Data jsou denně shromažďována v obrovském množství a správa velkých dat je nejdůležitějším případem použití nástroje Elasticsearch. Data jsou ukládána do analytické databáze v reálném čase a uživateli je umožněno extrahovat data, aby z nich pomocí dotazů našel užitečné znalosti. Uživatel může použít dotazy k vyhledání dat z více indexů a jejich zobrazení v jednom segmentu z relační databáze.
Tato příručka vysvětlí agregace Elasticsearch s příklady použití různých agregací.
Co je agregace Elasticsearch?
V Elasticsearch je agregace proces kombinování nebo seskupování polí za účelem extrahování informací z relační databáze. Agregaci v Elasticsearch lze považovat za SKUPINA PODLE klauzule nebo AGREGÁT() funkce v jazyce SQL.
Jak používat agregaci Elasticsearch?
Aby uživatel mohl používat agregaci v Elasticsearch, musí mít základní znalosti o své databázi. Podívejme se na syntaxi a její praktickou implementaci:
Syntax
Chcete-li najít data z databáze, syntaxe agregace v nástroji Elasticsearch, jak je uvedeno níže:
'aggs' : {'name_of_agregation' : {
'type_of_agregation' : {
'pole' : 'název_pole_dokumentu'
}
Výše uvedené úryvky:
-
- Používá se „ aggs ” klíčové slovo, které vysvětluje použití agregace v dotazu.
- The název_agregace je nastaven uživatelem podle požadovaných informací.
- Poté, typ_agregace slouží k získávání dat.
- Poslední řádek používá pole klíčové slovo, za kterým následuje název atributu z dokumentu.
Příklad 1: Agregace ve vzorových datech Kibana
Tato část vysvětluje agregaci pomocí příkladu s použitím ukázkových dat z Kibana tak, že se k ní nejprve připojíte. Poté jednoduše zamiřte dovnitř „ Vývojářské nástroje ” vyhledáním z vyhledávacího pole a kliknutím na něj:
Načtení dat z ukázkových dat
Jednoduše použijte následující příkaz k načtení dat z „ kibana_sample_data_logs ” index na konzole Dev Tools:
DOSTAT / kibana_sample_data_logs / _Vyhledávání
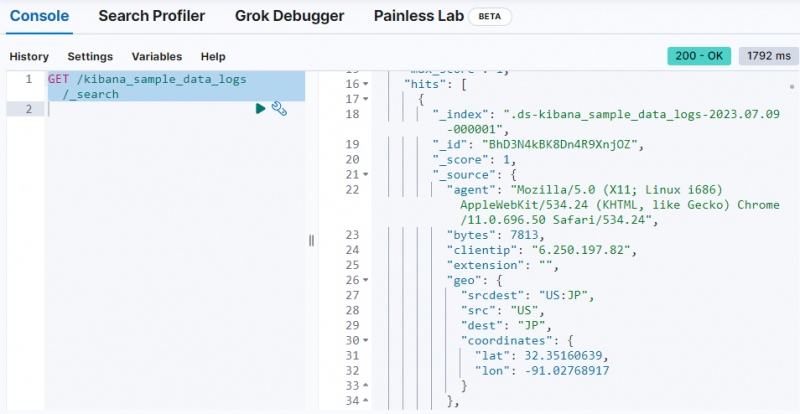
Výstup ukazuje, že data byla načtena z „ kibana_sample_data_logs 'index.'
Následující kód používá a DOSTAT žádost na ' kibana_sample_data_log “ a vyhledávat z něj pomocí agregace value_count na „ klientip pole:
DOSTAT / kibana_sample_data_logs / _Vyhledávání{ 'velikost' : 0 ,
'aggs' : {
'ip_count' : {
'value_count' : {
'pole' : 'klientský tip'
}
}
}
}
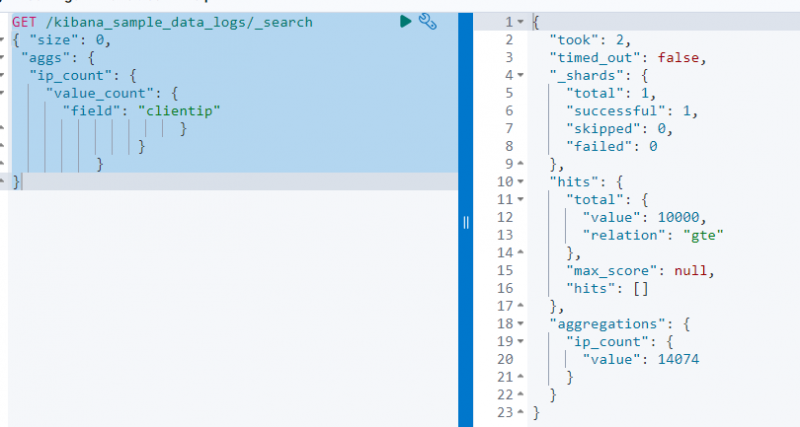
Výše uvedený snímek obrazovky zobrazuje agregaci na klientip pole s hodnotou 14074 .
