UTF-8 znamená „ 8bitový transformační formát Unicode “ a odpovídá skvělému formátu kódování, který zajišťuje správné zobrazení znaků na všech zařízeních bez ohledu na použitý jazyk/skript. Tento formát je také nápomocný pro webové stránky a používá se pro ukládání, zpracování a přenos textových dat na internetu.
Tento tutoriál pokrývá níže uvedené oblasti obsahu:
- Co je kódování UTF-8?
- Jak funguje kódování UTF-8?
- Jak se počítají bodové hodnoty kódu?
- Jak kódovat/dekódovat UTF-8 v JavaScriptu?
- Kódování/dekódování UTF-8 v JavaScriptu pomocí metod „encodeURIComponent()“ a „decodeURIComponent()“.
- Kódování/dekódování UTF-8 v JavaScriptu pomocí metod „encodeURI()“ a „decodeURI()“.
- Kódování/dekódování UTF-8 v JavaScriptu pomocí regulárních výrazů.
- Závěr
Co je kódování UTF-8?
“ Kódování UTF-8 “ je postup transformace sekvence znaků Unicode na kódovaný řetězec obsahující 8bitové bajty. Toto kódování může představovat velký rozsah znaků ve srovnání s jinými kódováními znaků.
Jak funguje kódování UTF-8?
Při reprezentaci znaků v UTF-8 je každý jednotlivý kódový bod reprezentován jedním nebo více bajty. Následuje rozpis bodů kódu v rozsahu ASCII:
- Jeden bajt představuje kódové body v rozsahu ASCII (0-127).
- Dva bajty představují kódové body v rozsahu ASCII (128-2047).
- Tři bajty představují kódové body v rozsahu ASCII (2048-65535).
- Čtyři bajty představují kódové body v rozsahu ASCII (65536-1114111).
Je to takové, že první bajt „ UTF-8 'sekvence se označuje jako ' vedoucí bajt “, která poskytuje informace o počtu bajtů v sekvenci a hodnotě kódu znaku.
„Zaváděcí bajt“ pro sekvenci jednoho, dvou, tří a čtyř bajtů je v rozsahu (0-127), (194-233), (224-239) a (240-247).
Zbytek bajtů v pořadí se nazývá „ koncové “bajtů. Všechny bajty pro dvou, tří a čtyřbajtovou sekvenci jsou v rozsahu (128-191). Je to takové, že hodnotu kódu znaku lze vypočítat analýzou úvodních a koncových bajtů.
Jak se počítají bodové hodnoty kódu?
Hodnoty kódových bodů pro různé sekvence bajtů se vypočítají následovně:
- Dvoubajtová sekvence: Bod kódu je ekvivalentní „((lb – 194) * 64) + (tb – 128)“.
- Tříbajtová sekvence : Bod kódu je ekvivalentní „((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)“.
- Čtyřbajtová sekvence : Bod kódu je ekvivalentní „((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)“.
Jak kódovat/dekódovat UTF-8 v JavaScriptu?
Kódování a dekódování UTF-8 v JavaScriptu lze provést pomocí níže uvedených přístupů:
- “ enodeURIComponent() ' a ' decodeURIComponent() “Metody.
- “ encodeURI() ' a ' decodeURI() “Metody.
- Regulární výrazy.
Přístup 1: Kódování/dekódování UTF-8 v JavaScriptu pomocí metod „encodeURIComponent()“ a „decodeURIComponent()“
' encodeURIComponent() ” zakóduje komponentu URI. Může také kódovat speciální znaky, jako jsou @, &, :, +, $, # atd. decodeURIComponent() ” však dekóduje komponentu URI. Tyto metody lze použít ke kódování a dekódování předávaných hodnot do UTF-8, resp.
Syntaxe(Metoda „encodeURIComponent()“)
encodeURIComponent ( X )V dané syntaxi „ X ” označuje URI, které má být zakódováno.
Návratová hodnota
Tato metoda načetla zakódovaný URI jako řetězec.
Syntaxe(Metoda “decodeURIComponent()”)
decodeURIComponent ( X )Tady, ' X ” odkazuje na URI, které má být dekódováno.
Návratová hodnota
Tato metoda poskytuje dekódované URI.
Příklad 1: Kódování UTF-8 v JavaScriptu
Tento příklad zakóduje předaný řetězec na zakódovanou hodnotu UTF-8 pomocí uživatelem definované funkce:
vrátit se uniknout ( encodeURIComponent ( X ) ) ;
}
nech val = 'tady' ;
řídicí panel. log ( 'Daná hodnota ->' + val ) ;
nechat encodeVal = encode_utf8 ( val ) ;
řídicí panel. log ( 'Kódovaná hodnota ->' + encodeVal ) ;
V těchto řádcích kódu proveďte níže uvedené kroky:
- Nejprve definujte funkci „ encode_utf8() ”, který zakóduje předaný řetězec reprezentovaný zadaným parametrem.
