5.1 Úvod
Operační systém pro počítač Commodore-64 je dodáván s počítačem v paměti pouze pro čtení (ROM). Počet bajtů paměti pro Commodore-64 se pohybuje od $ 0000 do $ FFFF (tj. 000016 až FFFF16, což je 010 až 65 53510). Operační systém je od $E000 do $FFFF (tj. 57,34410 až 65,53610).
Proč studovat operační systém Commodore-64
Proč dnes studovat operační systém Commodore-64, když to byl operační systém počítače, který byl uveden na trh v roce 1982? Počítač Commodore-64 používá Central Processing Unit 6510, což je upgrade (i když ne velký upgrade) 6502 µP.
6502 µP se dodnes vyrábí ve velkém množství; už to není pro domácí nebo kancelářské počítače, ale pro elektrické a elektronické přístroje (zařízení). 6502 µP je také jednoduchý na pochopení a ovládání ve srovnání s jinými mikroprocesory své doby. V důsledku toho je to jeden z nejlepších (ne-li nejlepší) mikroprocesorů pro výuku jazyka symbolických instrukcí.
65C02 µP, stále z mikroprocesorové třídy 6502, má 66 instrukcí v jazyce symbolických instrukcí, z nichž všechny lze dokonce naučit nazpaměť. Moderní mikroprocesory mají mnoho instrukcí v assembleru a nelze je naučit nazpaměť. Každý µP má pro sebe svůj vlastní jazyk symbolů. Jakýkoli operační systém, ať už nový nebo starý, je jazykem symbolických instrukcí. Díky tomu je assembler 6502 vhodný pro výuku operačního systému pro začátečníky. Po naučení operačního systému, jako je ten pro Commodore-64, se lze snadno naučit moderní operační systém na jeho základě.
Není to jen názor autora (mého). Ve světě je to rostoucí trend. Na internetu se píše stále více článků pro vylepšený operační systém Commodore-64, aby vypadal jako moderní operační systém. Moderní operační systémy jsou vysvětleny v následující kapitole.
Poznámka : Commodore-64 OS (Kernal) stále dobře funguje s moderními vstupními a výstupními zařízeními (ne se všemi).
Osmibitový počítač
V osmibitovém mikropočítači, jako je Commodore 64, se informace ukládají, přenášejí a manipulují ve formě osmibitových binárních kódů.
Mapa paměti
Paměťová mapa je měřítko, které rozděluje celý rozsah paměti na menší rozsahy různých velikostí a ukazuje, co (podprogram a/nebo proměnná) patří do jakého rozsahu. Proměnná je označení, které odpovídá konkrétní adrese paměti, která má hodnotu. Štítky se také používají k identifikaci začátku podprogramů. Ale v tomto případě jsou známé jako názvy podprogramů. Podprogram lze jednoduše označit jako rutinu.
Mapa paměti (rozvržení) v předchozí kapitole není dostatečně podrobná. Je to docela jednoduché. Paměťovou mapu počítače Commodore-64 lze zobrazit se třemi úrovněmi detailů. Při zobrazení na střední úrovni má počítač Commodore-64 různé paměťové mapy. Výchozí mapa paměti počítače Commodore-64 na střední úrovni je:

Obr. 5.11 Mapa paměti Commodore-64
V té době byl populární počítačový jazyk zvaný BASIC. Mnoho uživatelů počítačů potřebovalo znát některé minimální příkazy jazyka BASIC, jako je načtení programu z diskety (disku) do paměti, spuštění (spuštění) programu v paměti a ukončení (zavření) programu. Když běží program BASIC, uživatel musí vkládat data řádek po řádku. Není to jako dnes, kdy aplikace (řada programů tvoří aplikaci) je napsána v jazyce na vysoké úrovni s okny a uživatel se musí jen vejít do různých dat na specializovaná místa v okně. V některých případech použijte k výběru předobjednaných dat myš. BASIC byl v té době jazyk na vysoké úrovni, ale je docela blízký jazyku symbolických instrukcí.
Všimněte si, že většinu paměti zabírá BASIC ve výchozí mapě paměti. BASIC má příkazy (instrukce), které jsou vykonávány tím, co je známé jako BASIC Interpreter. Interpret BASIC je ve skutečnosti v ROM od umístění $A000 do $BFFF (včetně), což je údajně oblast RAM. To je 8 kilobajtů, což je v té době docela velké! Je to vlastně v ROM na tom místě celé paměti. Má stejnou velikost jako operační systém od $E000 do $FFFF (včetně). Programy, které jsou napsány v BASICu, jsou také umístěny v rozmezí $ 0200 až $ BFFF.
