Kýl (Knowledge Extraction based on Evolutionary Learning) je softwarový nástroj založený na Javě, který se specializuje na implementaci evolučních algoritmů. Vzhledem k tomu, že se jedná o otevřený zdroj, poskytuje širokou škálu algoritmů pro zjišťování znalostí, které lze použít v experimentech, které pohání komunitu dolování a analýzy dat. Poskytuje jednoduché a snadno použitelné grafické uživatelské rozhraní, které výrazně snižuje celkovou složitost tohoto nástroje. Většina podobných nástrojů na trhu vyžaduje, aby s nimi uživatelé komunikovali psaním kódu, zatímco Keel tento požadavek odstraňuje tím, že poskytuje intuitivní GUI, které mohou používat začátečníci i odborníci.
Keel poskytuje širokou škálu různých algoritmů založených na výpočetní inteligenci včetně klasifikace, regrese, extrakce rysů, analýzy vzorů, shlukování a dalších. S mainstreamovými modely zapečenými přímo do samotné aplikace je Keel velmi užitečným nástrojem, pokud jde o provádění průzkumných datových analýz na souborech nezpracovaných dat. Jeho jednoduché rozhraní drag and drop spárované se snadným využitím funkcí umožňuje rychlé a efektivní experimentování s dolováním dat pro vzdělávací i výzkumné účely. Nástroje jako Keel jsou stále oblíbenější kvůli jejich zjednodušenému přístupu k jinak složitým algoritmickým postupům.
Instalace
Existují dva hlavní způsoby, jak můžeme nainstalovat Kýl na libovolném počítači se systémem Linux. První zahrnuje jít do Webová stránka Keel a stažení softwaru odtud. Druhý, který budeme následovat v této instalační příručce, vyžaduje, abychom si stáhli Keel pomocí wget nástroj ke stažení dostupný pro uživatele Linuxu.
1. Začneme získáním wget na našem linuxovém stroji.
Spusťte následující příkaz ke stažení wget pomocí apt správce balíčků:
$ sudo instalace apt-get wget
Uvidíte podobný výstup terminálu:
2. Nyní, když máme wget nástroj nainstalovaný na našem počítači se systémem Linux, používáme jej ke stažení Kýl nástroj.
To je odkaz které předáme wget.
Spusťte ve svém terminálu následující příkaz:
$ wget http: // sci2s.ugr.es / kýl / software / prototypy / openVersion / Software- 2018 -04-09.zip
Na vašem terminálu byste měli vidět podobný výstup:
Jakmile Keel dokončí stahování, můžeme pokračovat ve zbytku instalace.
3. Nyní rozbalíme komprimovaný soubor, který jsme stáhli v předchozím kroku pomocí nástroje Linux Unzip.
Spusťte následující příkaz:
$ rozepnout Software- 2018 -04-09.zip
V terminálu byste měli vidět podobný výstup:
4. Spuštěním následujícího příkazu přejděte do složky Keel:
$ CD Software- 2018 -04-09 / dokumenty / experimenty / KÝL / dist /
5. Spusťte následující příkaz pro zahájení instalace:
$ Jáva -sklenice . / GraphInterKeel.jar
Díky tomu by měl být Keel k dispozici pro použití na vašem počítači se systémem Linux.
Uživatelská příručka
Interakce s Kýl aplikace je opravdu snadná a jednoduchá. Začněme importem Datový soubor Iris do našeho pracovního prostoru.
