„Comma-Separated Values (CSV) je jedním z nejuniverzálnějších a nejsnáze použitelných datových formátů. Jedná se o odlehčený datový formát, který umožňuje vývojářům a aplikacím přenášet a analyzovat data z jednoho zdroje do druhého.
Data CSV ukládají data v tabulkovém formátu, kde je každý sloupec oddělen čárkou a nový záznam je přidělen novému řádku. Díky tomu je velmi dobrou volbou pro export databází, jako jsou databáze SQL, data Cassandra a další.
Není proto žádným překvapením, že se setkáte se scénářem, kdy potřebujete importovat soubor CSV do databáze.
Cílem tohoto tutoriálu je ukázat vám rychlou a jednoduchou metodu importu souboru CSV do clusteru Elasticsearch pomocí řídicího panelu Kibana.“
Pojďme do toho.
Požadavky
Před potápěním se ujistěte, že máte následující požadavky:
- Klastr Elasticsearch se zeleným zdravotním stavem.
- Server Kibana připojený k vašemu clusteru Elasticsearch.
- Dostatečná oprávnění ke správě indexů ve vašem clusteru.
Ukázkový soubor CSV
Jako obvykle je prvním požadavkem váš zdrojový soubor CSV. Je dobré zajistit, aby data ve vašem CSV souboru byla dobře naformátovaná a neobsahovala žádné chyby.
Pro ilustrační účely použijeme bezplatný datový soubor, který obsahuje filmy a televizní pořady od Amazon Prime.
Otevřete prohlížeč a přejděte na zdroj níže:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Postupujte podle pokynů pro stažení datové sady do místního počítače. Stažený archiv můžete extrahovat příkazem:
$ rozepnout a~ / Stahování / archiv.zip
Importovat soubor CSV
Jakmile budete mít zdrojový soubor připravený, můžeme pokračovat a probrat, jak jej importovat.
Začněte tím, že přejdete na svůj domovský panel Kibana a vyberete možnost „nahrát soubor“.
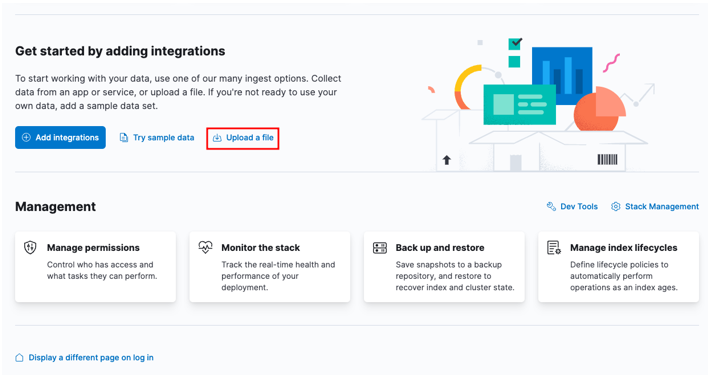
V okně spouštěče vyhledejte cílový soubor CSV, který chcete importovat.
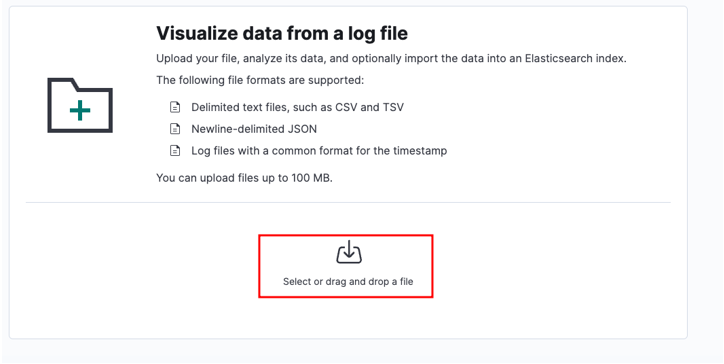
Vyberte zdrojový soubor a klikněte na nahrát.
