Tato příručka ilustruje proces používání grafu znalostí konverzace v LangChain.
Jak používat graf znalostí konverzace v LangChain?
The KonverzaceKGMemory knihovnu lze použít k obnovení paměti, kterou lze použít k získání kontextu interakce. Chcete-li se naučit proces používání grafu znalostí konverzace v LangChain, jednoduše projděte uvedenými kroky:
Krok 1: Nainstalujte moduly
Nejprve začněte s procesem používání grafu znalostí konverzace instalací modulu LangChain:
pip install langchain
Nainstalujte modul OpenAI, který lze nainstalovat pomocí příkazu pip, abyste získali jeho knihovny pro vytváření velkých jazykových modelů:
pip install openai
Nyní, nastavit prostředí pomocí klíče OpenAI API, který lze vygenerovat z jeho účtu:
import vy
import getpass
vy . přibližně [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Klíč OpenAI API:' )
Krok 2: Použití paměti s LLM
Jakmile jsou moduly nainstalovány, začněte používat paměť s LLM importem požadovaných knihoven z modulu LangChain:
z langchain. Paměť import KonverzaceKGMemoryz langchain. llms import OpenAI
Sestavte LLM pomocí metody OpenAI() a nakonfigurujte paměť pomocí KonverzaceKGMemory () metoda. Poté uložte šablony výzev pomocí více vstupů s jejich příslušnou odpovědí, abyste mohli model trénovat na těchto datech:
llm = OpenAI ( teplota = 0 )Paměť = KonverzaceKGMemory ( llm = llm )
Paměť. uložit_kontext ( { 'vstup' : 'pozdravuj Johna' } , { 'výstup' : 'John! Kdo' } )
Paměť. uložit_kontext ( { 'vstup' : 'on je kamarád' } , { 'výstup' : 'Tak určitě' } )
Otestujte paměť načtením souboru paměťové_proměnné () metoda využívající dotaz související s výše uvedenými údaji:
Paměť. load_memory_variables ( { 'vstup' : 'kdo je john' } ) 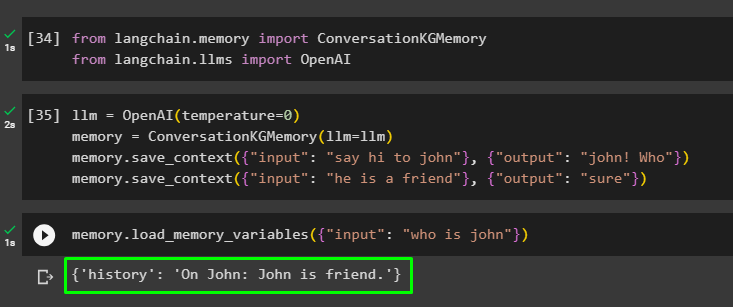
Nakonfigurujte paměť pomocí metody ConversationKGMemory() s návratové_zprávy argument pro získání historie vstupu také:
Paměť = KonverzaceKGMemory ( llm = llm , návratové_zprávy = Skutečný )Paměť. uložit_kontext ( { 'vstup' : 'pozdravuj Johna' } , { 'výstup' : 'John! Kdo' } )
Paměť. uložit_kontext ( { 'vstup' : 'on je kamarád' } , { 'výstup' : 'Tak určitě' } )
Jednoduše otestujte paměť poskytnutím vstupního argumentu s jeho hodnotou ve formě dotazu:
Paměť. load_memory_variables ( { 'vstup' : 'kdo je john' } ) 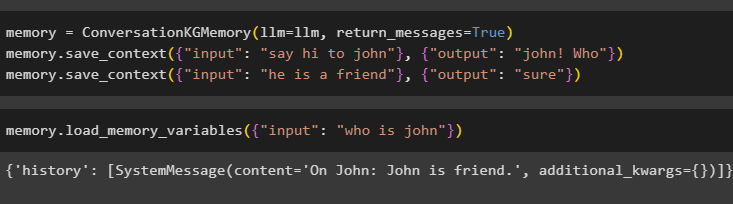
Nyní otestujte paměť položením otázky, která není uvedena v trénovacích datech a model nemá ponětí o odpovědi:
