Tato příručka ilustruje, jak používat VectorStoreRetrieverMemory pomocí rámce LangChain.
Jak používat VectorStoreRetrieverMemory v LangChain?
VectorStoreRetrieverMemory je knihovna LangChain, kterou lze použít k extrahování informací/dat z paměti pomocí vektorových úložišť. Vektorové úložiště lze použít k ukládání a správě dat k efektivnímu extrahování informací podle výzvy nebo dotazu.
Chcete-li se naučit proces používání VectorStoreRetrieverMemory v LangChain, jednoduše si projděte následující průvodce:
Krok 1: Nainstalujte moduly
Zahajte proces používání paměťového retrieveru instalací LangChain pomocí příkazu pip:
pip install langchain
Nainstalujte moduly FAISS, abyste získali data pomocí vyhledávání sémantické podobnosti:
pip install faiss-gpu 
Nainstalujte modul chromadb pro používání databáze Chroma. Funguje jako vektorové úložiště pro vytvoření paměti pro retrívra:
pip install chromadb 
K instalaci je potřeba další tiktoken modulu, který lze použít k vytvoření tokenů převodem dat na menší části:
pip nainstalovat tiktoken 
Nainstalujte modul OpenAI, abyste mohli používat jeho knihovny pro vytváření LLM nebo chatbotů pomocí jeho prostředí:
pip install openai 
Nastavte prostředí na Python IDE nebo notebooku pomocí klíče API z účtu OpenAI:
import vyimport getpass
vy . přibližně [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Klíč OpenAI API:' )
Krok 2: Import knihoven
Dalším krokem je získání knihoven z těchto modulů pro použití paměťového retrieveru v LangChain:
z langchain. vyzve import PromptTemplatez čas schůzky import čas schůzky
z langchain. llms import OpenAI
z langchain. vložení . openai import OpenAIEmbeddings
z langchain. řetězy import ConversationChain
z langchain. Paměť import VectorStoreRetrieverMemory
Krok 3: Inicializace Vector Store
