poskytují statistiky o vyrovnávací paměti, počtu zásahů, vynechání, vystěhování a přetečení během provádění. Tento blok také zahrnuje využití paměti během provádění dotazu.
- Skenování indexu pomocí category_pkey – Zde je uvedena operace, která provádí skenování indexu v tabulce kategorií pomocí indexu primárního klíče.
- Index Cond – Ukazuje, že skenování indexu je založeno na podmínce, která odpovídá sloupci category_id v tabulce kategorií.
- Planning Time – Tento řádek zobrazuje čas potřebný k plánování dotazu, což je 3,005 milisekund.
- Doba provedení – Tento řádek nakonec ukazuje celkovou dobu provedení dotazu, která je 0,745 milisekundy.
Tady to máš! Podrobné informace o provedení jednoduchého spojení v PostgreSQL.
Závěr
Objevili jste sílu a použití příkazu EXPLAIN ANALYZE v PostgreSQL. Příkaz EXPLAIN ANALYZE je výkonný nástroj pro analýzu a optimalizaci dotazů. Tento nástroj použijte k vytváření efektivních a méně náročných dotazů.