Optimalizace kódu Pythonu pomocí nástrojů pro profilování
Při nastavování služby Google Colab tak, aby fungovala pro optimalizaci kódu Python pomocí profilovacích nástrojů, začneme nastavením prostředí Google Colab. Pokud jsme ve službě Colab noví, jedná se o základní, výkonnou cloudovou platformu, která poskytuje přístup k notebookům Jupyter a řadě knihoven Python. Ke službě Colab přistupujeme tak, že navštívíme (https://colab.research.google.com/) a vytvoříme nový notebook Python.
Importujte knihovny profilování
Naše optimalizace se opírá o zdatné využívání profilovacích knihoven. Dvě důležité knihovny v tomto kontextu jsou cProfile a line_profiler.
import cProfile
import line_profiler
Knihovna „cProfile“ je vestavěný nástroj Pythonu pro profilování kódu, zatímco „line_profiler“ je externí balíček, který nám umožňuje jít ještě hlouběji a analyzovat kód řádek po řádku.
V tomto kroku vytvoříme ukázkový skript Python pro výpočet Fibonacciho sekvence pomocí rekurzivní funkce. Pojďme analyzovat tento proces hlouběji. Fibonacciho posloupnost je množina čísel, ve kterých každé následující číslo je součtem dvou před ním. Obvykle začíná 0 a 1, takže sekvence vypadá jako 0, 1, 1, 2, 3, 5, 8, 13, 21 a tak dále. Je to matematická sekvence, která se běžně používá jako příklad v programování kvůli své rekurzivní povaze.
V rekurzivní Fibonacciho funkci definujeme pythonskou funkci nazvanou „Fibonacci“. Tato funkce bere jako argument „n“ celé číslo, které představuje pozici ve Fibonacciho posloupnosti, kterou chceme vypočítat. Chceme najít páté číslo ve Fibonacciho posloupnosti, například pokud se „n“ rovná 5.
def fibonacci ( n ) :
Dále vytvoříme základní případ. Základní případ v rekurzi je scénář, který ukončí volání a vrátí předem stanovenou hodnotu. Ve Fibonacciho posloupnosti, když „n“ je 0 nebo 1, již známe výsledek. 0. a 1. Fibonacciho číslo je 0 a 1.
-li n <= 1 :vrátit se n
Tento příkaz „if“ určuje, zda je „n“ menší nebo rovno 1. Pokud ano, vrátíme samotné „n“, protože není potřeba další rekurze.
Rekurzivní výpočet
Pokud „n“ překročí 1, pokračujeme v rekurzivním výpočtu. V tomto případě potřebujeme najít „n“-té Fibonacciho číslo sečtením „(n-1)“ a „(n-2)“-tého Fibonacciho čísla. Toho dosáhneme provedením dvou rekurzivních volání v rámci funkce.
jiný :vrátit se fibonacci ( n - 1 ) + Fibonacci ( n - 2 )
Zde „fibonacci(n – 1)“ vypočítá „(n-1)“-té Fibonacciho číslo a „fibonacci(n – 2)“ vypočítá „(n-2)“-té Fibonacciho číslo. Přidáme tyto dvě hodnoty, abychom získali požadované Fibonacciho číslo na pozici „n“.
Stručně řečeno, tato „Fibonacciho“ funkce rekurzivně vypočítává Fibonacciho čísla rozdělením problému na menší dílčí problémy. Provádí rekurzivní volání, dokud nedosáhne základních případů (0 nebo 1), přičemž vrací známé hodnoty. Pro jakékoli jiné „n“ vypočítá Fibonacciho číslo sečtením výsledků dvou rekurzivních volání „(n-1)“ a „(n-2)“.
I když je tato implementace pro výpočet Fibonacciho čísel jednoduchá, není nejúčinnější. V pozdějších krocích použijeme profilovací nástroje k identifikaci a optimalizaci omezení výkonu pro lepší časy provádění.
Profilování kódu pomocí CProfile
Nyní profilujeme naši funkci „Fibonacci“ pomocí „cProfile“. Toto profilovací cvičení poskytuje přehled o čase spotřebovaném každým voláním funkce.
cprofiler = cProfile. Profil ( )cprofiler. umožnit ( )
výsledek = fibonacci ( 30 )
cprofiler. zakázat ( )
cprofiler. print_stats ( seřadit = 'kumulativní' )
V tomto segmentu inicializujeme objekt „cProfile“, aktivujeme profilování, vyžádáme si funkci „fibonacci“ s „n=30“, deaktivujeme profilování a zobrazíme statistiky seřazené podle kumulativního času. Toto počáteční profilování nám poskytuje přehled na vysoké úrovni o tom, které funkce zabírají nejvíce času.
