Podívejme se nyní na nástroj iconv Linuxu v jeho terminálové konzoli. Spustili jsme tedy instrukci „iconv“ s příznakem „-l“, abychom zobrazili všechny známé a nejpoužívanější kódované znakové sady na obrazovce našeho terminálu. Zobrazí kódované znakové sady spolu s jejich aliasy. Po posunutí dolů můžete vidět dlouhý seznam kódovaných znakových sad.
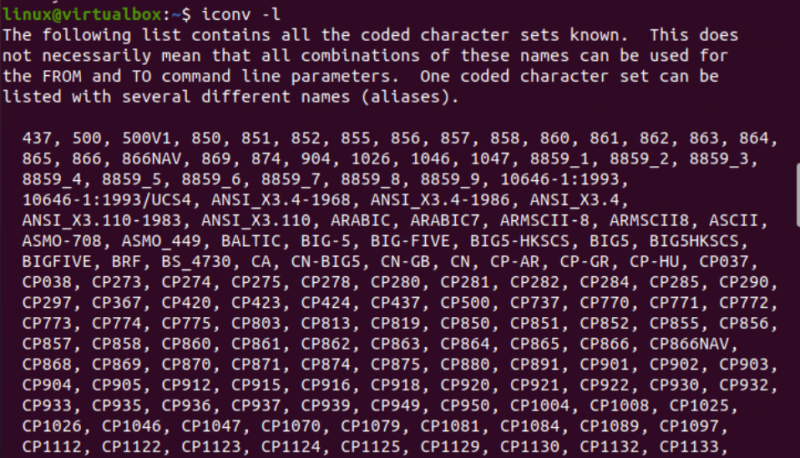
Nyní je čas začít s implementací příkazu iconv v Linuxu. Nejprve potřebujeme různé typy souborů v našem systému, abychom mohli převést jeden typ souboru na jiný. Využíváme tedy „dotykový“ dotaz na konzolovém terminálu k vytvoření tří různých souborů, tj. typu Java, typu C a typu textu. Ve výpisu aktuálního obsahu adresáře v něm najdete nově vygenerované soubory.
Poté se podíváme na typ každého souboru zvlášť pomocí dotazu „soubor“ spolu s názvem každého souboru. Tento dotaz vyžaduje volbu „-I“, aby se zobrazil typ kódovací znakové sady pro každý soubor zvlášť. Pokud jste zapomněli použít volbu „-I“, použijte místo toho příznak „—mime“. Oba příznaky „-I“ a „—mime“ fungují stejně.
Nyní, po provedení instrukce „soubor“ pro soubor typu „txt“, jsme získali kódování typu znaků „US-ASCII“. Při použití stejné instrukce pro soubory Java a C se ukazuje, že oba soubory obsahují kódování typu znaků „BINARY“. Spolu s tím tato instrukce ukazuje, že všechny tyto tři soubory jsou prázdné.
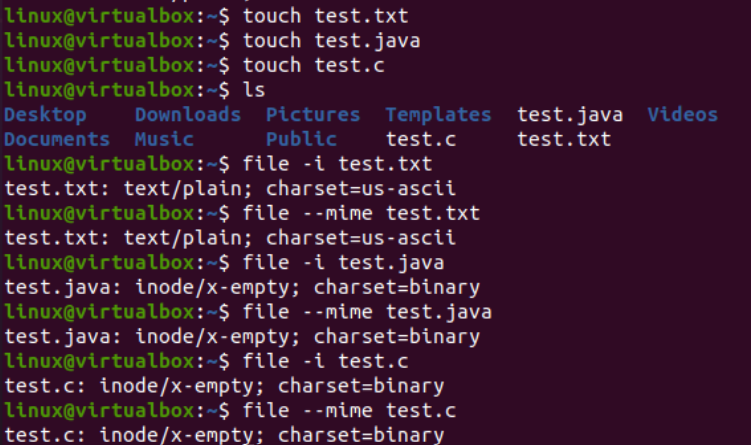
Nyní si ukážeme použití instrukce iconv na konzole pro převod konkrétního souboru kódování znakové sady na kódování jiné znakové sady. Před tím musíme do našich souborů přidat nějaký kód nebo data. Proto jsme přidali kód Java do souboru „text.java“, kód C do souboru „text.c“ a přidali textová data do souboru „test.txt“. Dotaz cat byl zde použit k zobrazení obsahu všech tří souborů, jak je uvedeno níže:
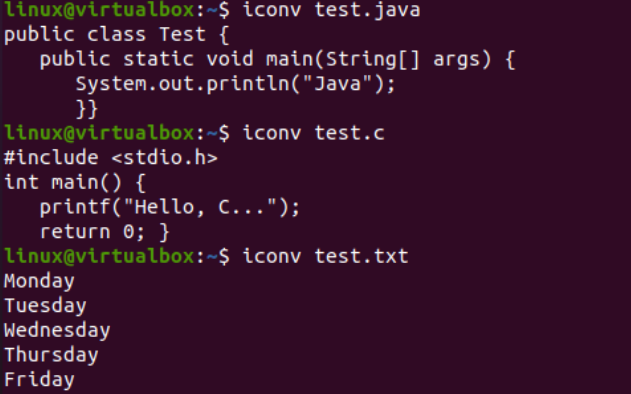
Nyní, když jsme úspěšně přidali data, uvidíme znovu kódování znakové sady těchto souborů. Vyzkoušeli jsme tedy stejnou souborovou instrukci v shellu s příznakem „-I“ a názvy souborů, tj. test.txt, test.java a test.c. Spuštění těchto tří instrukcí samostatně pro všechny tři soubory ukazuje, že kódování znakové sady bylo aktualizováno pro soubory Java a C, zatímco pro textový soubor zůstalo stejné, tj. US-ASCII. Kódování souborů Java a C bylo dříve „binární“; nyní je to „US-ASCII“. Také to ukazuje, že textový soubor obsahuje data ve formátu prostého textu, zatímco další dva soubory kódu obsahují skripty jako obsah.