RAM pro program uživatelského assembleru je od 000 $ do $ CFFF, pouhé 4 kB z 64 kB. Proč tedy používáme nebo se učíme jazyk symbolických instrukcí? Nové a staré operační systémy jsou jazyky symbolických instrukcí. Operační systém Commodore-64 je v ROM, od $E000 do $FFFF. Je napsán v assembleru 65C02 µP (6510 µP). Skládá se z podprogramů. Uživatelský program v jazyce symbolických instrukcí potřebuje volat tyto podprogramy, aby mohl interagovat s periferiemi (vstupními a výstupními zařízeními). Pochopení operačního systému Commodore-64 v jazyce symbolických instrukcí umožňuje studentovi porozumět operačním systémům rychle a mnohem méně únavným způsobem. V té době bylo opět mnoho uživatelských programů pro Commodore-64 napsáno v BASICu a ne v assembleru. Assemblery v té době používali spíše sami programátoři pro technické účely.
Kernal, hláskovaný jako K-e-r-n-a-l, je operační systém Commodore-64. Dodává se s počítačem Commodore-64 v ROM a ne na disku (nebo disketě). Kernal se skládá z podprogramů. Pro přístup k periferiím musí uživatelský program v jazyce symbolických instrukcí (strojový jazyk) používat tyto podprogramy. Kernal by se neměl zaměňovat s jádrem, které se v moderních operačních systémech píše jako K-e-r-n-e-l, i když jde o téměř totéž.
Oblast paměti od $ C000 (49 15210) do $ CFFF (6324810) o velikosti 4 kB 10 paměti je buď RAM nebo ROM. Když je to RAM, používá se pro přístup k periferiím. Když je to ROM, používá se k tisku znaků na obrazovku (monitor). To znamená, že buď se znaky tisknou na obrazovku, nebo se pomocí této části paměti přistupuje k periferním zařízením. V systémové jednotce (základní desce) je banka ROM (znaková ROM), která se zapíná a vypíná z celého paměťového prostoru, aby se toho dosáhlo. Uživatel si přepínání nemusí všimnout.
Oblast paměti od 0100 $ (256 10 ) na $01FF (511 10 ) je zásobník. Používá jej operační systém i uživatelské programy. Role zásobníku byla vysvětlena v předchozí kapitole tohoto online kariérního kurzu. Oblast paměti od 0000 $ (0 10 ) na $ 00FF (255 10 ) používá operační systém. Je tam přiřazeno mnoho ukazatelů.
Kernal Jump Table
Kernal má rutiny, které jsou volány uživatelským programem. Jak vycházely nové verze operačního systému, adresy těchto rutin se měnily. To znamená, že uživatelské programy již nemohly pracovat s novými verzemi OS. To se nestalo, protože Commodore-64 poskytl tabulku skoků. Tabulka skoků je seznam 39 položek. Každá položka v tabulce má tři adresy (kromě posledních 6 bajtů), které se nezměnily ani při změně verze operačního systému.
První adresa záznamu má instrukci JSR. Další dvě adresy se skládají z dvoubajtového ukazatele. Tento dvoubajtový ukazatel je adresa (nebo nová adresa) aktuální rutiny, která je stále v operační paměti ROM. Obsah ukazatele se může s novými verzemi OS změnit, ale tři adresy pro každou položku tabulky skoků se nikdy nezmění. Uvažujme například adresy $FF81, $FF82 a $FF83. Tyto tři adresy jsou pro rutinu pro inicializaci obrazovky a obvodů klávesnice (registrů) základní desky. Adresa $FF81 má vždy operační kód (jeden bajt) JSR. Adresy $FF82 a $FF83 mají starou nebo novou adresu podprogramu (stále v operační paměti ROM) pro provedení inicializace. Najednou měly adresy $FF82 a $FF83 obsah (adresu) $FF5B, což se mohlo s další verzí OS změnit. Adresy $FF81, $FF82 a $FF83 tabulky skoků se však nikdy nezmění.
Pro každý záznam tří adres má první adresa s JSR štítek (název). Štítek pro $ FF81 je PCINT. PCINT se nikdy nemění. Takže pro inicializaci registrů obrazovky a klávesnice může programátor jednoduše napsat „JSR PCINT“, které funguje pro všechny verze operačního systému Commodore-64. Umístění (počáteční adresa) aktuálního podprogramu, např. $FF5B, se může v průběhu času měnit s různými operačními systémy. Ano, v uživatelském programu, který používá operační systém ROM, jsou zahrnuty alespoň dvě instrukce JSR. V uživatelském programu existuje instrukce JSR, která skočí na záznam v tabulce skoků. S výjimkou posledních šesti adres v tabulce skoků má první adresa záznamu v tabulce skoků instrukci JSR. V Kernalu mohou některé podprogramy volat ostatní podprogramy.
Kernalova tabulka skoků začíná od $FF81 (včetně) nahoru po skupinách po třech, s výjimkou posledních šesti bajtů, což jsou tři ukazatele s nižšími bajtovými adresami: $FFFA, $FFFC a $FFFE. Všechny rutiny ROM OS jsou opakovaně použitelné kódy. Uživatel je tedy nemusí přepisovat.