! pip install line_profilerimport cProfile
import line_profiler
def fibonacci ( n ) :
-li n <= 1 :
vrátit se n
jiný :
vrátit se fibonacci ( n - 1 ) + Fibonacci ( n - 2 )
cprofiler = cProfile. Profil ( )
cprofiler. umožnit ( )
výsledek = fibonacci ( 30 )
cprofiler. zakázat ( )
cprofiler. print_stats ( seřadit = 'kumulativní' )
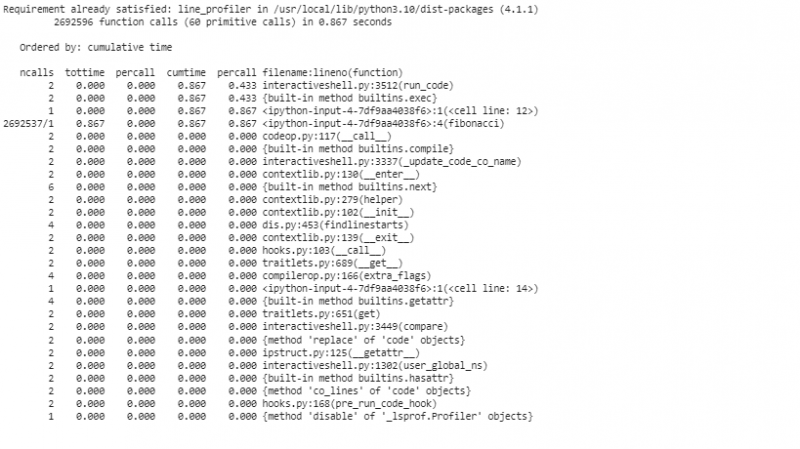
Pro profilování kódu řádek po řádku pomocí line_profiler pro podrobnější analýzu používáme „line_profiler“ k segmentování našeho kódu řádek po řádku. Před použitím „line_profiler“ musíme balíček nainstalovat do úložiště Colab.
! pip install line_profilerNyní, když máme „line_profiler“ připravený, můžeme jej aplikovat na naši funkci „Fibonacci“:
%load_ext line_profilerdef fibonacci ( n ) :
-li n <= 1 :
vrátit se n
jiný :
vrátit se fibonacci ( n - 1 ) + Fibonacci ( n - 2 )
%lprun -f Fibonacci fibonacci ( 30 )
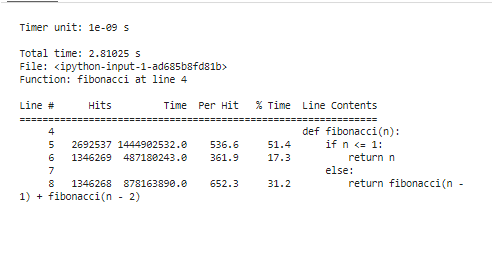
Tento fragment začíná načtením rozšíření „line_profiler“, definuje naši funkci „fibonacci“ a nakonec využívá „%lprun“ k profilování funkce „fibonacci“ s „n=30“. Nabízí segmentaci doby provádění po řádcích a přesně vyčistí, kde náš kód vynakládá své prostředky.
Po spuštění profilovacích nástrojů k analýze výsledků se jim zobrazí řada statistik, které ukazují výkonnostní charakteristiky našeho kódu. Tyto statistiky zahrnují celkový čas strávený každou funkcí a dobu trvání každého řádku kódu. Můžeme například rozlišit, že Fibonacciho funkce investuje trochu více času do vícenásobného přepočítávání stejných hodnot. Toto je redundantní výpočet a je to jasná oblast, kde lze použít optimalizaci, buď pomocí memoizace nebo pomocí iteračních algoritmů.
Nyní provádíme optimalizace, kde jsme identifikovali potenciální optimalizaci v naší Fibonacciho funkci. Všimli jsme si, že funkce přepočítává stejná Fibonacciho čísla vícekrát, což má za následek zbytečnou redundanci a pomalejší dobu provádění.
Abychom to optimalizovali, implementujeme zapamatování. Memoizace je optimalizační technika, která zahrnuje ukládání dříve vypočítaných výsledků (v tomto případě Fibonacciho čísel) a jejich opětovné použití, když je potřeba, místo jejich přepočítávání. To snižuje nadbytečné výpočty a zlepšuje výkon, zejména u rekurzivních funkcí, jako je Fibonacciho sekvence.
