Syntax:
Existuje celá řada služeb, které Hugging Face poskytuje, ale jednou z jeho široce používaných služeb je „API“. API umožňuje interakci předtrénované AI a velkých jazykových modelů s různými aplikacemi. Hugging Face poskytuje rozhraní API pro různé modely, jak je uvedeno níže:
- Modely generování textu
- Překladové modely
- Modely pro analýzu sentimentů
- Modely pro vývoj virtuálních agentů (inteligentních chatbotů)
- Klasifikace a regresní modely
Pojďme nyní objevit metodu, jak získat naše personalizované inferenční API z Hugging Face. Abychom to mohli udělat, musíme se nejprve zaregistrovat na oficiálních stránkách Hugging Face. Připojte se k této komunitě Hugging Face tím, že se přihlásíte na tento web pomocí svých přihlašovacích údajů.
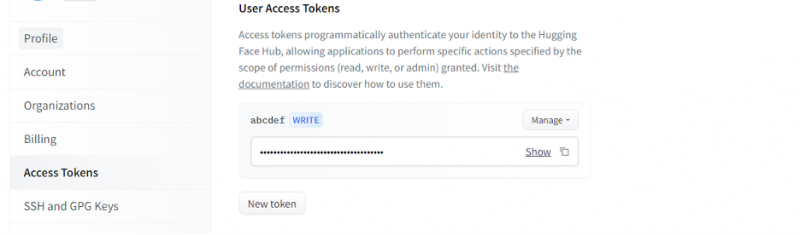
Jakmile získáme účet na Hugging Face, musíme nyní požádat o inferenční API. Chcete-li požádat o API, přejděte do nastavení účtu a vyberte „Přístupový token“. Otevře se nové okno. Vyberte možnost „Nový token“ a poté vygenerujte token tak, že nejprve zadáte název tokenu a jeho roli jako „ZAPIS“. Vygeneruje se nový token. Nyní musíme tento token uložit. Do této chvíle máme náš žeton z Objímající tváře. V dalším příkladu uvidíme, jak můžeme tento token použít k získání inferenčního API.
Příklad 1: Jak vytvořit prototyp s rozhraním Hugging Face Inference API
Zatím jsme diskutovali o metodě, jak začít s Hugging Face a inicializovali jsme token z Hugging Face. Tento příklad ukazuje, jak můžeme tento nově vygenerovaný token použít k získání inferenčního API pro konkrétní model (strojové učení) a prostřednictvím něj provádět předpovědi. Na domovské stránce Hugging Face vyberte model, se kterým chcete pracovat a který je relevantní pro váš problém. Řekněme, že chceme pracovat s textovou klasifikací nebo modelem analýzy sentimentu, jak je uvedeno v následujícím úryvku seznamu těchto modelů:
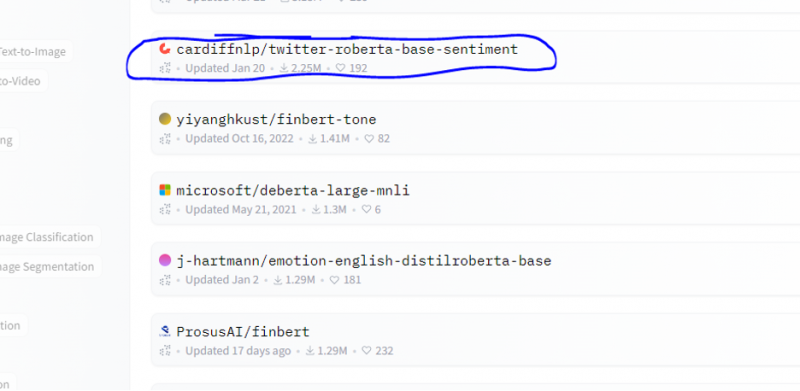
Z tohoto modelu vybíráme model analýzy sentimentu.
Po výběru modelu se zobrazí jeho karta modelu. Tato karta modelu obsahuje informace o podrobnostech tréninku modelu ao tom, jaké vlastnosti má model. Náš model je roBERTa-base, který je natrénován na 58M tweetech pro analýzu sentimentu. Tento model má tři hlavní štítky tříd a kategorizuje každý vstup do příslušných štítků tříd.
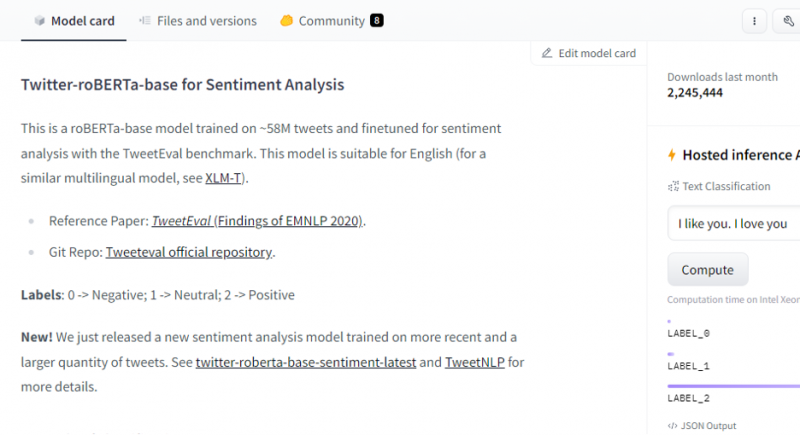
Pokud po výběru modelu vybereme tlačítko nasazení, které se nachází v pravém horním rohu okna, otevře se rozbalovací nabídka. Z této nabídky musíme vybrat možnost „Inference API“.