Tato příručka používá databázi Chroma po importu knihovny FAISS k extrahování dat pomocí příkazu input:
import faissz langchain. lékárna import InMemoryDocstore
#importing knihovny pro konfiguraci databází nebo vektorových úložišť
z langchain. vectorstores import FAISS
#create vložení a texty pro jejich uložení do vektorových obchodů
embedding_size = 1536
index = faiss. IndexFlatL2 ( embedding_size )
embedding_fn = OpenAIEmbeddings ( ) . embed_query
vectorstore = FAISS ( embedding_fn , index , InMemoryDocstore ( { } ) , { } )
Krok 4: Stavba retrívra s podporou vektorového obchodu
Vytvořte si paměť pro ukládání nejnovějších zpráv v konverzaci a získejte kontext chatu:
retriever = vectorstore. jako_retrívr ( search_kwargs = diktát ( k = 1 ) )Paměť = VectorStoreRetrieverMemory ( retriever = retriever )
Paměť. uložit_kontext ( { 'vstup' : 'Mám rád pizzu' } , { 'výstup' : 'fantastický' } )
Paměť. uložit_kontext ( { 'vstup' : 'Jsem dobrý ve fotbale' } , { 'výstup' : 'OK' } )
Paměť. uložit_kontext ( { 'vstup' : 'Nemám rád politiku' } , { 'výstup' : 'Tak určitě' } )
Otestujte paměť modelu pomocí vstupu poskytnutého uživatelem s jeho historií:
tisk ( Paměť. load_memory_variables ( { 'výzva' : 'Jaký sport bych měl sledovat?' } ) [ 'Dějiny' ] ) 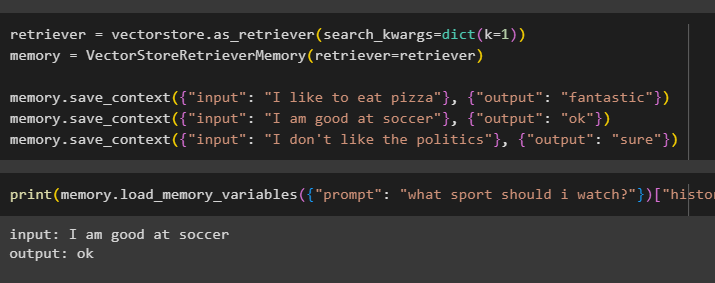
Krok 5: Použití retrívra v řetězci
Dalším krokem je použití paměťového retrieveru s řetězci vytvořením LLM pomocí metody OpenAI() a konfigurací šablony výzvy:
llm = OpenAI ( teplota = 0 )_DEFAULT_TEMPLATE = '''Je to interakce mezi člověkem a strojem
Systém vytváří užitečné informace s podrobnostmi pomocí kontextu
Pokud systém pro vás odpověď nemá, jednoduše řekne, že odpověď nemám
Důležité informace z rozhovoru:
{Dějiny}
(pokud text není relevantní, nepoužívejte jej)
Aktuální chat:
Člověk: {input}