Blokové schéma systémové jednotky Commodore-64
Následující schéma je podrobnější než to v předchozí kapitole:
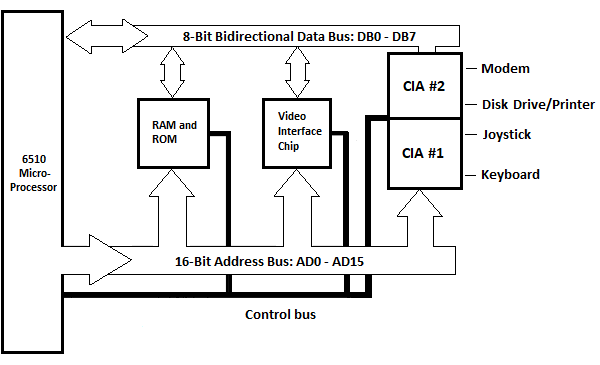
Obr. 5.12 Blokové schéma systémové jednotky Commodore_64
ROM a RAM jsou zde zobrazeny jako jeden blok. Zde je zobrazen čip video rozhraní (IC) pro zpracování informací na obrazovce, který nebyl zobrazen v předchozí kapitole. Jediný blok pro vstupní/výstupní zařízení, který je zobrazen v předchozí kapitole, je zde znázorněn jako dva bloky: CIA #1 a CIA #2. CIA je zkratka pro Complex Interface Adapter. Každý z nich má dva paralelní osmibitové porty (nezaměňovat s externími porty na svislém povrchu systémové jednotky) nazývané port A a port B. V této situaci jsou CIA připojeny k pěti externím zařízením. Těmito zařízeními jsou klávesnice, joystick, disková jednotka/tiskárna a modem. Tiskárna je připojena na zadní straně diskové jednotky. Je zde také obvod zařízení zvukového rozhraní a obvod programovatelného logického pole, které nejsou zobrazeny.
Přesto existuje ROM pro postavy, kterou lze vyměnit za obě CIA, když je postava odeslána na obrazovku a není zobrazena v blokovém diagramu.
Adresy RAM od $ D000 do $ DFFF pro vstupní/výstupní obvody bez znakové ROM mají následující podrobnou mapu paměti:
| Tabulka 5.11 Podrobná mapa paměti od $ D000 do $ DFFF |
||
|---|---|---|
| Rozsah podadres | Obvod | Velikost (bajty) |
| D000 – D3FF | VIC (řadič video rozhraní (čip)) | 1K |
| D400 – D7FF | SID (zvukový obvod) | 1K |
| D800 – DBFF | Barevná RAM | 1K Nibbles |
| DC00 – DCFF | CIA #1 (klávesnice, joystick) | 256 |
| DD00 – DDFF | CIA #2 (sériová sběrnice, uživatelský port/RS-232) | 256 |
| DE00 – DEF | Otevřete I/O slot #1 | 256 |
| DF00 – DFFF | Otevřete I/O slot #2 | 256 |
5.2 Dva komplexní adaptéry rozhraní
V systémové jednotce Commodore-64 jsou dva konkrétní integrované obvody (IC) a každý z nich se nazývá Complex Interface Adapter. Tyto dva čipy se používají k propojení klávesnice a dalších periferií s mikroprocesorem. S výjimkou VIC a obrazovky procházejí všechny vstupní/výstupní signály mezi mikroprocesorem a periferiemi přes tyto dva integrované obvody. U Commodore-64 neexistuje žádná přímá komunikace mezi pamětí a periferií. Komunikace mezi pamětí a jakoukoli periferií prochází přes mikroprocesorový akumulátor a jedním z nich jsou adaptéry CIA (IC). IC jsou označovány jako CIA #1 a CIA #2. CIA je zkratka pro Complex Interface Adapter.
Každá CIA má 16 registrů. S výjimkou registrů časovače/čítače v CIA je každý registr 8 bitů široký a má paměťovou adresu. Adresy paměťových registrů pro CIA #1 jsou od $ DC00 (56320 10 ) na $ DC0F (56335 10 ). Adresy paměťových registrů pro CIA #2 jsou od $ DD00 (56576 10 ) na $DD0F (56591 10 ). Ačkoli tyto registry nejsou v paměti IC, jsou součástí paměti. V mapě přechodné paměti zahrnuje I/O oblast od $D000 do $DFFF adresy CIA od $DC00 do $DC0F a od $DD00 do $DD0F. Většinu oblasti I/O paměti RAM od $D000 do $DFFF lze zaměnit s paměťovou bankou znakové ROM za znaky obrazovky. To je důvod, proč když jsou znaky odeslány na obrazovku, periferie nemohou fungovat; i když si toho uživatel nemusí všimnout, protože přepínání tam a zpět je rychlé.
V CIA #1 jsou dva registry nazvané Port A a Port B. Jejich adresy jsou $ DC00 a $ DC01, v tomto pořadí. V CIA č. 2 jsou také dva registry nazvané Port A a Port B. Jejich adresy se samozřejmě liší; jsou DD00 a DD01 $, v tomto pořadí.
Port A nebo Port B v obou CIA je paralelní port. To znamená, že může odesílat data do periferie v osmi bitech najednou nebo přijímat data z mikroprocesoru v osmi bitech najednou.