Abychom implementovali zapamatování v naší Fibonacciho funkci, napíšeme následující kód:
# Slovník pro ukládání vypočítaných Fibonacciho číselfib_cache = { }
def fibonacci ( n ) :
-li n <= 1 :
vrátit se n
# Zkontrolujte, zda je výsledek již uložen do mezipaměti
-li n v fib_cache:
vrátit se fib_cache [ n ]
jiný :
# Vypočítejte a uložte výsledek do mezipaměti
fib_cache [ n ] = fibonacci ( n - 1 ) + Fibonacci ( n - 2 )
vrátit se fib_cache [ n ] ,
V této upravené verzi funkce „Fibonacci“ zavádíme slovník „fib_cache“ pro ukládání dříve vypočítaných Fibonacciho čísel. Před výpočtem Fibonacciho čísla zkontrolujeme, zda je již v mezipaměti. Pokud ano, vrátíme výsledek uložený v mezipaměti. V každém jiném případě to spočítáme, ponecháme v mezipaměti a poté vrátíme.
Opakování profilování a optimalizace
Po implementaci optimalizace (v našem případě zapamatování) je klíčové zopakovat proces profilování, abychom poznali dopad našich změn a zajistili, že jsme zlepšili výkon kódu.
Profilování po optimalizaci
Pro profilování optimalizované Fibonacciho funkce můžeme použít stejné profilovací nástroje, „cProfile“ a „line_profiler“. Porovnáním nových výsledků profilování s předchozími můžeme měřit efektivitu naší optimalizace.
Zde je návod, jak můžeme profilovat optimalizovanou funkci „Fibonacci“ pomocí „cProfile“:
cprofiler = cProfile. Profil ( )cprofiler. umožnit ( )
výsledek = fibonacci ( 30 )
cprofiler. zakázat ( )
cprofiler. print_stats ( třídit = 'kumulativní' )
Pomocí „line_profiler“ jej profilujeme řádek po řádku:
%lprun -f Fibonacci fibonacci ( 30 )Kód:
# Slovník pro ukládání vypočítaných Fibonacciho číselfib_cache = { }
def fibonacci ( n ) :
-li n <= 1 :
vrátit se n
# Zkontrolujte, zda je výsledek již uložen do mezipaměti
-li n v fib_cache:
vrátit se fib_cache [ n ]
jiný :
# Vypočítejte a uložte výsledek do mezipaměti
fib_cache [ n ] = fibonacci ( n - 1 ) + Fibonacci ( n - 2 )
vrátit se fib_cache [ n ]
cprofiler = cProfile. Profil ( )
cprofiler. umožnit ( )
výsledek = fibonacci ( 30 )
cprofiler. zakázat ( )
cprofiler. print_stats ( třídit = 'kumulativní' )
%lprun -f Fibonacci fibonacci ( 30 )
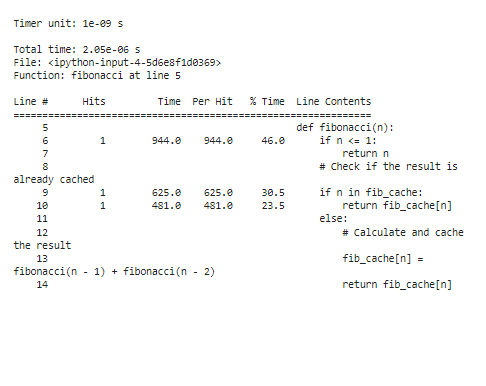
Aby bylo možné analyzovat výsledky profilování po optimalizaci, výrazně se zkrátí doby provádění, zejména u velkých hodnot „n“. Díky memoizaci pozorujeme, že funkce nyní tráví mnohem méně času přepočítáváním Fibonacciho čísel.
Tyto kroky jsou nezbytné v procesu optimalizace. Optimalizace zahrnuje provádění informovaných změn v našem kódu na základě pozorování získaných z profilování, zatímco opakované profilování zajišťuje, že naše optimalizace přinesou očekávaná zlepšení výkonu. Pomocí iterativního profilování, optimalizace a ověřování můžeme vyladit náš kód Python tak, aby poskytoval lepší výkon a zlepšil uživatelský zážitek z našich aplikací.
Závěr
V tomto článku jsme diskutovali o příkladu, kdy jsme optimalizovali kód Pythonu pomocí profilovacích nástrojů v prostředí Google Colab. Inicializovali jsme příklad s nastavením, importovali jsme základní profilovací knihovny, napsali ukázkové kódy, profilovali jsme jej pomocí „cProfile“ a „line_profiler“, vypočítali výsledky, použili optimalizace a iterativně vylepšili výkon kódu.