Tato příručka bude demonstrovat použití příkazů vysoké úrovně v AWS CLI.
Jak používat příkazy vysoké úrovně (S3) s AWS CLI?
Příkazy na vysoké úrovni Simple Storage Service nebo S3 AWS CLI se používají ke správě segmentů S3 a objektů, které jsou v nich uloženy.
Chcete-li používat příkazy AWS CLI S3 na vysoké úrovni, postupujte podle tohoto průvodce:
Nakonfigurujte AWS CLI
Chcete-li začít používat příkazy AWS CLI na vysoké úrovni, je to nutné nakonfigurujte AWS CLI nejprve pomocí následujících příkazů:
aws konfigurovat
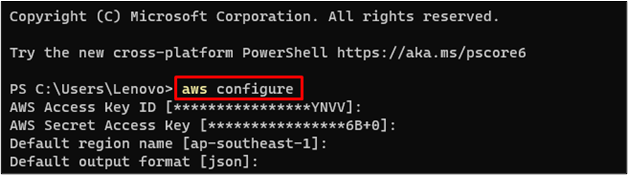
Vyžaduje, aby uživatel poskytl přihlašovací údaje uživatele IAM a oblast, ve které budou prostředky S3 spravovány.
Vedlejší poznámka : Pokud se chce uživatel dozvědět, jak nainstalovat AWS CLI na místní systém, stačí kliknout tady .
Vytvořte S3 Bucket
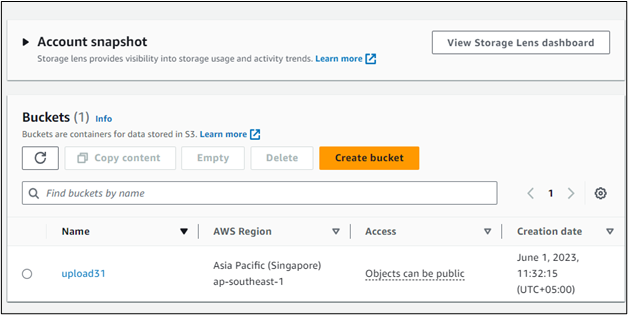
Chcete-li začít používat příkazy S3 na vysoké úrovni s AWS CLI, zamiřte do řídicího panelu S3 a zkontrolujte, zda již není vytvořena skupina S3. Následující snímek obrazovky ukazuje, že jeden segment S3 je již k dispozici na řídicím panelu S3 s názvem „ upload31 “:
Syntax
Chcete-li vytvořit další bucket, jednoduše zamiřte do terminálu a použijte následující syntaxi k vytvoření bucketu S3 pomocí AWS CLI:
Změňte název segmentu z výše uvedené syntaxe a název segmentu by měl být jedinečný:
aws s3 mb s3: // my-bucket-linuxhint 
Vytvoří kbelík S3, jak je znázorněno na výše uvedeném snímku obrazovky.
Pomocí následujícího příkazu získáte seznam segmentů S3 dostupných na účtu AWS v zadané oblasti:
aws s3 ls 
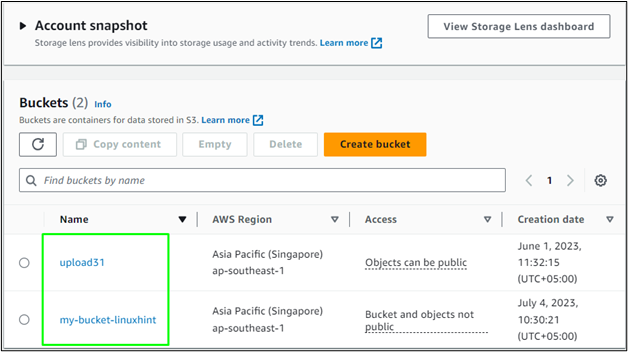
Zobrazuje názvy dvou dostupných segmentů s časovým razítkem jejich vytvoření.
Zamiřte do palubní desky S3 z konzoly AWS a ověřte přítomnost obou kbelíků:
Nahrajte objekty do S3 Bucket
Dalším využitím příkazů vysoké úrovně pro S3 s AWS CLI je nahrávání objektů v bucketu S3 z místního adresáře.
