Umělá inteligence je jednou z nejrychleji rostoucích technologií využívajících algoritmy strojového učení k trénování a testování modelů využívajících obrovská data. Data mohou být uložena v různých formátech, ale pro vytváření velkých jazykových modelů pomocí LangChain je nejpoužívanějším typem JSON. Trénovací a testovací data musí být jasná a úplná bez jakýchkoli dvojznačností, aby model mohl fungovat efektivně.
Tato příručka demonstruje proces použití pydantického analyzátoru JSON v LangChain.
Jak používat Pydantic (JSON) Parser v LangChain?
Data JSON obsahují textový formát dat, která lze shromažďovat prostřednictvím webového scrapingu a mnoha dalších zdrojů, jako jsou protokoly atd. K ověření přesnosti dat používá LangChain ke zjednodušení procesu pydantické knihovny z Pythonu. Chcete-li použít pydantický analyzátor JSON v LangChain, jednoduše si projděte tuto příručku:
Krok 1: Nainstalujte moduly
Chcete-li začít s procesem, jednoduše nainstalujte modul LangChain, abyste mohli používat jeho knihovny pro použití analyzátoru v LangChain:
pip Nainstalujte langchain
Nyní použijte „ pip nainstalovat ” pro získání rámce OpenAI a využití jeho prostředků:
pip Nainstalujte openai
Po instalaci modulů se jednoduše připojte k prostředí OpenAI poskytnutím jeho klíče API pomocí „ vy ' a ' getpass “knihovny:
importujte násimportovat getpass
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API Key:' )

Krok 2: Import knihoven
Pomocí modulu LangChain importujte potřebné knihovny, které lze použít pro vytvoření šablony pro výzvu. Šablona výzvy popisuje metodu kladení otázek v přirozeném jazyce, aby model výzvě efektivně porozuměl. Také importujte knihovny jako OpenAI a ChatOpenAI a vytvořte řetězce pomocí LLM pro vytvoření chatbota:
z langchain.prompts import (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
z langchain.llms importujte OpenAI
z langchain.chat_models importujte ChatOpenAI
Poté importujte pydantické knihovny, jako je BaseModel, Field a validator, abyste mohli používat analyzátor JSON v LangChain:
z langchain.output_parsers importujte PydanticOutputParserz pydantického importu BaseModel, Field, validator
zadáním seznamu importu
Krok 3: Vytvoření modelu
Po získání všech knihoven pro použití pydantického analyzátoru JSON jednoduše získejte předem navržený testovaný model s metodou OpenAI():
model_name = 'text-davinci-003'teplota = 0,0
model = OpenAI ( jméno modelu =název_modelu, teplota = teplota )
Krok 4: Nakonfigurujte Actor BaseModel
Sestavte další model a získejte odpovědi týkající se herců, jako jsou jejich jména a filmy, tím, že požádáte o filmografii herce:
třídní herec ( Základní Model ) :jméno: str = Pole ( popis = 'Jméno hlavního herce' )
film_names: Seznam [ str ] = Pole ( popis = „Filmy, ve kterých byl herec hlavní“ )
herec_dotaz = 'Chci vidět filmografii jakéhokoli herce'
parser = PydanticOutputParser ( pydantický_objekt = Herec )
prompt = PromptTemplate (
šablona = 'Odpovězte na výzvu od uživatele. \n {format_instructions} \n {dotaz} \n ' ,
vstupní_proměnné = [ 'dotaz' ] ,
částečné_proměnné = { 'format_instructions' : parser.get_format_instructions ( ) } ,
)
Krok 5: Testování základního modelu
Jednoduše získejte výstup pomocí funkce parse() s výstupní proměnnou obsahující výsledky generované pro výzvu:
_input = prompt.format_prompt ( dotaz =actor_query )výstup = model ( _input.to_string ( ) )
parser.parse ( výstup )
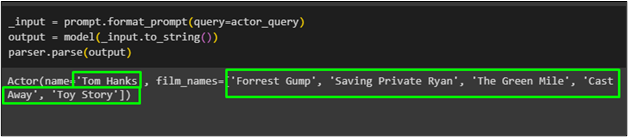
Herec jménem „ Tom Hanks ” se seznamem jeho filmů byl získán pomocí pydantické funkce z modelu:
To je vše o použití pydantického analyzátoru JSON v LangChain.
Závěr
Chcete-li používat pydantický analyzátor JSON v LangChain, jednoduše nainstalujte moduly LangChain a OpenAI a připojte se k jejich zdrojům a knihovnám. Poté importujte knihovny jako OpenAI a pydantic, abyste vytvořili základní model a ověřili data ve formě JSON. Po sestavení základního modelu spusťte funkci parse() a ta vrátí odpovědi na výzvu. Tento příspěvek demonstroval proces použití pydantického analyzátoru JSON v LangChain.