V tomto tutoriálu se seznámíme s fungováním klauzule PARTITION BY v SQL a zjistíme, jak ji můžeme použít k rozdělení dat pro podrobnější podmnožinu.
Syntax:
Začněme syntaxí klauzule PARTITION BY. Syntaxe může záviset na kontextu, ve kterém ji používáte, ale zde je obecná syntaxe:
VYBRAT sloupec1, sloupec2, ...
PŘES (PARTITION BY partition_column1, partition_column2, ...)
FROM název_tabulky
Daná syntaxe představuje následující prvky:
- sloupec1, sloupec2 – odkazuje na sloupce, které chceme zahrnout do sady výsledků.
- ROZDĚLENÍ PODLE sloupců – Tato klauzule definuje, jak chceme data rozdělit nebo seskupit.
Vzorek dat
Vytvořme základní tabulku s ukázkovými daty, abychom ukázali, jak používat klauzuli PARTITION BY. Pro tento příklad vytvoříme základní tabulku, která ukládá informace o produktu.
CREATE TABLE produkty (
product_id INT PRIMARY KEY AUTO_INCREMENT,
název_produktu VARCHAR( 255 ),
kategorie VARCHAR( 255 ),
cena DECIMAL( 10 , 2 ),
množství INT,
expiration_date DATE,
čárový kód VELKÝ
);
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Kuchařská čepice 25 cm' ,
'pekařství' ,
24,67 ,
57 ,
'2023-09-09' ,
2854509564204 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( „Křepelčí vejce – konzerva“ ,
'spíž' ,
17,99 ,
67 ,
'2023-09-29' ,
1708039594250 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Káva – vaječný likér capuccino' ,
'pekařství' ,
92,53 ,
10 ,
'2023-09-22' ,
8704051853058 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Hruška - pichlavý' ,
'pekařství' ,
65,29 ,
48 ,
'2023-08-23' ,
5174927442238 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Těstoviny - andělské vlasy' ,
'spíž' ,
48,38 ,
59 ,
'2023-08-05' ,
8008123704782 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Víno - Prosecco Valdobiaddene' ,
'vyrobit' ,
44,18 ,
3 ,
'2023-03-13' ,
6470981735653 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Pečivo - francouzské mini různé' ,
'spíž' ,
36,73 ,
52 ,
'2023-05-29' ,
5963886298051 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( „Pomeranč – konzerva, mandarinka“ ,
'vyrobit' ,
65,0 ,
1 ,
'2023-04-20' ,
6131761721332 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Vepřové rameno' ,
'vyrobit' ,
55,55 ,
73 ,
'2023-05-01' ,
9343592107125 );
vložit
do
produkty (název_produktu,
kategorie,
cena,
Množství,
Datum spotřeby,
čárový kód)
hodnoty ( 'Dc Hikiage Hira Huba' ,
'vyrobit' ,
56,29 ,
53 ,
'2023-04-14' ,
3354910667072 );
Jakmile máme vzorové nastavení dat, můžeme pokračovat a použít klauzuli PARTITION BY.
Základní použití
Předpokládejme, že chceme vypočítat celkový počet položek pro každou kategorii produktů v předchozí tabulce. Můžeme použít PARTITION BY k rozdělení položek do jedinečných kategorií a pak určit celkové množství v každé kategorii.
Příklad je následující:
VYBRAT
jméno výrobku,
kategorie,
Množství,
SUM(množství) NAD (ODDĚLENÍ PODLE kategorie) JAKO celkem_položek
Z
produkty;
Všimněte si, že v daném příkladu rozdělujeme data pomocí sloupce „kategorie“. Potom pomocí agregační funkce SUM() určíme celkový počet položek v každé kategorii samostatně. Výsledek ukazuje celkový počet položek v každé kategorii.
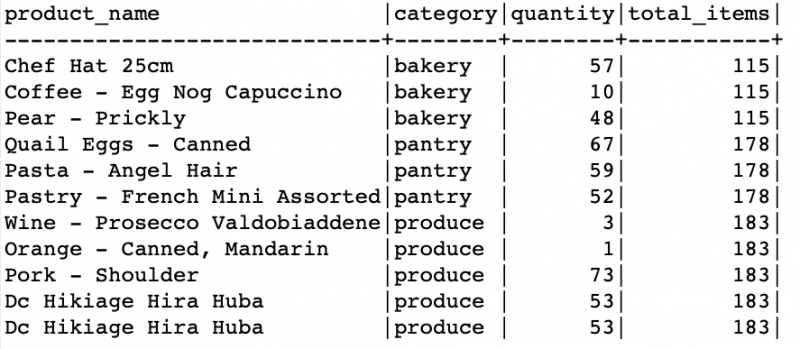
Použití klauzule PARTITION BY
Abychom to shrnuli, nejběžnějším případem použití klauzule PARTITION BY je spojení s funkcemi okna. Funkce okna se aplikuje na každý oddíl samostatně.
Některé z běžných funkcí okna, které lze použít s PARTITION BY, zahrnují následující:
- SUM() – Výpočet součtu sloupců v každém oddílu.
- AVG() – Vypočítá průměr sloupce v každém oddílu.
- COUNT() – Spočítá počet řádků v každém oddílu.
- ROW_NUMBER() – Přiřaďte jedinečné číslo řádku každému řádku v rámci každého oddílu.
- RANK() – Přiřaďte hodnocení každému řádku v každém oddílu.
- DENSE_RANK() – Přiřadí hustotu každému řádku v rámci každého oddílu.
- NTILE() – Rozdělte data do kvantilů v rámci každého oddílu.
A je to!
Závěr
V tomto tutoriálu jsme se naučili, jak pracovat s klauzulí PARTITION BY v SQL k rozdělení dat do různých segmentů a poté aplikovat konkrétní operaci na každý z výsledných oddílů samostatně.