C++ je známo, že je jedním z nejrychlejších programovacích jazyků s dobrým výkonem, vysokou přesností a adekvátním systémem správy paměti. Tento programovací jazyk také podporuje souběžné provádění více vláken se sdílením více zdrojů mezi nimi. V multithreadingu má vlákno pouze provést operaci čtení, která nezpůsobuje žádné problémy, protože vlákno není ovlivněno tím, co v tu chvíli dělají ostatní vlákna. Ale pokud tato vlákna musela sdílet prostředky mezi sebou, jedno vlákno může v té době upravit data, což způsobuje problém. K vyřešení tohoto problému máme C++ „Mutex“, který zabraňuje přístupu více zdrojů k našemu kódu/objektu tím, že poskytuje synchronizaci, která říká, že přístup k objektu/kódu může být poskytnut pouze jednomu vláknu najednou, takže k tomuto objektu nebude mít přístup více vláken současně.
Postup:
Dozvíme se, jak můžeme zastavit přístup více vláken k objektu najednou pomocí zámku mutex. Budeme hovořit o syntaxi zámku mutexu, o tom, co je vícenásobné vlákno a jak se můžeme vypořádat s problémy způsobenými vícenásobným závitem pomocí zámku mutex. Poté si vezmeme příklad vícenásobného vlákna a implementujeme na ně zámek mutexu.
Syntax:
Pokud se chceme naučit, jak implementovat zámek mutex, abychom mohli zabránit přístupu více vláken současně k našemu objektu nebo kódu, můžeme použít následující syntaxi:
$ std :: mutex mut_x
$mut_x. zámek ( ) ;
Void func_name ( ) {
$ // zde bude napsán kód, který chceme skrýt před více vlákny
$mut_x. odemkne ( ) ;
}
Tuto syntaxi nyní použijeme na fiktivním příkladu a v pseudo kódu (který nemůžeme spustit tak, jak je v editoru kódu), abychom vám dali vědět, jak můžeme přesně použít tuto syntaxi, jak je uvedeno níže:
$ std :: mutex mut_x
Prázdný blok ( ) {
$mut_x. zámek ( ) ;
$ std :: cout << 'Ahoj' ;
$mut_x. odemkne ( ) ;
}
Příklad:
V tomto příkladu se pokusme nejprve vytvořit vícevláknovou operaci a poté tuto operaci obklopit uzamčením a odemknutím mutexu, abychom zajistili synchronizaci operace s vytvořeným kódem nebo objektem. Mutex se zabývá podmínkami závodu, což jsou hodnoty, které jsou zcela nepředvídatelné a jsou závislé na přepínání vláken, která jsou časově závislá. Abychom mohli implementovat příklad pro mutex, musíme nejprve importovat důležité a požadované knihovny z repozitářů. Požadované knihovny jsou:
$ # include
$ # include
$ # include
Knihovna „iostream“ nám poskytuje funkci pro zobrazení dat jako Cout, čtení dat jako Cin a ukončení příkazu jako endl. K využití programů nebo funkcí z vláken používáme knihovnu „vlákno“. Knihovna „mutex“ nám umožňuje implementovat do kódu jak zámek, tak odemknutí mutexu. Používáme „# include“, protože to umožňuje všechny programy související s knihovnou obsaženou v kódu.
Nyní, po provedení předchozího kroku, definujeme třídu mutexu nebo globální proměnnou pro mutex pomocí std. Poté vytvoříme funkci pro zamykání a odemykání mutexu, kterou bychom mohli později zavolat v kódu. V tomto příkladu tuto funkci pojmenujeme jako blok. V těle funkce bloku nejprve zavoláme „mutex.lock()“ a začneme psát logiku kódu.