S portem A nebo B je spojen registr směru dat (DDR). Registr směru dat pro port A CIA #1 (DDRA1) je v místě bajtu paměti $DC02. Registr směru dat pro port B CIA #1 (DDRB1) je v místě bajtu paměti $DC03. Registr směru dat pro port A CIA #2 (DDRA2) je v místě bajtu paměti $DD02. Registr směru dat pro port B CIA #2 (DDRB2) je v místě bajtu paměti $DD03.
Nyní lze každý bit pro port A nebo port B nastavit odpovídajícím registrem směru dat jako vstup nebo výstup. Vstup znamená, že informace jdou z periferie do mikroprocesoru přes CIA. Výstup znamená, že informace jdou z mikroprocesoru do periferie přes CIA.
Pokud má být vložena buňka portu (registru), odpovídající bit v registru směru dat je 0. Pokud má být odeslána buňka portu (registru), odpovídající bit v registru směru dat je 1. Ve většině případů je všech 8 bitů portu naprogramováno jako vstupní nebo výstupní. Když je počítač zapnutý, port A je naprogramován pro výstup a port B je naprogramován pro vstup. Následující kód umožňuje CIA #1 port A jako výstup a CIA #1 port B jako vstup:
LDA # $ FF
STA DDRA1; $DC00 je v režii $DC02
LDA # 00 $
STA DDRB1; $DC01 je v režii $DC03
DDRA1 je označení (název proměnné) pro umístění bajtu paměti $DC02 a DDRB1 je označení (název proměnné) pro umístění bajtu paměti $DC03. První instrukce nahraje 11111111 do akumulátoru µP. Druhá instrukce to zkopíruje do datového rejstříku portu A CIA č. 1. Třetí instrukce načte 00000000 do akumulátoru µP. Čtvrtá instrukce to zkopíruje do datového rejstříku portu B CIA č. 1. Tento kód je v jednom z podprogramů v operačním systému, který provádí tuto inicializaci při zapnutí počítače.
Každá CIA má linku pro žádost o přerušení do mikroprocesoru. Ten od CIA #1 jde do IRQ kolík µP. Ten od CIA #2 jde do NMI kolík µP. Pamatuj si to NMI má vyšší prioritu než IRQ .
5.3 Programování v assembleru klávesnice
Pro Commodore-64 existují pouze tři možná přerušení: IRQ , BRK a NMI . Ukazatel tabulky skoků pro IRQ je na adresách $FFFE a $FFFF v ROM (operační systém), což odpovídá podprogramu, který je stále v OS (ROM). Ukazatel tabulky skoků pro BRK je na adresách $FFFC a $FFFD v OS, což odpovídá podprogramu, který je stále v OS (ROM). Ukazatel tabulky skoků pro NMI je na adresách $FFFA a $FFFB v OS, což odpovídá podprogramu, který je stále v OS (ROM). Pro IRQ , ve skutečnosti existují dva podprogramy. Takže softwarové přerušení (instrukce) BRK má svůj vlastní ukazatel tabulky skoků. Ukazatel tabulky skoků pro IRQ vede ke kódu, který rozhoduje, zda se jedná o hardwarové nebo softwarové přerušení. Pokud se jedná o hardwarové přerušení, rutina pro IRQ je nazýván. Pokud se jedná o softwarové přerušení (BRK), je volána rutina pro BRK. V jedné z verzí OS je podprogram pro IRQ je na $ EA31 a podprogram pro BRK je na $ FE66. Tyto adresy jsou nižší než FF81 $, takže se nejedná o položky tabulky skoků a mohly by se měnit podle verze operačního systému. V tomto tématu jsou zajímavé tři rutiny: ta, která kontroluje, zda se jedná o stisknutou klávesu nebo BRK, ta, která je za 43 $, a ta, která se také může měnit s verzí operačního systému.
Počítač Commodore-64 vypadá jako obrovský psací stroj (směrem nahoru) bez tiskové sekce (hlava a papír). Klávesnice je připojena k CIA #1. CIA #1 skenuje klávesnici každou 1/60 sekundy sama o sobě bez jakéhokoli zásahu do programování, ve výchozím nastavení. Takže každou 1/60 sekundy CIA #1 posílá IRQ do µP. Existuje pouze jeden IRQ pin na µP, který pochází pouze od CIA #1. Jeden vstupní kolík NMI µP, který se liší od IRQ , pochází pouze od CIA #2 (viz následující obrázek). BRK je ve skutečnosti instrukce v assembleru, která je zakódována v uživatelském programu.
Takže každých 1/60 sekundy IRQ je volána rutina, na kterou ukazuje $FFFE a $FFFF. Rutina kontroluje, zda byla stisknuta klávesa nebo zda byla nalezena instrukce BRK. Pokud je stisknuta klávesa, je volána rutina pro zpracování stisknutí klávesy. Pokud se jedná o instrukci BRK, je volána rutina pro zpracování BRK. Pokud není ani jedno, nic se neděje. Ani jedno nemusí nastat, ale CIA #1 posílá IRQ na µP každých 1/60 sekundy.
