Najít normální rozložení souboru dat není snadný úkol; můžeme to však provést v MATLABu pomocí fitdist() funkce. Přečtěte si tuto příručku, kde se dozvíte podrobnosti o práci s normální distribuce v MATLABu pomocí fitdist() funkce.
Co je normální distribuce
A normální distribuce také nazývané Gaussovo rozdělení je definováno pomocí dvou parametrů; průměr a standardní odchylka datových bodů. Průměr měří průměr hodnot dat, zatímco standardní odchylka měří, jak jsou hodnoty dat rozloženy kolem průměru. S kombinací střední a standardní odchylky můžeme počítat normální distribuce z následujícího vzorce:
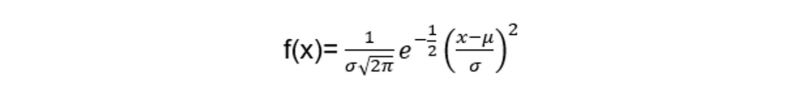
Kde:
- X představuje hodnoty datové sady.
- f(x) představuje pravděpodobnostní funkci.
- m označuje
- p označuje směrodatnou odchylku.
Jak provést normální rozdělení v MATLABu pomocí funkce fitdist().
MATLAB nám umožňuje vypočítat normální distribuce náhodných proměnných pomocí vestavěného fitdist() funkce. Tato funkce vytváří a normální rozdělení pravděpodobnosti objektu přizpůsobením daného rozdělení na vstupní data. The normální distribuce akceptuje jako vstup dva parametry: směrodatnou odchylku i průměr. Standardní normální rozdělení má nulovou střední hodnotu a také jednotkovou směrodatnou odchylku, která je 1. To znamená, že normální distribuce je vycentrován na nulu a hodnoty rozdělení jsou rovnoměrně rozprostřeny na obě strany střední hodnoty.
Syntax
The fitdist() v MATLABu lze použít různými způsoby:
pd = fitdista ( X , distname )
pd = fitdista ( X , distname , název , Hodnota )
pdca , gn , gl ] = fitdista ( X , distname , 'Podle' , groupvar )
Tady:
- Funkce pd = fitdist(x,distname) je zodpovědný za přizpůsobení distribuce poskytnuté distname datům obsaženým ve sloupcovém vektoru x za účelem vytvoření objektu rozdělení pravděpodobnosti.
- Funkce pd = fitdist(x,distname,name,value) je zodpovědný za vytvoření objektu rozdělení pravděpodobnosti s jedním nebo více argumenty páru název-hodnota, které specifikují další parametry.
- Funkce [pdca,gn,gl] = fitdist(x,distname,‘By‘,groupvar) je zodpovědný za přizpůsobení rozdělení pravděpodobnosti definované distname datům ve sloupcovém vektoru x na základě seskupovací proměnné groupvar za účelem generování objektů rozdělení pravděpodobnosti. Poskytuje zpět pole buněk přizpůsobených objektů rozdělení pravděpodobnosti, označovaných jako pdca, pole buněk skupinových štítků, označovaných jako gn, a pole buněk seskupujících proměnných úrovní, označovaných jako gl.
Příklad 1: Jak najít normální rozdělení pomocí funkce fitdist(x,distname).
Tento příklad odpovídá a normální distribuce na vzorová data z pomocí fitdist() funkce.
zatěžovat pacientyS = Hmotnost ;
pd = fitdista ( S , 'Normální' )
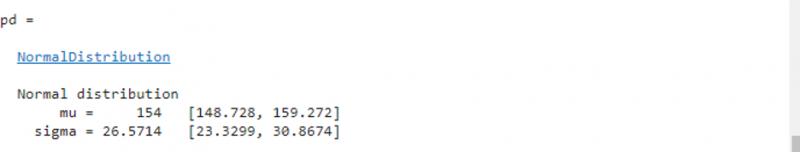
Příklad 2: Jak najít normální distribuci pomocí fitdist(x,distname,Name,Value) Funkce
V tomto příkladu se chystáme přizpůsobit distribuci jádra vzorovým datům pomocí fitdist() funkce v MATLABu.
zatěžovat pacientyS = Hmotnost ;
pd = fitdista ( S , 'Jádro' , 'Jádro' , 'epanechnikov' )

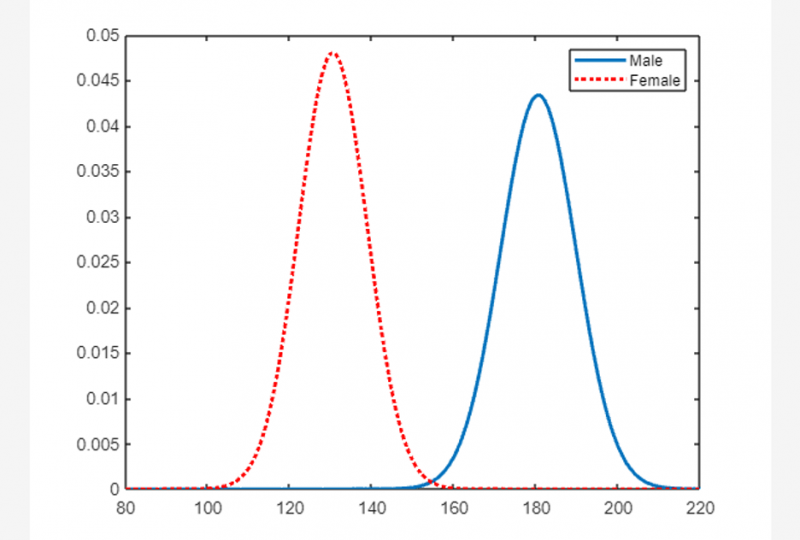
Příklad 3: Jak najít normální rozdělení pomocí funkce fitdist(x,distname,‘By‘,groupvar)
Níže uvedený kód MATLABu sedí normální distribuce na seskupená data, vypočítá a vykreslí pdf obou skupin dat.
zatěžovat pacientyS = Hmotnost ;
[ pdca , gn , gl ] = fitdista ( S , 'Normální' , 'Podle' , Rod )
ženský = pdca { 1 }
mužský = pdca { 2 }
z_hodnoty = 80 : 1 : 220 ;
ženapdf = pdf ( ženský , z_hodnoty ) ;
malepdf = pdf ( mužský , z_hodnoty ) ;
postava
spiknutí ( z_hodnoty , ženapdf , 'Šířka čáry' , 2 )
vydrž
spiknutí ( z_hodnoty , malepdf , 'Barva' , 'r' , 'LineStyle' , ':' , 'Šířka čáry' , 2 )
legenda ( gn , 'Umístění' , 'Severovýchod' )
zdržet se

Závěr
Nalezení normální distribuce datové sady je statistická technika, která se široce používá ve strojovém učení, umělé inteligenci, datové vědě a mnoha dalších oblastech. Lze jej definovat pomocí dvou parametrů; průměr i standardní odchylka datových bodů. Můžeme datovou sadu vměstnat do normální distribuce objekt pomocí fitdist() funkce. Tato příručka poskytla základy normální distribuce a jak s ní pracovat v MATLABu pomocí funkce fitdist() funkce.