Důležité agregace
Některé z důležitých agregací, které se používají k efektivnímu vyhledávání dat z databáze, jsou uvedeny níže:
Následující příklady vysvětlují výše uvedené agregace pomocí DOSTAT žádost od „ kibana_sample_data_ecommerce 'index:
Agregace mohutnosti
Následující kód používá „ mohutnost 'agregace na ' sku ” z dat elektronického obchodu. Spuštěním tohoto kódu získáte agregaci s jednou hodnotou pro získání jedinečných SKU z databáze Elasticsearch:
DOSTAT / kibana_sample_data_ecommerce / _Vyhledávání{
'velikost' : 0 ,
'aggs' : {
'unique_skus' : {
'kardinalita' : {
'pole' : 'sku'
}
}
}
}
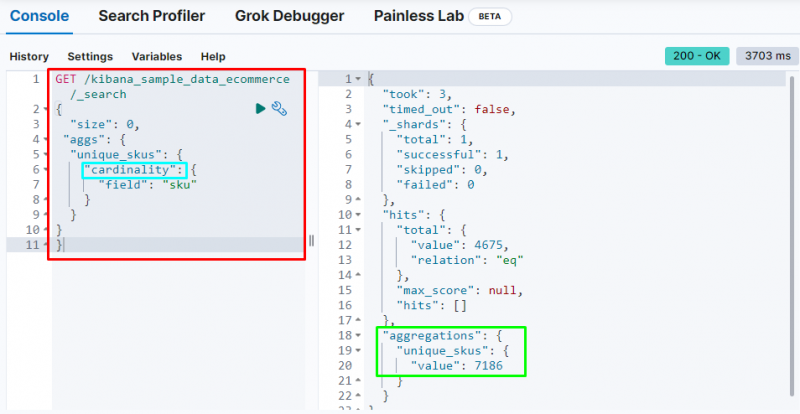
Zobrazuje mohutnost agregace najít 7186 hodnot z indexu.
Agregace statistik
Další důležitou agregací je „ statistiky „agregace, která se používá k získání „ počet “, “ min “, “ max “, “ prům ', a ' součet “ statistiky z “ celkové množství pole:
DOSTAT / kibana_sample_data_ecommerce / _Vyhledávání{
'velikost' : 0 ,
'aggs' : {
'quantity_stats' : {
'statistiky' : {
'pole' : 'celkové množství'
}
}
}
}
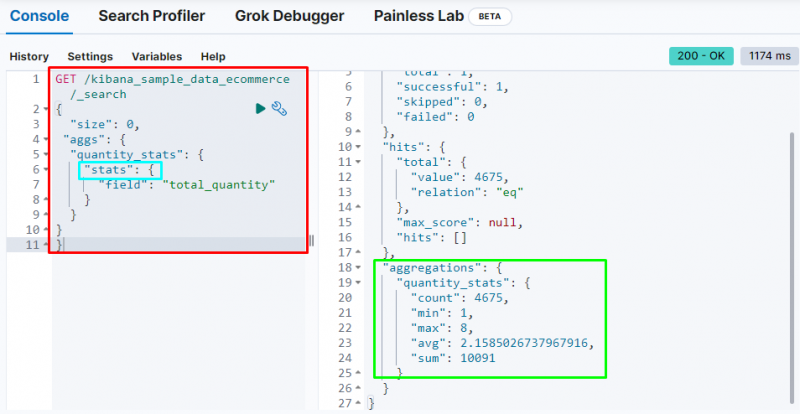
Výše uvedený snímek obrazovky zobrazuje statistiky ve výstupu z „ celkové množství pole.