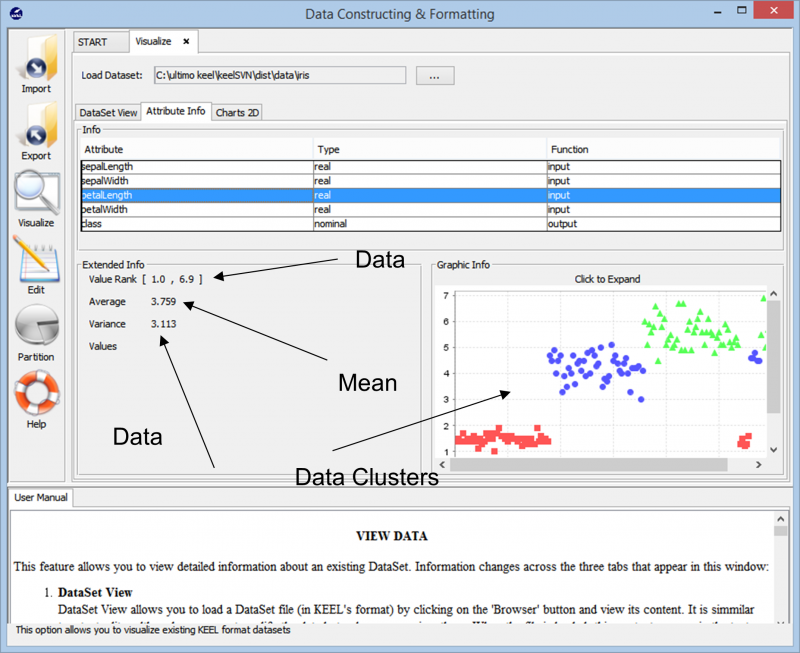
Při importu dat nám nástroj ukazuje celkové shlukování datového bodu v sadě dat. Ukazuje nám také různé třídy, které jsou přítomné v sadě dat, spolu se základními informacemi, jako jsou číselné rozsahy, které tyto datové body zahrnují, a celkový rozptyl a střední hodnoty, které představují. Tyto informace umožňují uživatelům lépe pochopit, jak postupovat při přípravě dat pro jakýkoli druh úlohy analýzy dat.
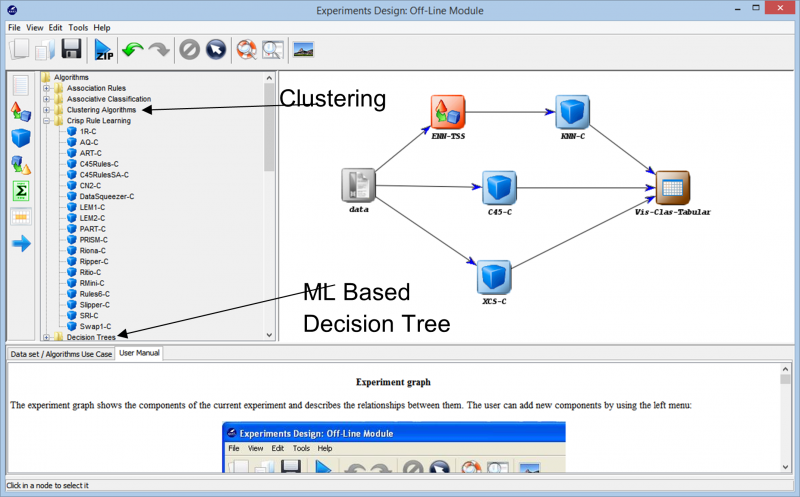
Když budeme pokračovat dále v experimentování, narazíme na různé techniky, které lze použít k vytvoření našeho experimentu na jakémkoli souboru dat. Různé algoritmy učení, které lze použít na naše data, můžete vidět na následujícím obrázku. V závislosti na povaze souboru dat a požadavcích experimentu lze experimentovat s různými algoritmy.
Pokud například pracujete s neoznačenými daty a musíte najít podobnosti mezi různými datovými body ve vaší datové sadě, použití shlukovacího algoritmu z různých dostupných možností vám může pomoci lépe porozumět datovým bodům. To vám nakonec pomůže označit a klasifikovat datové body, aby mohl být experiment postaven na použití komplexnějších algoritmů učení pod dohledem.
Závěr
The Kýl platforma pro analýzu dat je dobrým zdrojem pro výzkumné i vzdělávací účely. Jeho snadno použitelné grafické uživatelské rozhraní pomáhá uživatelům lépe porozumět požadavkům na data a poskytuje logické odkazy na užitečné techniky a algoritmy, které uživatelům dále pomáhají v jejich pracovních postupech. Široká škála různých algoritmů, které spadají do různých kategorií, a algoritmické techniky umožňují uživatelům experimentovat s mnoha logickými směry a porovnávat tyto výsledky tak, aby bylo možné dosáhnout nejoptimálnějšího řešení jakéhokoli problému.
Keelův přístup k dolování dat bez přetahování a přetahování kódu pomáhá i začátečníkům bez námahy pracovat s komplexními modely výpočetní inteligence. To poskytuje vhled do komplexních datových souborů a ve výsledku odvozuje užitečné závěry, které pomáhají řešit problémy reálného světa.