Paměť. get_current_entities ( 'jaká je Johnova oblíbená barva' )Použijte get_knowledge_triplets () metodou odpovědí na dříve položený dotaz:
Paměť. get_knowledge_triplets ( 'jeho oblíbená barva je červená' ) 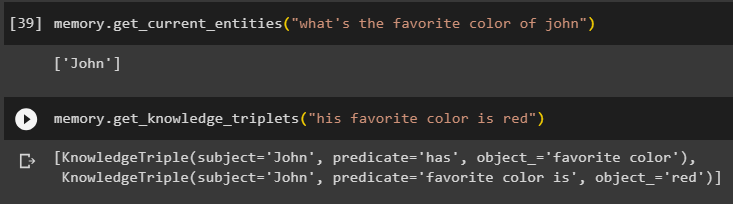
Krok 3: Použití paměti v řetězci
Další krok využívá konverzační paměť s řetězci k sestavení modelu LLM pomocí metody OpenAI(). Poté nakonfigurujte šablonu výzvy pomocí struktury konverzace a text se zobrazí při získávání výstupu podle modelu:
llm = OpenAI ( teplota = 0 )z langchain. vyzve . výzva import PromptTemplate
z langchain. řetězy import ConversationChain
šablona = '''Toto je šablona pro interakci mezi člověkem a strojem
Systém je model umělé inteligence, který může mluvit nebo extrahovat informace o více aspektech
Pokud nerozumí otázce nebo nezná odpověď, jednoduše to řekne
Systém extrahuje data uložená v sekci 'Specifické' a nedělá halucinace
Charakteristický:
{Dějiny}
Konverzace:
Člověk: {input}
AI:'''
#Nakonfigurujte šablonu nebo strukturu pro poskytování výzev a získávání odpovědí ze systému AI
výzva = PromptTemplate ( vstupní_proměnné = [ 'Dějiny' , 'vstup' ] , šablona = šablona )
konverzace_s_kg = ConversationChain (
llm = llm , podrobný = Skutečný , výzva = výzva , Paměť = KonverzaceKGMemory ( llm = llm )
)
Jakmile je model vytvořen, jednoduše zavolejte konverzace_s_kg model pomocí metody forecast() s dotazem položeným uživatelem:
konverzace_s_kg. předpovědět ( vstup = 'Ahoj jak se máš?' ) 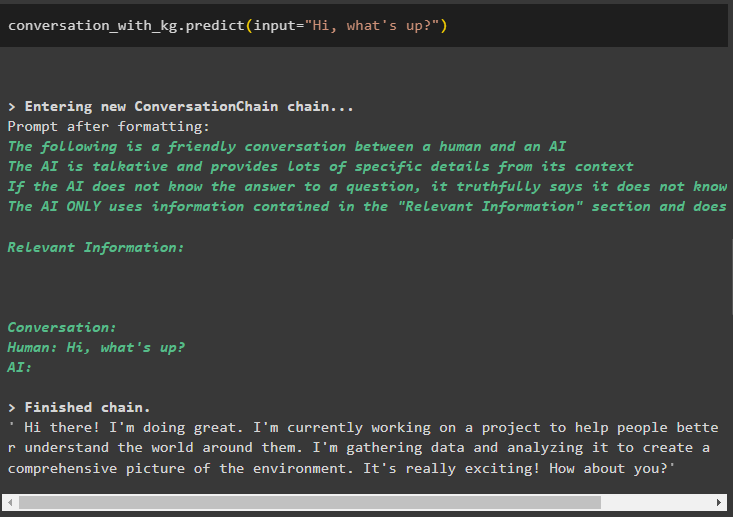
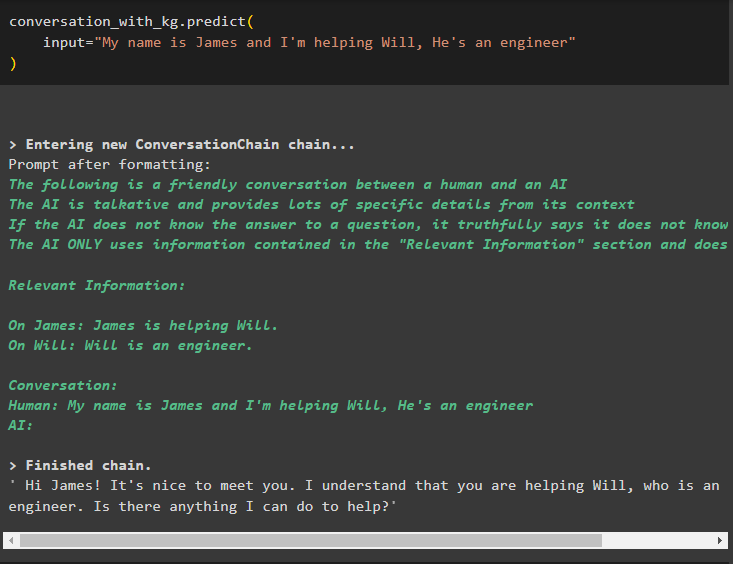
Nyní natrénujte model pomocí paměti konverzace tím, že dáte informace jako vstupní argument pro metodu:
konverzace_s_kg. předpovědět (vstup = 'Jmenuji se James a pomáhám Willovi, je to inženýr.'
)
Zde je čas otestovat model tím, že požádáte dotazy o extrahování informací z dat:
konverzace_s_kg. předpovědět ( vstup = 'Kdo je Will' ) 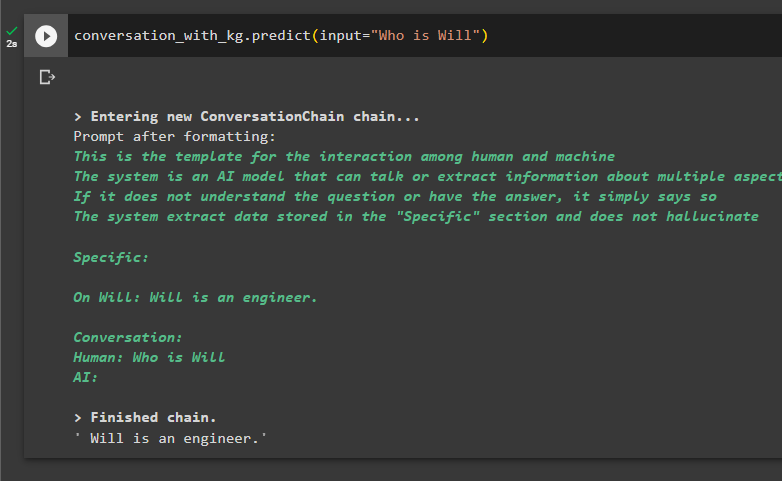
To je vše o použití grafu znalostí konverzace v LangChain.
Závěr
Chcete-li použít graf znalostí konverzace v LangChain, nainstalujte moduly nebo rámce pro import knihoven pro použití metody ConversationKGMemory(). Poté vytvořte model pomocí paměti k sestavení řetězců a extrahujte informace z trénovacích dat poskytnutých v konfiguraci. Tato příručka podrobně popisuje proces používání grafu znalostí konverzace v LangChain.