Příklad 1:
„iostream“ je zde prvním hlavičkovým souborem, kde jsou deklarovány funkce C++. Poté přidáme hlavičkový soubor „vector“, který je zde obsažen, abychom mohli pracovat s vektorem a funkcí pro práci s vektory. Potom „std“ je jmenný prostor, který zde vložíme, takže tento „std“ se všemi funkcemi nemusíme vkládat jednotlivě do tohoto kódu. Poté se zde vyvolá „main()“. Pod tím vytvoříme vektor datového typu „int“ s názvem „myNewData“ a vložíme do něj nějaké celočíselné hodnoty.
Poté vložíme smyčku „for“ a použijeme do ní klíčové slovo „auto“. Nyní tento iterátor zjistí datový typ hodnot zde. Získáme hodnoty vektoru „myNewData“ a uložíme je do proměnné „data“ a také je zde zobrazíme, když tato „data“ přidáme do „cout“.
Kód 1:
#include
#include
použitím jmenný prostor std ;
int hlavní ( ) {
vektor < int > mojeNováData { jedenáct , 22 , 33 , 44 , 55 , 66 } ;
pro ( auto data : mojeNováData ) {
cout << data << endl ;
}
}
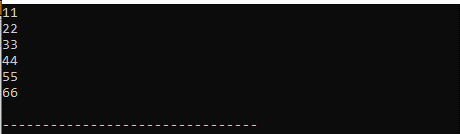
Výstup :
Viděli jsme všechny hodnoty tohoto vektoru, které jsou zde vytištěny. Tyto hodnoty vytiskneme pomocí cyklu „for“ a umístěním klíčového slova „auto“ do něj.
Příklad 2:
Zde přidáme „bits/stdc++.h“, protože obsahuje všechny deklarace funkcí. Poté sem vložíme jmenný prostor „std“ a poté vyvoláme „main()“. Pod tím inicializujeme „množinu“ „řetězec“ a pojmenujeme ji jako „myString“. Do něj pak v dalším řádku vložíme data řetězce. Do této sady vložíme některá jména ovoce pomocí metody „insert()“.
Pod tím použijeme smyčku „for“ a do ní vložíme klíčové slovo „auto“. Poté inicializujeme iterátor s názvem „my_it“ s klíčovým slovem „auto“ a přiřadíme mu „myString“ spolu s funkcí „begin()“.
Poté umístíme podmínku, která je „my_it“, která se nerovná „myString.end()“ a zvýšíme hodnotu iterátoru pomocí „my_it++“. Poté umístíme „*my_it“ do „cout“. Nyní tiskne názvy ovoce podle abecedního pořadí a datový typ je detekován automaticky, když jsme sem umístili klíčové slovo „auto“.
Kód 2:
#includepoužitím jmenný prostor std ;
int hlavní ( )
{
soubor < tětiva > myString ;
myString. vložit ( { 'Hrozny' , 'Oranžový' , 'Banán' , 'Hruška' , 'Jablko' } ) ;
pro ( auto my_it = myString. začít ( ) ; my_it ! = myString. konec ( ) ; my_it ++ )
cout << * my_it << '' ;
vrátit se 0 ;
}
Výstup:
Zde si můžeme všimnout, že názvy ovoce jsou zobrazeny v abecedním pořadí. Zde jsou vykreslena všechna data, která jsme vložili do sady řetězců, protože jsme v předchozím kódu použili „for“ a „auto“.

Příklad 3:
Protože „bits/stdc++.h“ již má všechny deklarace funkcí, přidáme je sem. Po přidání jmenného prostoru „std“ zavoláme z tohoto umístění „main()“. „Množina“ „int“, kterou jsme stanovili v následujícím textu, se nazývá „myIntegers“. Poté přidáme celočíselná data do řádku, který následoval. K přidání několika celých čísel do tohoto seznamu používáme metodu „insert()“. Klíčové slovo „auto“ je nyní vloženo do smyčky „for“, která se používá pod ním.
Dále použijeme klíčové slovo „auto“ k inicializaci iterátoru s názvem „new_it“ a přiřadíme mu funkce „myIntegers“ a „begin()“. Dále nastavíme podmínku, která říká, že „my_it“ se nesmí rovnat „myIntegers.end()“ a použijeme „new_it++“ ke zvýšení hodnoty iterátoru. Dále vložíme „*new_it“ do této sekce „cout“. Tiskne celá čísla vzestupně. Po vložení klíčového slova „auto“ automaticky detekuje typ dat.
Kód 3:
#includepoužitím jmenný prostor std ;
int hlavní ( )
{
soubor < int > moje celá čísla ;
moje celá čísla. vložit ( { Čtyři pět , 31 , 87 , 14 , 97 , dvacet jedna , 55 } ) ;
pro ( auto new_it = moje celá čísla. začít ( ) ; new_it ! = moje celá čísla. konec ( ) ; new_it ++ )
cout << * new_it << '' ;
vrátit se 0 ;
}
Výstup :
Celá čísla jsou zde uvedena ve vzestupném pořadí, jak je vidět dále. Protože jsme v předchozím kódu použili výrazy „for“ a „auto“, všechna data, která jsme umístili do sady celých čísel, se vykreslí zde.