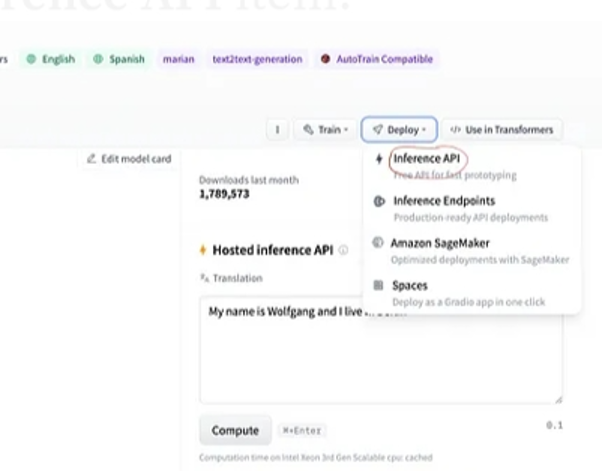
Inference API pak poskytuje úplné vysvětlení, jak používat tento konkrétní model s touto inferencí, a umožňuje nám rychle vytvořit prototyp pro model AI. Okno inference API zobrazuje kód, který je napsán ve skriptu Pythonu.
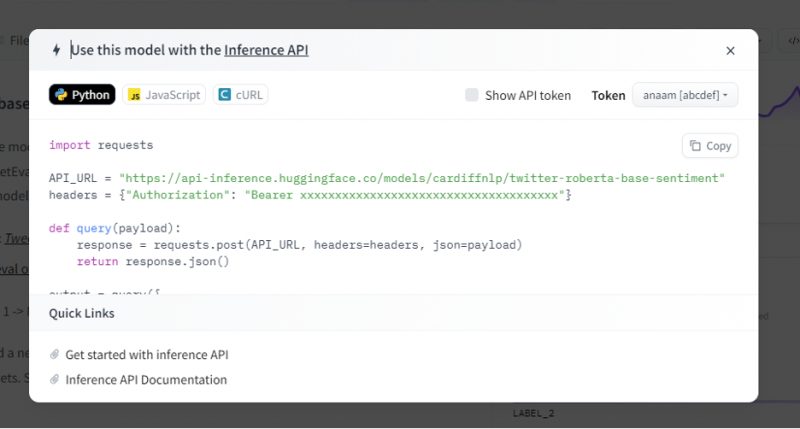
Tento kód zkopírujeme a spustíme v libovolném IDE Pythonu. K tomu používáme Google Colab. Po provedení tohoto kódu v shellu Pythonu vrátí výstup, který přichází se skóre a predikcí štítku. Toto označení a skóre jsou dány podle našeho vstupu, protože jsme zvolili model „analýzy sentimentu textu“. Vstupem, který modelu dáme, je pozitivní věta a model byl předem natrénován na tři třídy štítků: štítek 0 implikuje negativní, štítek1 implikuje neutrální a štítek 2 je nastaven na pozitivní. Protože naším vstupem je kladná věta, predikce skóre z modelu je větší než u ostatních dvou štítků, což znamená, že model předpověděl větu jako „pozitivní“.
import žádostiAPI_URL = 'https://api-inference.huggingface.co/models/cardiffnlp/twitter-roberta-base-sentiment'
hlavičky = { 'Oprávnění' : 'Nosič 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' }
def dotaz ( užitečné zatížení ) :
Odezva = žádosti. pošta ( API_URL , hlavičky = hlavičky , json = užitečné zatížení )
vrátit se Odezva. json ( )
výstup = dotaz ( {
'vstupy' : 'Cítím se dobře, když jsi se mnou' ,
} )
Výstup:

Příklad 2: Sumarizační model prostřednictvím inference
Postupujeme podle stejných kroků, jaké jsou uvedeny v předchozím příkladu, a prototypujeme sběrnici sumarizačního modelu pomocí jejího inferenčního API z Hugging Face. Sumarizační model je předem natrénovaný model, který shrnuje celý text, který mu dáme jako vstup. Přejděte na účet Hugging Face, klikněte na model v horní liště nabídek a poté vyberte model, který je relevantní pro shrnutí, vyberte jej a pečlivě si přečtěte jeho kartu modelu.