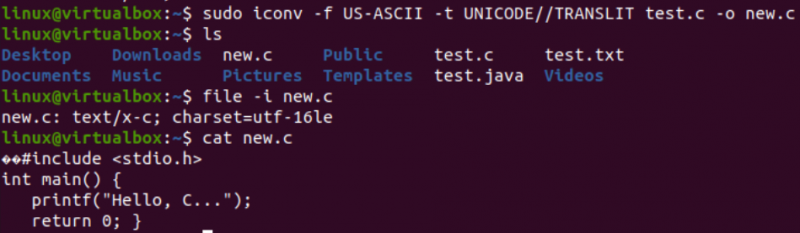
Je čas provést skutečný úkol potřebný pro tento článek, tj. převést jedno kódování na jiné pomocí příkazu iconv v shellu. Proto jsme používali instrukci „iconv“ v terminálu shellu s právy „sudo“. Tento příkaz přebírá možnost „-f“ znamená „od“ a možnost „-t“ znamená „do“, tj. z jednoho kódování do druhého.
Po volbě „-f“ musíte zadat kódování, které již váš soubor má, tj. US-ASCII. Zatímco za volbou „-t“ musíte zadat kódování, které chcete nahradit starým kódováním, tj. UNICODE. Chcete-li vytvořit obraz objektu, musíte zadat název souboru použitého jako zdroj pomocí volby –o. Obrázek objektu by byl jiný soubor, tj. „new.c“, stejného typu, ale s novým kódováním a stejnými daty.
Po provedení následující instrukce získáte nový soubor ve stejném adresáři, tedy podle dotazu „ls“. Nyní zkontrolujeme kódování znakové sady nového souboru vygenerovaného pomocí instrukce iconv. Opět použijeme instrukci „file“ s volbou „-I“ a novým názvem souboru, tedy new.c.
Uvidíte, že znaková sada pro tento nový soubor se liší od znakové sady starého souboru, tj. znakové sady UTF-16LE. Je to proto, že jsme přeložili kódování US-ASCII do kódování UNICODE pomocí instrukce iconv pro náš soubor new.c. Dotaz „cat“ zobrazil v souboru stejný kód C, ale začal s některými znaky Unicode, jak již bylo uvedeno.
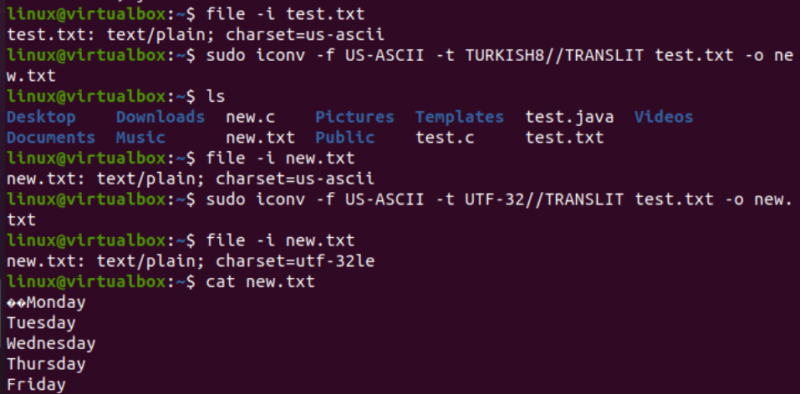
Velmi podobným způsobem změníme kódování textového souboru test.txt. Instrukce souboru ukazuje, že má kódování znakové sady US-ASCII. Příkaz iconv byl použit ve stejném formátu pro převod kódování souboru test.txt z US-ASCII na TURECKO8. Uvidíte, že to nezmění US-ASCII na turečtinu.
Poté jsme použili stejný příkaz k pokrytí kódování znakové sady US-ASCII až UTF-32 pro stejný soubor. Tentokrát to funguje. Důvodem je, že někdy může nastat problém s převodem jedné sady kódování na jinou nebo ji druhé kódování nemusí podporovat.
Závěr
Tento článek pojednává o tom, jak používat instrukce iconv Linux k převodu jedné kódovací znakové sady na jinou pomocí jejich aliasů. Tímto způsobem jsme museli vytvořit několik souborů různých typů.