Umožněte Elasticsearch a Kibana analyzovat nahraný soubor. Tím se analyzuje soubor CSV a určí se formát dat, pole, typy dat atd.
POZNÁMKA: V závislosti na konfiguraci clusteru a velikosti dat může tento proces chvíli trvat. Ujistěte se, že hlavní uzel odpovídá, abyste se vyhnuli časovým limitům.
Po dokončení procesu byste měli získat vzorek obsahu vašeho souboru a statistiku souboru, jak je analyzuje Elastic.
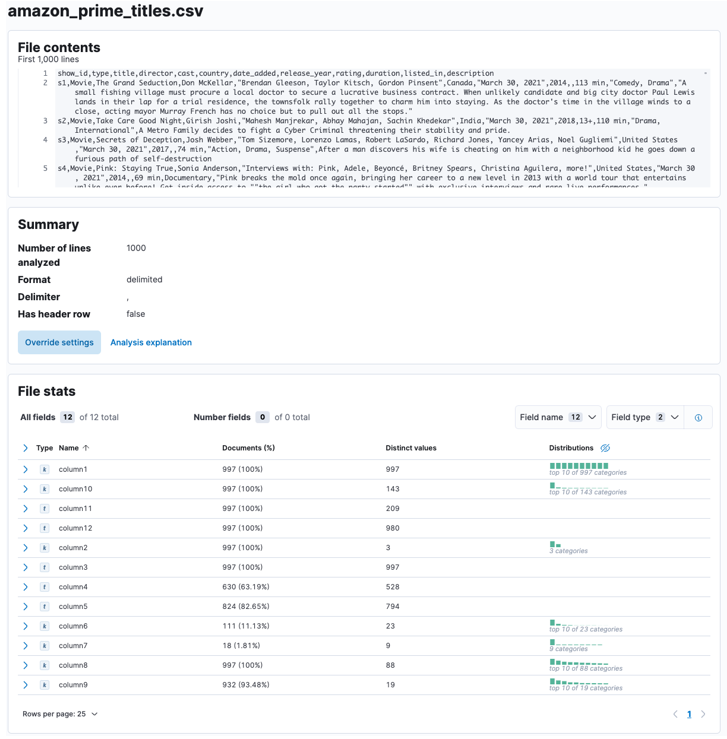
Můžete přizpůsobit řadu parametrů, například oddělovač, řádky záhlaví atd. Můžeme například přizpůsobit výstup výše, abychom Elasticovi řekli, že náš soubor CSV obsahuje soubory záhlaví.
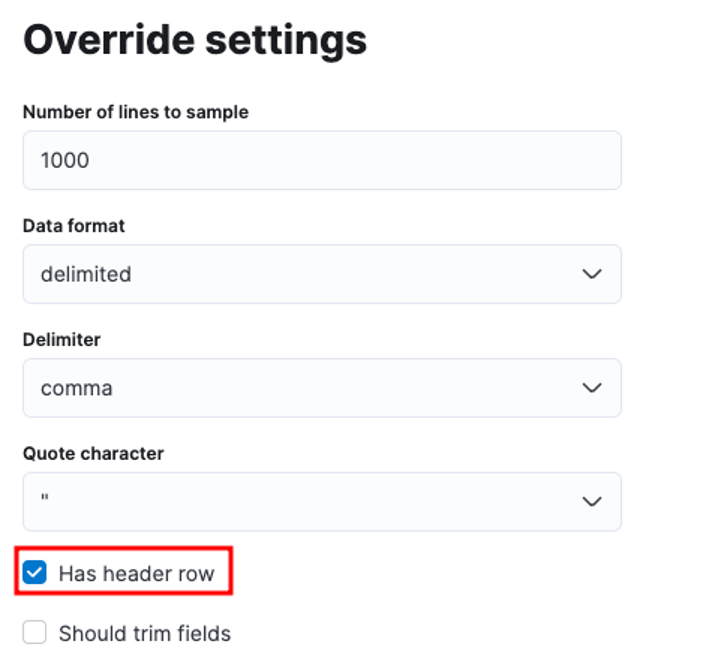
Poté můžeme kliknout na použít a znovu analyzovat data. To by mělo formátovat data ve správném formátu, včetně polí.