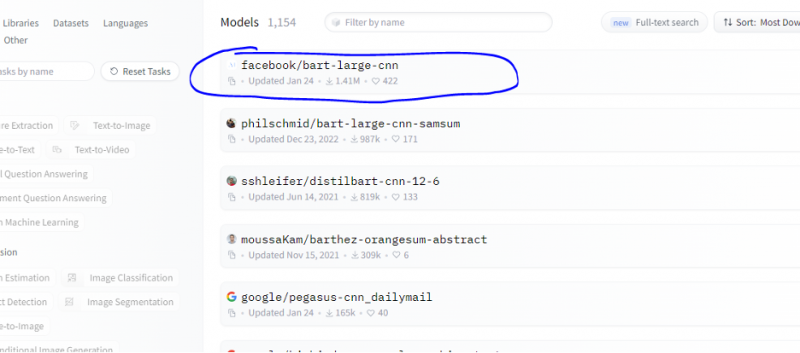
Model, který jsme vybrali, je předtrénovaný model BART a je jemně vyladěn na datovou sadu CNN dail mail. BART je model, který je nejvíce podobný modelu BERT, který má kodér a dekodér. Tento model je efektivní, když je vyladěn pro úkoly s porozuměním, sumarizací, překladem a generováním textu.
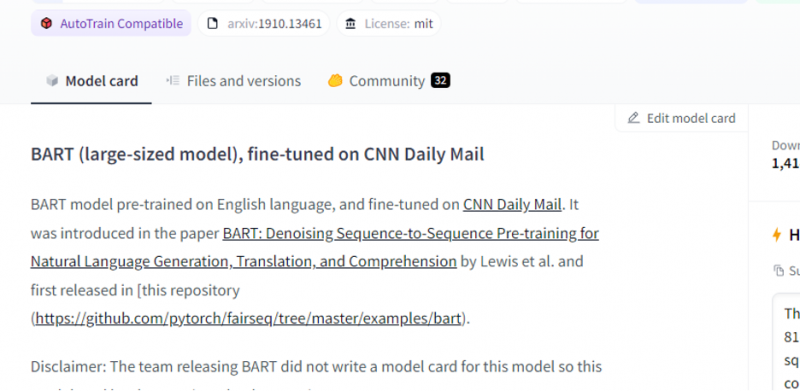
Poté v pravém horním rohu vyberte tlačítko „deployment“ a z rozbalovací nabídky vyberte rozhraní API pro odvození. Rozhraní API pro odvození otevře další okno, které obsahuje kód a pokyny k použití tohoto modelu s tímto odvozením.
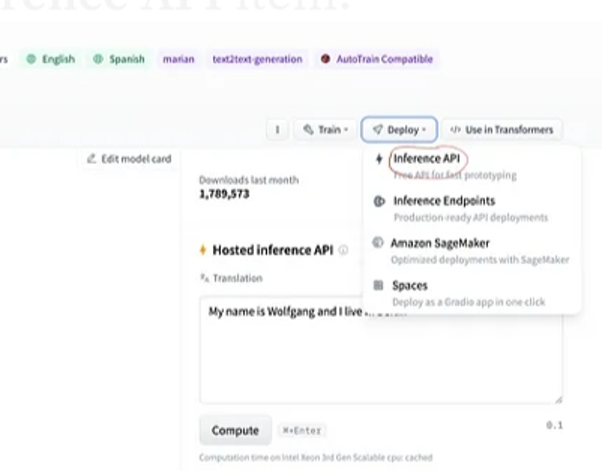
Zkopírujte tento kód a spusťte jej v shellu Pythonu.
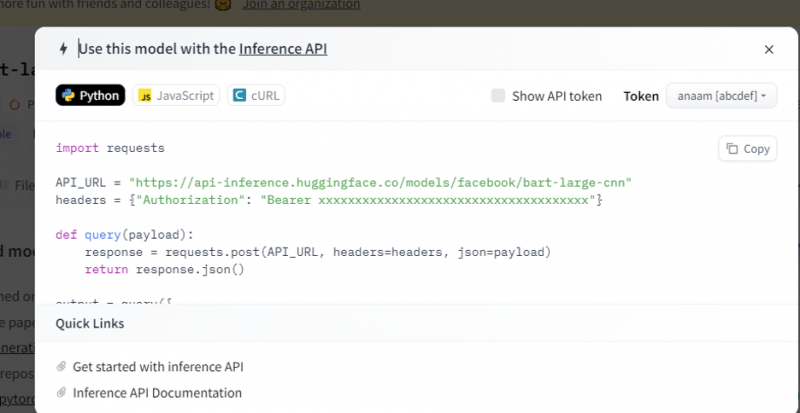
Model vrací výstup, což je sumarizace vstupu, který jsme do něj přivedli.

Závěr
Pracovali jsme na rozhraní Hugging Face Inference API a naučili jsme se, jak můžeme použít programovatelné rozhraní této aplikace pro práci s předem trénovanými jazykovými modely. Dva příklady, které jsme v článku provedli, byly založeny hlavně na modelech NLP. Hugging Face API dokáže zázraky, pokud chceme vyvinout rychlý prototyp poskytnutím rychlé integrace modelů AI do našich aplikací. Stručně řečeno, Hugging Face má řešení pro všechny vaše problémy od posilování po počítačové vidění.