- Toto kódování se provádí pomocí „ encodeURIComponent() ” v definici funkce.
- Poznámka: ' unescape() ” nahradí libovolnou escape sekvenci znakem, který reprezentuje.
- Poté inicializujte hodnotu, která má být zakódována, a zobrazte ji.
- Nyní vyvolejte definovanou funkci a předejte definovanou kombinaci znaků jako její argumenty pro zakódování této hodnoty do UTF-8.
Výstup
Zde lze naznačit, že jednotlivé znaky jsou odpovídajícím způsobem reprezentovány a kódovány v UTF-8.
Příklad 2: Dekódování UTF-8 v JavaScriptu
Níže uvedená ukázka kódu dekóduje předávanou hodnotu (ve formě znaků) do zakódované reprezentace UTF-8:
vrátit se decodeURIComponent ( uniknout ( X ) ) ;
}
nech val = 'à çè' ;
řídicí panel. log ( 'Daná hodnota ->' + val ) ;
nechat dekódovat = decode_utf8 ( val ) ;
řídicí panel. log ( 'Dekódovaná hodnota ->' + dekódovat ) ;
V tomto bloku kódu:
- Podobně definujte funkci „ decode_utf8() “, který dekóduje předávanou kombinaci znaků prostřednictvím „ decodeURIComponent() “ metoda.
- Poznámka: ' uniknout() ” metoda načte nový řetězec, ve kterém jsou různé znaky nahrazeny hexadecimálními sekvencemi escape.
- Poté zadejte kombinaci znaků, které mají být dekódovány, a přistupte k definované funkci, aby bylo dekódování správně provedeno do UTF-8.
Výstup

Zde lze naznačit, že kódovaná hodnota v předchozím příkladu je dekódována na výchozí hodnotu.
Přístup 2: Kódování/dekódování UTF-8 v JavaScriptu pomocí metod „encodeURI()“ a „decodeURI()“
' encodeURI() ” kóduje URI tak, že každý výskyt více znaků nahradí určitým počtem únikových sekvencí představujících kódování znaku UTF-8. Ve srovnání s „ encodeURIComponent() “, tato konkrétní metoda kóduje omezené znaky.
' decodeURI() ” však dekóduje URI (zakódované). Tyto metody lze implementovat v kombinaci pro kódování a dekódování kombinace znaků v hodnotě kódované UTF-8.
Syntaxe(metoda encodeURI())
encodeURI ( X )Ve výše uvedené syntaxi „ X ” odpovídá hodnotě, která má být zakódována jako URI.
Návratová hodnota
Tato metoda načte zakódovanou hodnotu ve formě řetězce.
Syntaxe(metoda decodeURI())
decodeURI ( X )Tady, ' X ” představuje zakódované URI, které má být dekódováno.
Návratová hodnota
Vrací dekódované URI jako řetězec.
Příklad 1: Kódování UTF-8 v JavaScriptu
Tato ukázka zakóduje předávanou kombinaci znaků na zakódovanou hodnotu UTF-8:
vrátit se uniknout ( encodeURI ( X ) ) ;
}
nech val = 'tady' ;
řídicí panel. log ( 'Daná hodnota ->' + val ) ;
nechat encodeVal = encode_utf8 ( val ) ;
řídicí panel. log ( 'Zakódovaná hodnota ->' + encodeVal ) ;
Zde si připomeňme přístupy pro definování funkce přidělené pro kódování. Nyní použijte metodu „encodeURI()“ k reprezentaci předané kombinace znaků jako řetězce kódovaného UTF-8. Poté podobně definujte znaky, které mají být vyhodnoceny, a vyvolejte definovanou funkci předáním definované hodnoty jako jejích argumentů pro provedení kódování.
Výstup
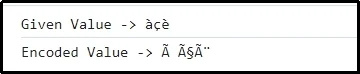
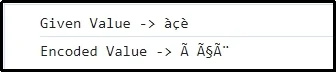
Zde je evidentní, že předaná kombinace znaků je úspěšně zakódována.
Příklad 2: Dekódování UTF-8 v JavaScriptu
Níže uvedená ukázka kódu dekóduje kódovanou hodnotu UTF-8 (v předchozím příkladu):
vrátit se decodeURI ( uniknout ( X ) ) ;
}
nech val = 'à çè' ;
řídicí panel. log ( 'Daná hodnota ->' + val ) ;
nechat dekódovat = decode_utf8 ( val ) ;
řídicí panel. log ( 'Dekódovaná hodnota ->' + dekódovat ) ;
Podle tohoto kódu deklarujte funkci „ decode_utf8() “, který obsahuje uvedený parametr, který představuje kombinaci znaků, které mají být dekódovány pomocí „ decodeURI() “ metoda. Nyní zadejte hodnotu, která má být dekódována, a vyvolejte definovanou funkci, aby se dekódování použilo na „ UTF-8 ' reprezentace.