Mutex.lock() odepře přístup ostatním vláknům k dosažení našeho vytvořeného objektu nebo kódu, takže pouze jedno vlákno může číst náš objekt najednou. V logice spustíme cyklus for, který běží na indexu od 0 do 9. Zobrazíme hodnoty v cyklu. Jakmile je tato logika vytvořena v zámku mutex po provedení jeho operace nebo po ukončení logiky, zavoláme metodu „mutex.unlock()“. Toto volání metody nám umožňuje odemknout vytvořený objekt ze zámku mutex, protože přístup objektu k jednomu jedinému vláknu byl poskytnut dříve a jakmile je operace na tomto objektu provedena jedním vláknem najednou. Nyní chceme, aby k tomuto objektu nebo kódu měla přístup i ostatní vlákna. Jinak se náš kód pohybuje v situaci „zablokování“, což způsobí, že vytvořený objekt s mutexem zůstane navždy v uzamčené situaci a žádné jiné vlákno by k tomuto objektu nemělo přístup. Neúplná operace se tedy stále provádí. Poté opustíme funkci bloku a přesuneme se do hlavního.
V podstatě jednoduše zobrazíme náš vytvořený mutex vytvořením tří vláken pomocí „std :: vlákno název_vlákna (zde voláme již vytvořenou blokovou funkci, ve které jsme vytvořili mutex)“ s názvy vlákno1, vlákno2 a vlákno3 atd. Tímto způsobem se vytvoří tři vlákna. Poté spojíme tato tři vlákna, aby byla spuštěna současně, voláním „jméno_vlákna. metoda join ()“. A pak vrátíme hodnotu rovnou nule. Výše uvedené vysvětlení příkladu je implementováno ve formě kódu, který lze zobrazit na následujícím obrázku:
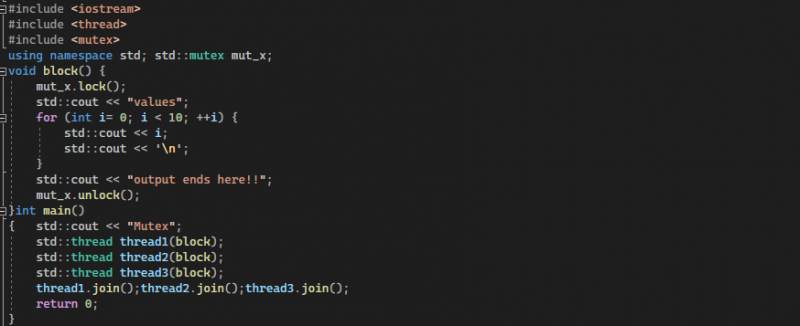
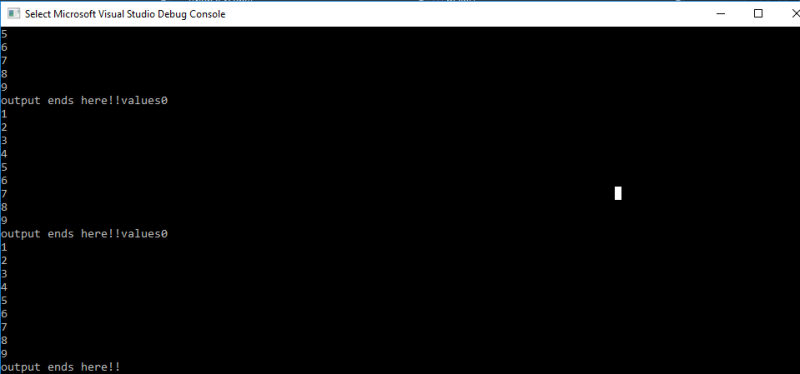
Ve výstupu kódu můžeme vidět spuštění a zobrazení všech tří vláken jedno po druhém. Vidíme, i když naše aplikace spadá do kategorie multithreadingu. Přesto žádné z vláken nepřepsalo ani neupravilo data a nesdílelo upravený prostředek kvůli implementaci mutexu „funkčního bloku“.
Závěr
Tato příručka poskytuje podrobné vysvětlení konceptu funkce mutex používané v C++. Diskutovali jsme o tom, co jsou to multithreadingové aplikace, s jakými problémy se v multithreadingových aplikacích musíme setkat a proč potřebujeme implementovat mutex pro multithreadingové aplikace. Poté jsme diskutovali o syntaxi mutexu s fiktivním příkladem pomocí pseudokódu. Poté jsme implementovali kompletní příklad na multithreadingových aplikacích s mutexem ve vizuálním studiu C++.