Příklad 4:
Při práci s vektory jsou zahrnuty hlavičkové soubory „iostream“ a „vector“. Poté se přidá jmenný prostor „std“ a poté zavoláme „main()“. Poté inicializujeme vektor datového typu „int“ s názvem „myVectorV1“ a do tohoto vektoru přidáme nějaké hodnoty. Nyní umístíme smyčku „for“ a zde použijeme „auto“ k detekci datového typu. Přistupujeme podle hodnot vektoru a poté je vytiskneme umístěním „valueOfVector“ do „cout“.
Poté do něj vložíme další „for“ a „auto“ a inicializujeme je pomocí „&& valueOfVector : myVectorV1“. Zde přistupujeme pomocí odkazu a poté vytiskneme všechny hodnoty vložením „valueOfVector“ do „cout“. Nyní nemusíme vkládat datový typ pro obě smyčky, protože uvnitř smyčky používáme klíčové slovo „auto“.
Kód 4:
#include#include
použitím jmenný prostor std ;
int hlavní ( ) {
vektor < int > myVectorV1 = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
pro ( auto valueOfVector : myVectorV1 )
cout << valueOfVector << ' ' ;
cout << endl ;
pro ( auto && valueOfVector : myVectorV1 )
cout << valueOfVector << ' ' ;
cout << endl ;
vrátit se 0 ;
}
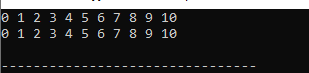
Výstup:
Zobrazí se všechna data vektoru. Čísla, která jsou zobrazena v prvním řádku, jsou čísla, ke kterým jsme přistupovali pomocí hodnot, a čísla, která jsou zobrazena na druhém řádku, jsou čísla, ke kterým jsme přistupovali odkazem v kódu.
Příklad 5:
Po volání metody „main()“ v tomto kódu inicializujeme dvě pole, která jsou „myFirstArray“ velikosti „7“ s datovým typem „int“ a „mySecondArray“ s velikostí „7“ z „double“ datový typ. Hodnoty vložíme do obou polí. Do prvního pole vložíme hodnoty „integer“. Do druhého pole přidáme hodnoty „double“. Poté použijeme „for“ a do této smyčky vložíme „auto“.
Zde používáme smyčku „range base for“ pro „myFirstArray“. Poté umístíme „myVar“ do „cout“. Pod to opět umístíme smyčku a využijeme smyčku „range base for“. Tato smyčka je pro „mySecondArray“ a pak také vytiskneme hodnoty tohoto pole.
Kód 5:
#includepoužitím jmenný prostor std ;
int hlavní ( )
{
int myFirstArray [ 7 ] = { patnáct , 25 , 35 , Čtyři pět , 55 , 65 , 75 } ;
dvojnásobek mySecondArray [ 7 ] = { 2.64 , 6.45 , 8.5 , 2.5 , 4.5 , 6.7 , 8.9 } ;
pro ( konst auto & myVar : myFirstArray )
{
cout << myVar << '' ;
}
cout << endl ;
pro ( konst auto & myVar : mySecondArray )
{
cout << myVar << '' ;
}
vrátit se 0 ;
}
Výstup:
V tomto výsledku jsou zde zobrazena všechna data obou vektorů.

Závěr
Koncept „pro auto“ je v tomto článku důkladně prostudován. Vysvětlili jsme, že „auto“ detekuje datový typ, aniž by to bylo zmíněno. V tomto článku jsme prozkoumali několik příkladů a také zde poskytli vysvětlení kódu. V tomto článku jsme hluboce vysvětlili fungování tohoto konceptu „pro auto“.