Fronta klávesnice, známá také jako vyrovnávací paměť klávesnice, je rozsah umístění bajtů RAM od $0277 do $0280 včetně; Celkem 1010 bajtů. Toto je vyrovnávací paměť First-IN-First-Out. To znamená, že první postava, která přijde, první odejde. Západoevropský znak trvá jeden bajt.
Takže zatímco program při stisknutí klávesy nespotřebovává žádný znak, kód klávesy jde do této vyrovnávací paměti (fronty). Vyrovnávací paměť se zaplňuje, dokud nezbývá deset znaků. Žádný znak, který je stisknut po desátém znaku, nebude zaznamenán. Je ignorován, dokud není z fronty získán (spotřebován) alespoň jeden znak. Tabulka skoků má záznam pro podprogram, který dostane první znak z fronty do mikroprocesoru. To znamená, že vezme první znak, který jde do fronty, a vloží ho do akumulátoru µP. Podprogram tabulky skoků k tomu se nazývá GETIN (pro Get-In). První bajt pro tříbajtový záznam v tabulce skoků je označen jako GETIN (adresa $FFE4). Další dva bajty jsou ukazatel (adresa), který ukazuje na aktuální rutinu v ROM (OS). Za volání této rutiny je odpovědností programátora. Jinak zůstane vyrovnávací paměť klávesnice plná a všechny naposledy stisknuté klávesy budou ignorovány. Hodnota, která jde do akumulátoru, je odpovídající klíčová hodnota ASCII.
Jak se vůbec kódy klíčů dostanou do fronty? Existuje rutina tabulky skoků nazvaná SCNKEY (pro skenovací klíč). Tuto rutinu může volat jak software, tak hardware. V tomto případě je volán elektronickým (fyzikálním) obvodem v mikroprocesoru při elektrickém signálu IRQ je nízký. Jak se to přesně dělá, se v tomto online kariérním kurzu nezabývá.
Kód pro získání prvního kódu klíče z vyrovnávací paměti klávesnice do akumulátoru A je pouze jeden řádek:
NASTOUPIT
Pokud je vyrovnávací paměť klávesnice prázdná, do akumulátoru se vloží 00 $. Pamatujte, že ASCII kód pro nulu není 00 $; je to 30 dolarů. $00 znamená Null. V programu může nastat bod, kdy musí program čekat na stisknutí klávesy. Kód pro to je:
ČEKEJTE JSR GETIN
CMP # 00 $
ŽÁBA ČEKEJTE
V prvním řádku je „WAIT“ označení, které identifikuje adresu RAM, kam je vložena (zapsána) instrukce JSR. GETIN je také adresa. Je to adresa prvního z odpovídajících tří bajtů v tabulce skoků. Záznam GETIN, stejně jako všechny záznamy v tabulce skoků (kromě posledních tří), se skládá ze tří bajtů. První byte položky je instrukce JSR. Další dva bajty jsou adresou těla aktuálního podprogramu GETIN, který je stále v ROM (OS), ale pod tabulkou skoků. Záznam tedy říká, že je třeba přejít na podprogram GETIN. Pokud fronta klávesnice není prázdná, GETIN vloží kód ASCII klíče fronty First-In-First-Out do akumulátoru. Pokud je fronta prázdná, vloží se do akumulátoru Null (00 $).
Druhá instrukce porovnává hodnotu akumulátoru s 00 $. Pokud je $00, znamená to, že fronta klávesnice je prázdná a instrukce CMP posílá 1 do příznaku Z registru stavu procesoru (jednoduše nazývaného stavový registr). Pokud hodnota v A není $00, instrukce CMP odešle 0 do příznaku Z stavového registru.
Třetí instrukce, která je „BEQ WAIT“ posílá program zpět k první instrukci, pokud je příznak Z stavového registru 1. První, druhá a třetí instrukce jsou prováděny opakovaně v pořadí, dokud není stisknuta klávesa na klávesnici. . Pokud není klávesa nikdy stisknuta, cyklus se opakuje donekonečna. Segment kódu, jako je tento, je normálně zapsán segmentem časového kódu, který po nějaké době opustí smyčku, pokud není nikdy stisknuta klávesa (viz následující diskuse).
Poznámka : Klávesnice je výchozí vstupní zařízení a obrazovka je výchozí výstupní zařízení.
5.4 Kanál, Číslo zařízení a Číslo logického souboru
Periferní zařízení, která tato kapitola používá k vysvětlení operačního systému Commodore-64, jsou klávesnice, obrazovka (monitor), disková jednotka s disketou, tiskárna a modem, který se připojuje přes rozhraní RS-232C. Aby mohla probíhat komunikace mezi těmito zařízeními a systémovou jednotkou (mikroprocesorem a pamětí), musí být vytvořen kanál.
Kanál se skládá z vyrovnávací paměti, čísla zařízení, čísla logického souboru a volitelně sekundární adresy. Vysvětlení těchto pojmů je následující:
Vyrovnávací paměť
Všimněte si z předchozí části, že když je stisknuta klávesa, její kód musí přejít na bajtové místo v RAM v sérii deseti po sobě jdoucích umístění. Tato řada deseti míst je vyrovnávací paměť klávesnice. Každé vstupní nebo výstupní zařízení (periferní zařízení) má v paměti RAM řadu po sobě jdoucích míst, která se nazývají vyrovnávací paměť.