AI:'''
VÝZVA = PromptTemplate (
vstupní_proměnné = [ 'Dějiny' , 'vstup' ] , šablona = _DEFAULT_TEMPLATE
)
#nakonfigurujte metodu ConversationChain() pomocí hodnot jejích parametrů
konverzace_se_souhrnem = ConversationChain (
llm = llm ,
výzva = VÝZVA ,
Paměť = Paměť ,
podrobný = Skutečný
)
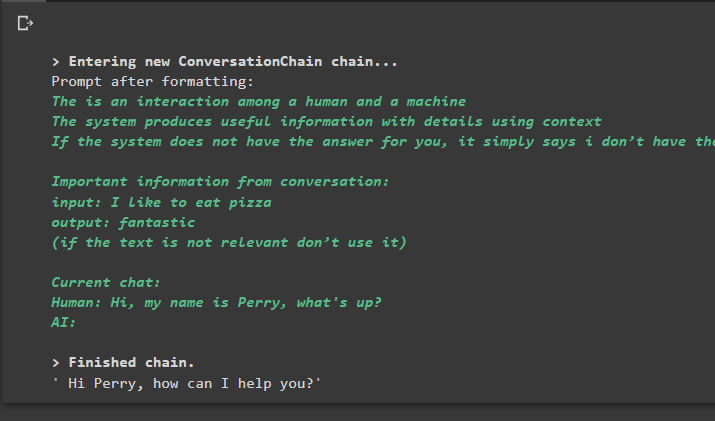
konverzace_se_souhrnem. předpovědět ( vstup = 'Ahoj, jmenuji se Perry, co se děje?' )
Výstup
Provedením příkazu se spustí řetězec a zobrazí se odpověď poskytnutá modelem nebo LLM:
Pokračujte v konverzaci pomocí výzvy založené na datech uložených ve vektorovém úložišti:
konverzace_se_souhrnem. předpovědět ( vstup = 'Jaký je můj oblíbený sport?' ) 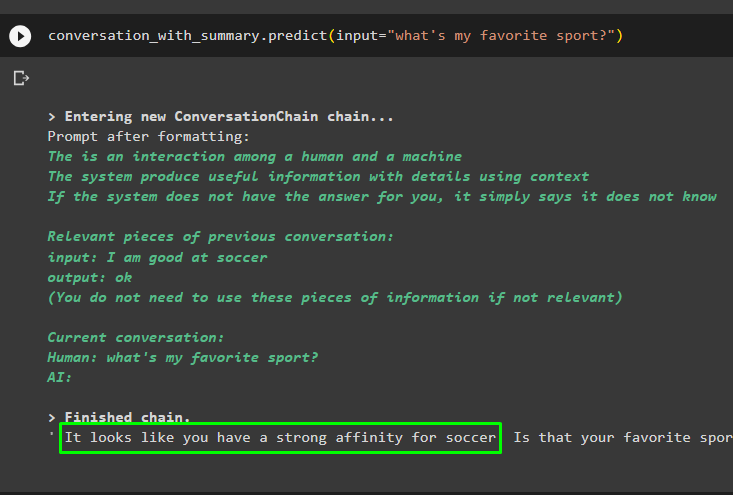
Předchozí zprávy jsou uloženy v paměti modelu, kterou může model použít k pochopení kontextu zprávy:
konverzace_se_souhrnem. předpovědět ( vstup = 'Jaké je moje oblíbené jídlo' ) 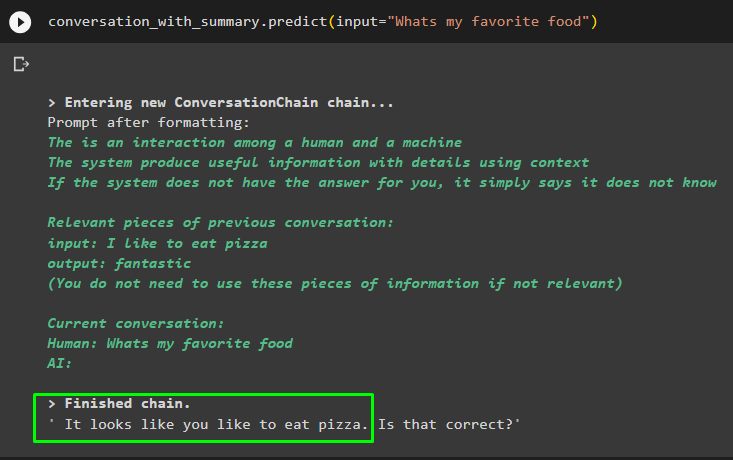
Získejte odpověď poskytnutou modelu v jedné z předchozích zpráv a zkontrolujte, jak paměťový modul pracuje s modelem chatu:
konverzace_se_souhrnem. předpovědět ( vstup = 'Jak se jmenuji?' )Model správně zobrazil výstup pomocí podobnostního vyhledávání z dat uložených v paměti:
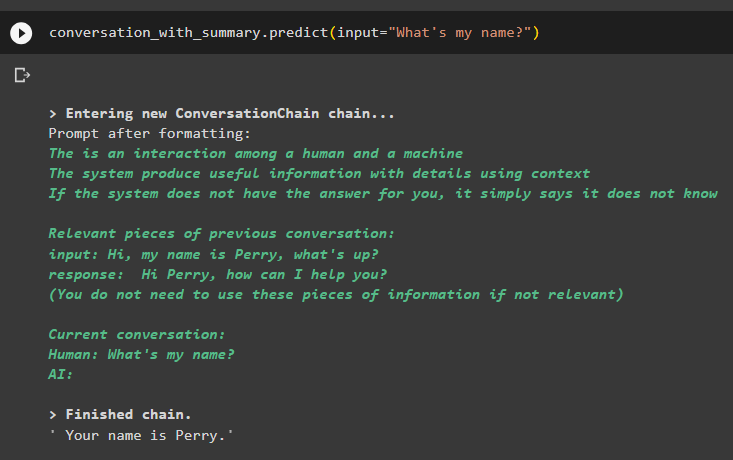
To je vše o použití vektorového retrieveru v LangChain.
Závěr
Chcete-li použít paměťový retriever založený na vektorovém úložišti v LangChain, jednoduše nainstalujte moduly a rámce a nastavte prostředí. Poté naimportujte knihovny z modulů pro sestavení databáze pomocí Chroma a poté nastavte šablonu výzvy. Vyzkoušejte retriever po uložení dat do paměti zahájením konverzace a položením otázek souvisejících s předchozími zprávami. Tato příručka podrobně popisuje proces používání knihovny VectorStoreRetrieverMemory v LangChain.