Syntax
K nahrání souboru z místního systému do bloku S3 v cloudu použijte následující syntaxi:
Chcete-li soubor nahrát do cloudu, změňte název souboru s jeho příponou a název segmentu při psaní výše uvedené syntaxe:
aws s3 cp Web.html s3: // upload31 
Snímek obrazovky zobrazuje objekty nahrané do bucketu S3.
Následující příkazy jednoduše zobrazí seznam objektů nahraných na „ upload31 'Kbelík S3:
aws s3 ls s3: // upload31Pomocí tohoto příkazu získáte seznam nahraných objektů na 'my-bucket-linuxhint' Kbelík:
aws s3 ls s3: // my-bucket-linuxhint 
Seznam objektů je zobrazen na snímku obrazovky pro segment upload31 a druhý segment neobsahuje žádný objekt, protože příkaz nic nevrací.
Vyjměte S3 Bucket
Odstranění bucketu je dalším případem použití příkazů S3 na vysoké úrovni s AWS CLI. K odstranění bloku se používá následující syntaxe:
aws s3 rb s3: // bucket-namePo změně názvu segmentu pomocí segmentu, který chce uživatel odstranit, použijte následující příkaz:
aws s3 rb s3: // my-bucket-linuxhint 
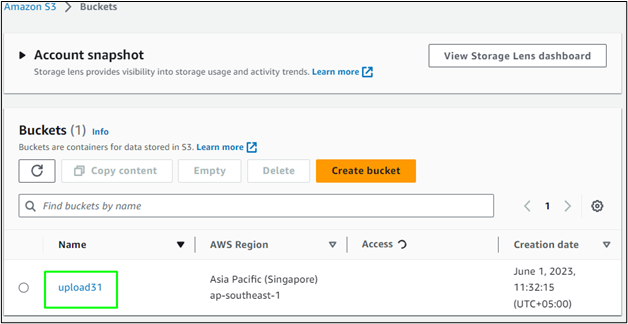
Zobrazuje 'removal_bucket' zpráva, která ověřuje proces mazání.
Uživatel může také ověřit výše uvedený proces z řídicího panelu AWS S3:
Jednoduše odstraňte kbelík s nahraným objektem pomocí následujícího příkazu:
aws s3 rb s3: // upload31 
Zobrazuje „remove_bucket se nezdařilo“ chyba, protože kbelík není prázdný. Chcete-li smazat sektor, je nutné nejprve odstranit objekt a poté odstranit sektor.
Prázdný kbelík S3 (odstranit objekt)
K odstranění objektu z bucketu musí uživatel získat názvy bucketů nahraných do S3 pomocí následujícího příkazu:
aws s3 ls s3: // upload31 
Výše uvedený příkaz zobrazí název objektu nahraného na upload31 Kbelík.
Chcete-li odebrat objekty z bloku S3, jednoduše použijte následující syntaxi příkazu CLI S3 AWS na vysoké úrovni:
aws s3 rm s3: // bucket-name / název_souboru.txtZměňte název kbelíku a poté zadejte správný název objektu s jeho příponou, abyste provedli příkaz:
aws s3 rm s3: // upload31 / Web.htmlNásledující snímek obrazovky ukazuje, že objekt byl úspěšně odstraněn:

Jednoduše použijte následující příkaz k odstranění bucketu poté, co jste do něj nahráli objekty:
aws s3 rb s3: // upload31Následující snímek obrazovky zobrazuje 'remove_bucket' zpráva s názvem smazaného segmentu, která naznačuje úspěch procesu:

Zamiřte do konzoly pro správu AWS, navštivte řídicí panel S3 a ověřte, že je mazání bucketů dokončeno:
To je vše o používání příkazů S3 na vysoké úrovni s AWS CLI.
Závěr
Chcete-li používat příkazy S3 na vysoké úrovni s AWS CLI, musí uživatel nakonfigurovat AWS CLI pomocí uživatelských pověření IAM. Jakmile je AWS CLI nakonfigurováno pomocí uživatele/profilu IAM s oprávněními S3, jednoduše použijte příkazy AWS CLI k vytvoření segmentů S3 a poté do něj nahrajte objekty. Uživatel může odebrat buckety a odstranit objekty z bucketu S3 pomocí příkazů AWS CLI.