Výstup
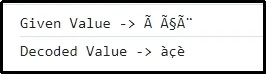
Tento výsledek znamená, že se podle toho rozhodne o dříve zakódované hodnotě.
Přístup 3: Kódování/dekódování UTF-8 v JavaScriptu pomocí regulárních výrazů
Tento přístup aplikuje kódování tak, že vícebajtový řetězec unicode je zakódován do UTF-8 více jednobajtových znaků. Podobně se dekódování provádí tak, že kódovaný řetězec je dekódován zpět na vícebajtové znaky Unicode.
Příklad 1: Kódování UTF-8 v JavaScriptu
Níže uvedený kód zakóduje vícebajtový řetězec unicode na jednobajtové znaky UTF-8:
-li ( Typ val != 'tětiva' ) házet Nový TypeError ( 'Parametr' val 'není řetězec' ) ;
konst string_utf8 = val. nahradit (
/[\u0080-\u07ff]/g , // U+0080 - U+07FF => 2 bajty 110yyyyy, 10zzzzzz
funkce ( X ) {
byl ven = X. charCodeAt ( 0 ) ;
vrátit se Tětiva . zCharCode ( 0xc0 | ven >> 6 , 0x80 | ven & 0x3f ) ; }
) . nahradit (
/[\u0800-\uffff]/g , // U+0800 - U+FFFF => 3 bajty 1110xxxx, 10yyyyyy, 10zzzzzz
funkce ( X ) {
byl ven = X. charCodeAt ( 0 ) ;
vrátit se Tětiva . zCharCode ( 0xe0 | ven >> 12 , 0x80 | ven >> 6 & 0x3F , 0x80 | ven & 0x3f ) ; }
) ;
řídicí panel. log ( 'Zakódovaná hodnota pomocí regulárního výrazu -> ' + string_utf8 ) ;
}
kódovatUTF8 ( 'tady' )
V tomto úryvku kódu:
- Definujte funkci ' kódovatUTF8() “ obsahující parametr, který představuje hodnotu, která má být zakódována jako „ UTF-8 “.
- V jeho definici použijte kontrolu na předávanou hodnotu, která není řetězcem pomocí „ Typ ” a vrátí zadanou vlastní výjimku přes “ házet “.
- Poté použijte „ charCodeAt() ' a ' fromCharCode() ” metody pro načtení Unicode prvního znaku v řetězci a transformaci dané hodnoty Unicode na znaky.
- Nakonec vyvolejte definovanou funkci předáním dané sekvence znaků pro zakódování této hodnoty jako „ UTF-8 ' reprezentace.
Výstup

Tento výstup znamená, že kódování je provedeno správně.
Příklad 2: Dekódování UTF-8 v JavaScriptu
V této ukázce je sekvence znaků dekódována na „ UTF-8 ' reprezentace:
-li ( Typ val != 'tětiva' ) házet Nový TypeError ( 'Parametr' val 'není řetězec' ) ;
konst str = val. nahradit (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g ,
funkce ( X ) {
byl ven = ( ( X. charCodeAt ( 0 ) & 0x0f ) << 12 ) | ( ( X. charCodeAt ( 1 ) & 0x3f ) << 6 ) | ( X. charCodeAt ( 2 ) & 0x3f ) ;
vrátit se Tětiva . zCharCode ( ven ) ; }
) . nahradit (
/[\u00c0-\u00df][\u0080-\u00bf]/g ,
funkce ( X ) {
byl ven = ( X. charCodeAt ( 0 ) & 0x1f ) < '+str);
}
decodeUTF8('à çè')
V tomto kódu:
- Podobně definujte funkci „ decodeUTF8() ” s parametrem, který odkazuje na předávanou hodnotu, která má být dekódována.
- V definici funkce zkontrolujte podmínku řetězce předávané hodnoty pomocí „ Typ “ operátor.
- Nyní použijte „ charCodeAt() ” metoda k načtení Unicode znaků prvního, druhého a třetího řetězce.
- Aplikujte také „ String.fromCharCode() ” pro transformaci hodnot Unicode na znaky.
- Podobně opakujte tento postup znovu pro načtení Unicode prvního a druhého řetězce znaků a transformaci těchto unicode hodnot na znaky.
- Nakonec přejděte k definované funkci a vraťte dekódovanou hodnotu UTF-8.
Výstup

Zde lze ověřit, že dekódování je provedeno správně.
Závěr
Kódování/dekódování v reprezentaci UTF-8 lze provést pomocí „ enodeURIComponent()” a ' decodeURIComponent() metody, „ encodeURI() ' a ' decodeURI() ” nebo pomocí regulárních výrazů.