Číslo zařízení
U Commodore-64 je každé periferii přiřazeno číslo zařízení. V následující tabulce jsou uvedena různá zařízení a jejich čísla:
| Tabulka 5.41 Čísla zařízení Commodore 64 a jejich zařízení |
|
|---|---|
| Číslo | přístroj |
| 0 | Klávesnice |
| 1 | Pásková jednotka |
| 2 | Rozhraní RS 232C např. modem |
| 3 | Obrazovka |
| 4 | Tiskárna #1 |
| 5 | Tiskárna #2 |
| 6 | Plotr #1 |
| 7 | Plotr #2 |
| 8 | Disková jednotka |
| 9 ¦ ¦ ¦ 30 |
Od 8 (včetně) až po 22 dalších úložných zařízení |
Existují dva typy portů pro počítač. Jeden typ je externí, na svislém povrchu systémové jednotky. Druhý typ je vnitřní. Tento interní port je registr. Commodore-64 má čtyři vnitřní porty: port A a port B pro CIA 1 a port A a port B pro CIA 2. Existuje jeden externí port pro Commodore-64, který se nazývá sériový port. Zařízení s číslem 3 výše jsou připojena k sériovému portu. Jsou propojeny řetězovým způsobem (jeden, který je zapojen za druhým), každý z nich je identifikovatelný podle čísla zařízení. Zařízení s číslem 8 výše jsou obecně úložná zařízení.
Poznámka : Výchozí vstupní zařízení je klávesnice s číslem zařízení 0. Výchozím výstupním zařízením je obrazovka s číslem zařízení 3.
Logické číslo souboru
Logické číslo souboru je číslo dané zařízení (perifernímu zařízení) v pořadí, v jakém jsou otevřena pro přístup. Pohybují se od 010 do 255 10 .
Sekundární adresa
Představte si, že jsou na disku otevřeny dva soubory (nebo více souborů). K rozlišení těchto dvou souborů se používají sekundární adresy. Sekundární adresy jsou čísla, která se liší zařízení od zařízení. Význam 3 jako sekundární adresa pro tiskárnu se liší od významu 3 jako sekundární adresa pro diskovou jednotku. Význam závisí na vlastnostech, jako když je soubor otevřen pro čtení nebo kdy je soubor otevřen pro zápis. Možná sekundární čísla jsou od 0 10 do 15 10 pro každé zařízení. U mnoha zařízení se číslo 15 používá pro odesílání příkazů.
Poznámka : Číslo zařízení je také známé jako adresa zařízení a sekundární číslo je také známé jako sekundární adresa.
Identifikace periferního cíle
Pro výchozí mapu paměti Commodore jsou adresy paměti od $0200 do $02FF (strana 2) používány výhradně operačním systémem v ROM (Kernal) a nikoli operačním systémem plus jazyk BASIC. Ačkoli BASIC může stále používat umístění prostřednictvím ROM OS.
Modem a tiskárna jsou dva různé periferní cíle. Pokud jsou z disku otevřeny dva soubory, jedná se o dva různé cíle. S výchozí mapou paměti existují tři po sobě jdoucí tabulky (seznamy), které lze považovat za jednu velkou tabulku. Tyto tři tabulky obsahují vztah mezi čísly logických souborů, čísly zařízení a sekundárními adresami. Díky tomu se stane identifikovatelný konkrétní kanál nebo cíl vstupu/výstupu. Tyto tři tabulky se nazývají tabulky souborů. Adresy RAM a to, co mají, jsou:
$0259 — $0262: Tabulka s popiskem, LAT, až deseti aktivních logických čísel souborů.
$0263 — $026C: Tabulka se štítkem, FAT, s až deseti odpovídajícími čísly zařízení.
$026D — $0276: Tabulka s popiskem, SAT, deseti odpovídajících sekundárních adres.
Zde „-“ znamená „do“ a číslo zabírá jeden bajt.
Čtenář se může ptát: 'Proč není vyrovnávací paměť pro každé zařízení zahrnuta do identifikace kanálu?' Odpověď zní, že u commodore-64 má každé externí zařízení (periferní zařízení) pevnou sérii bajtů v paměti RAM (mapa paměti). Bez jakéhokoli otevřeného kanálu jsou jejich pozice stále v paměti. Vyrovnávací paměť pro klávesnici je například fixně nastavena od 0277 do 0280 $ (včetně) pro výchozí mapu paměti.