Agregace filtrů
Agregace filtrů se používá k filtrování dat na základě výrazu nebo fráze z databáze, protože je obsahuje následující kód:
DOSTAT / kibana_sample_data_ecommerce / _Vyhledávání{ 'velikost' : 0 ,
'aggs' : {
'filter_agregation' : {
'filtr' : {
'období' : {
'uživatel' : 'eddie' } } ,
'aggs' : {
'price_avg' : {
'průměr' : {
'pole' : 'produkty.cena' } }
} } } }
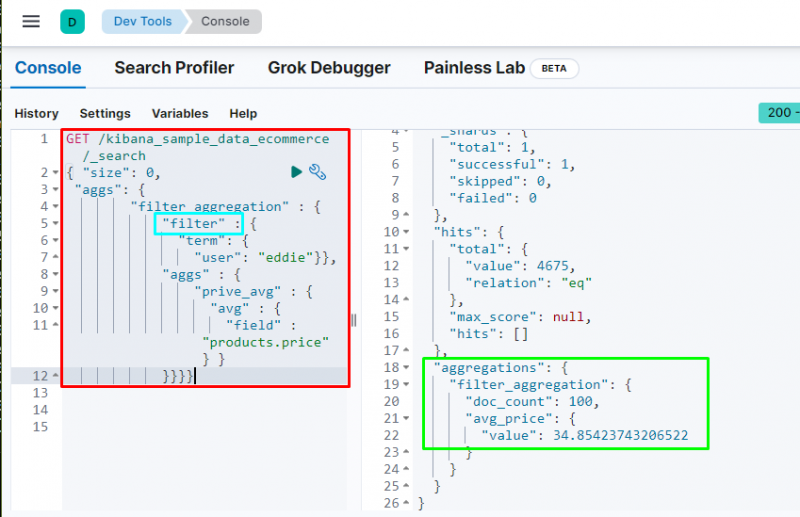
Spuštění kódu bude filtrovat data na základě „ Eddie “ a zobrazuje průměrnou cenu zakoupených položek. Výše uvedený snímek obrazovky ukazuje, že uživatel byl nalezen 100 časy z dat a hodnota z prům _ cena agregace.
Agregace termínů
Termín agregace vytvoří kbelík a uloží data z pole v kbelíku a následující kód používá „ uživatel ” pro uložení dat do segmentu:
DOSTAT / kibana_sample_data_ecommerce / _Vyhledávání{
'velikost' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'podmínky' : {
'pole' : 'uživatel'
}
}
}
}
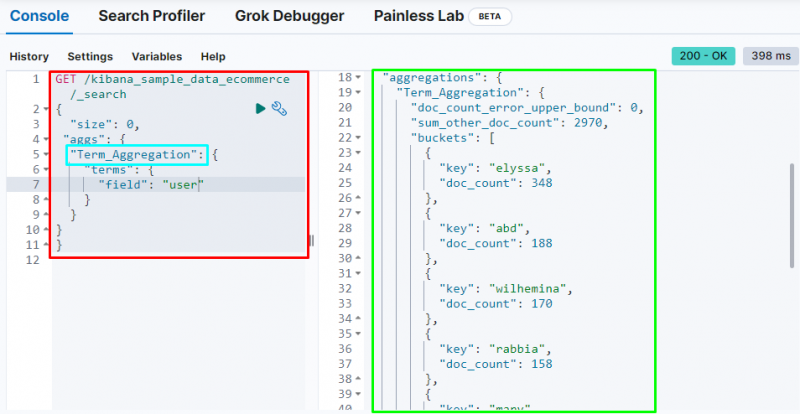
Následující snímek obrazovky ukazuje, že agregace termínů vytvořila segmenty pro každého uživatele a počet jeho dokumentů.
To je vše o agregaci Elasticsearch a různé důležité agregaci.
Závěr
V Elasticsearch se agregace používá k získání dat z agregovaných dokumentů a tyto dokumenty jsou extrahovány z konkrétního pole. Jsou zde vysvětleny některé důležité agregace, které se používají k získání užitečných informací z indexů. Tato příručka vysvětluje agregaci Elasticsearch a ukazuje proces použití agregace Elasticsearch.