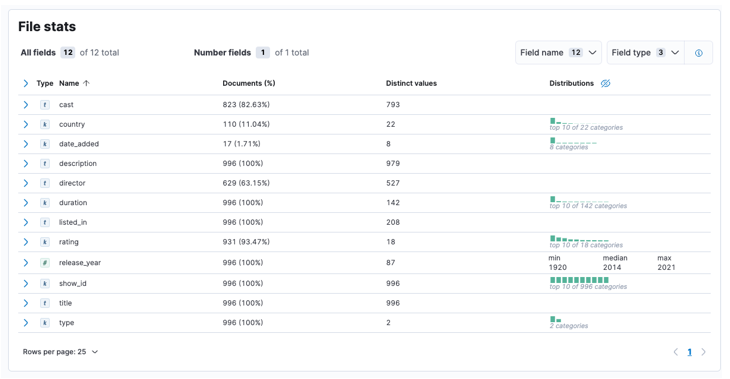
Dále můžeme kliknout na import a přejít na importovaný řídicí panel.
Zde musíme vytvořit index, ve kterém jsou uložena data CSV. Svému indexu můžete přiřadit jakýkoli podporovaný název.
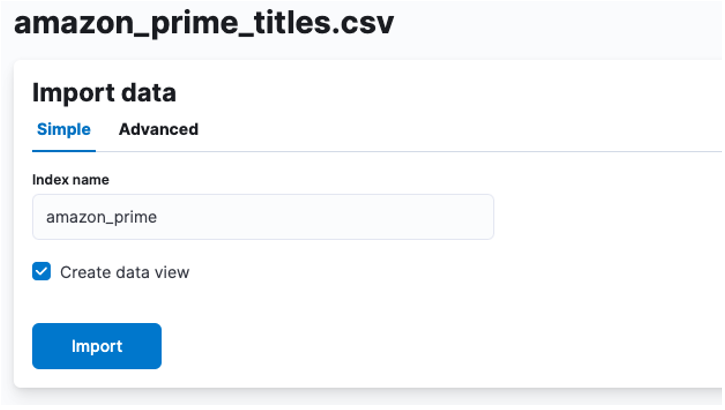
Pokud si přejete upravit vlastnosti svého indexu, jako je počet útržků, replik, mapování atd. Vyberte pokročilou možnost a upravte nastavení podle svého srdce.
Nakonec klikněte na import a sledujte, jak Kibana dělá svá „kouzla“. Po dokončení můžete ke svému indexu přistupovat buď prostřednictvím rozhraní Elasticsearch API, nebo pomocí řídicího panelu Kibana.
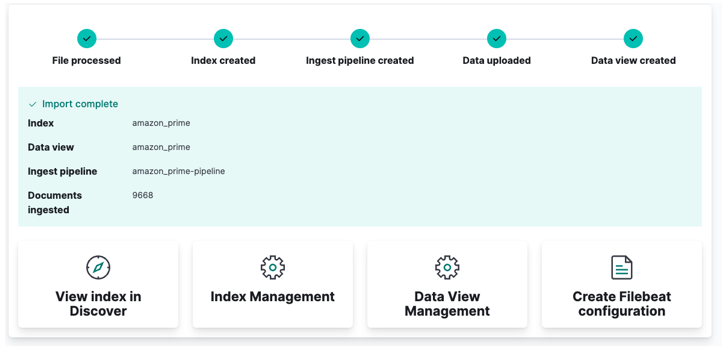
A máte hotovo!!
Závěr
V tomto příspěvku jsme se zabývali procesem načítání a importu vaší datové sady CSV do vašeho clusteru Elasticsearch pomocí řídicího panelu Kibana.
Díky za přečtení a hodně štěstí při kódování!!