Kernal podprogramy SETLFS a SETNAM
SETLFS a SETNAM jsou rutiny jádra. Kanál lze považovat za logický soubor. Aby byl kanál otevřen, musí být vytvořeno logické číslo souboru, číslo zařízení a volitelná sekundární adresa. Může být také zapotřebí volitelný název souboru (text). Rutina SETLFS nastavuje číslo logického souboru, číslo zařízení a volitelnou sekundární adresu. Tato čísla jsou uvedena v příslušných tabulkách. Rutina SETNAM nastaví název řetězce pro soubor, který může být povinný pro jeden kanál a volitelný pro jiný kanál. Ten se skládá z ukazatele (dvoubajtová adresa) v paměti. Ukazatel ukazuje na začátek řetězce (jméno), který může být na jiném místě v paměti. Název řetězce začíná byte, který má délku řetězce, za nímž následuje text (název). Název je maximálně šestnáct bajtů (dlouhý).
Pro volání rutiny SETLFS musí uživatelský program skočit (JSR) na adresu $FFBA tabulky skoků operačního systému v ROM pro výchozí mapu paměti. Pamatujte, že s výjimkou posledních šesti bajtů tabulky skoků se každý záznam skládá ze tří bajtů. První byte je instrukce JSR, která pak skočí do podprogramu a začíná na adrese v dalších dvou bytech. Pro volání rutiny SETNAM musí uživatelský program skočit (JSR) na adresu $FFBD tabulky skoků operačního systému v ROM. Použití těchto dvou rutin je uvedeno v následující diskusi.
5.5 Otevření kanálu, otevření logického souboru, uzavření logického souboru a uzavření všech I/O kanálů
Kanál se skládá z vyrovnávací paměti, čísla logického souboru, čísla zařízení (adresa zařízení) a volitelné sekundární adresy (číslo). Logický soubor (abstrakce), který je identifikován logickým číslem souboru, může odkazovat na periferní zařízení, jako je tiskárna, modem, disková jednotka atd. Každé z těchto různých zařízení by mělo mít různá logická čísla souborů. Na disku je mnoho souborů. Logický soubor může také odkazovat na konkrétní soubor na disku. Tento konkrétní soubor má také logické číslo souboru, které se liší od čísel periferních zařízení, jako je tiskárna nebo modem. Logické číslo souboru je dáno programátorem. Může to být libovolné číslo od 010 (00 USD) do 25510 (FF USD).
Rutina OS SETLFS
Rutina OS SETLFS, ke které se přistupuje přeskakováním (JSR) do tabulky skoků OS ROM v $FFBA, nastavuje kanál. Potřebuje vložit logické číslo souboru do tabulky souborů, což je LAT ($0259 — $0262). Je třeba vložit odpovídající číslo zařízení do tabulky souborů, což je FAT ($0263 — $026C). Pokud přístup k souboru (zařízení) potřebuje sekundární číslo, musí do tabulky souborů vložit odpovídající sekundární adresu (číslo), což je SAT ($026D — $0276).
Aby mohl podprogram SETLFS fungovat, potřebuje získat logické číslo souboru z µP akumulátoru; potřebuje získat číslo zařízení z registru µP X. Pokud to kanál potřebuje, potřebuje získat sekundární adresu z registru µP Y.
O logickém čísle souboru rozhoduje programátor. Logická čísla souborů, která odkazují na různá zařízení, se liší. Nyní, před voláním rutiny SETLFS, by měl programátor vložit číslo logického souboru do µP akumulátoru. Číslo zařízení se načte z tabulky (dokumentu), jako je tabulka 5.41. Programátor by měl také vložit číslo zařízení do registru µP X. Dodavatel zařízení, jako je tiskárna, disková jednotka atd., poskytuje možné sekundární adresy a jejich význam pro zařízení. Pokud kanál potřebuje sekundární adresu, musí ji programátor získat z dokumentu, který je dodán se zařízením (periferní zařízení). Pokud je sekundární adresa (číslo) nezbytná, musí ji programátor před voláním podprogramu SETLFS vložit do registru µP Y. Pokud není potřeba sekundární adresa, musí programátor před voláním podprogramu SETLFS vložit číslo $FF do registru µP Y.
Podprogram SETLFS je volán bez jakéhokoli argumentu. Jeho argumenty jsou již ve třech registrech 6502 µP. Po vložení příslušných čísel do registrů se rutina zavolá v programu jednoduše s následujícím na samostatném řádku:
JSR SETLFS
Rutina vloží různá čísla vhodně do jejich tabulek souborů.
Rutina OS SETNAM
K rutině OS SETNAM se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFBD. Ne všechna místa určení mají názvy souborů. U těch, které mají cíle (jako soubory na disku), by měl být nastaven název souboru. Předpokládejme, že název souboru je „mydocum“, který se skládá ze 7 bajtů bez uvozovek. Předpokládejme, že tento název je v umístění 101 až 107 $ (včetně) a délka 07 $ je v umístění 100 $. Počáteční adresa znaků řetězce je $C101. Spodní bajt počáteční adresy je $01 a vyšší bajt je $C1.
Před voláním rutiny SETNAM musí programátor vložit číslo $07 (délka řetězce) do µP akumulátoru. Spodní bajt počáteční adresy řetězce $01 je vložen do registru µP X. Vyšší bajt počáteční adresy řetězce $C1 je vložen do registru µP Y. Podprogram se volá jednoduše pomocí následujícího:
JSR SETNAM
Rutina SETNAM spojuje hodnoty ze tří registrů s kanálem. Poté již hodnoty nemusí zůstat v registrech. Pokud kanál nepotřebuje název souboru, musí programátor do µP akumulátoru vložit $00. V tomto případě jsou ignorovány hodnoty, které jsou v registrech X a Y.
Rutina OPEN OPEN
K rutině OS OPEN se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFC0. Tato rutina používá logické číslo souboru, číslo zařízení (a vyrovnávací paměť), možnou sekundární adresu a možný název souboru, aby zajistila spojení mezi počítačem commodore a souborem v externím zařízení nebo v externím zařízení samotném.
Tato rutina, stejně jako všechny ostatní rutiny Commodore OS ROM, nemá žádný argument. Ačkoli používá registry µP, žádný z registrů pro něj nemusel být předem načten argumenty (hodnotami). Chcete-li jej nakódovat, zadejte následující po zavolání SETLFS a SETNAM:
JSR OTEVŘENO
Při rutině OPEN může dojít k chybám. Například soubor nemusí být nalezen pro čtení. Když dojde k chybě, rutina selže a vloží odpovídající číslo chyby do akumulátoru µP a nastaví příznak přenosu (na 1) stavového registru µP. V následující tabulce jsou uvedena čísla chyb a jejich význam:
| Tabulka 5.51 Čísla jaderných chyb a jejich význam pro rutinu OPEN OS ROM |
||
|---|---|---|
| Číslo chyby | Popis | Příklad |
| 1 | PŘÍLIŠ MNOHO SOUBORŮ | OPEN, když je již otevřeno deset souborů |
| 2 | SOUBOR OTEVŘEN | OTEVŘENO 1,3: OTEVŘENO 1,4 |
| 3 | SOUBOR NENÍ OTEVŘEN | PRINT#5 bez OPEN |
| 4 | SOUBOR NENALEZEN | NAČÍST „NEEXISTUJE“,8 |
| 5 | ZAŘÍZENÍ NENÍ PŘÍTOMNO | OTEVŘÍT 11,11: TISK #11 |
| 6 | NENÍ VSTUPNÍ SOUBOR | OTEVŘÍT „SEQ,S,W“: GET#8,X$ |
| 7 | NENÍ VÝSTUPNÍ SOUBOR | OPEN 1,0: PRINT#1 |
| 8 | CHYBÍ NÁZEV SOUBORU | NAČÍST “”,8 |
| 9 | NEZÁKONNÉ ZAŘÍZENÍ Č. | NAČÍST „PROGRAM“, 3 |
Tato tabulka je prezentována způsobem, který čtenář pravděpodobně uvidí na mnoha jiných místech.
Rutina OS CHKIN
K rutině OS CHKIN se přistupuje přeskakováním (JSR) do tabulky skoků OS ROM na $FFC6. Po otevření souboru (logického souboru) je třeba rozhodnout, zda je otevření pro vstup nebo výstup. Rutina CHKIN dělá z otevření vstupní kanál. Tato rutina potřebuje načíst číslo logického souboru z registru µP X. Takže programátor musí před voláním této rutiny vložit logické číslo souboru do registru X. Říká se tomu jednoduše:
JSR CHKIN
Rutina OS CHKOUT
K rutině OS CHKOUT se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFC9. Po otevření souboru (logického souboru) je třeba rozhodnout, zda je otevření pro vstup nebo výstup. Rutina CHKOUT dělá z otevření výstupní kanál. Tato rutina potřebuje načíst číslo logického souboru z registru µP X. Takže programátor musí před voláním této rutiny vložit logické číslo souboru do registru X. Říká se tomu jednoduše:
JSR CHKOUT
Rutina ZAVŘÍT OS
K rutině OS CLOSE se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFC3. Po otevření logického souboru a přenosu bajtů musí být logický soubor uzavřen. Zavřením logického souboru uvolníte vyrovnávací paměť v systémové jednotce pro použití jiným logickým souborem, který je ještě třeba otevřít. Odpovídající parametry ve třech tabulkách souborů se rovněž vymažou. Umístění RAM pro počet otevřených souborů se sníží o 1.
Po zapnutí napájení počítače dojde k hardwarovému resetu mikroprocesoru a dalších hlavních čipů (integrovaných obvodů) na základní desce. Následuje inicializace některých míst paměti RAM a některých registrů v některých čipech základní desky. V procesu inicializace je umístění bajtové paměti adresy $0098 na stránce nula označeno štítkem NFILES nebo LDTND v závislosti na verzi operačního systému. Když je počítač v provozu, toto jednobajtové umístění o 8 bitech obsahuje počet logických souborů, které jsou otevřeny, a index počáteční adresy tří po sobě jdoucích tabulek souborů. Jinými slovy, tento bajt má počet otevřených souborů, který se při zavření logického souboru sníží o 1. Když je logický soubor uzavřen, přístup k terminálovému (cílovému) zařízení nebo aktuálnímu souboru na disku již není možný.
Pro uzavření logického souboru musí programátor vložit číslo logického souboru do µP akumulátoru. Toto je stejné logické číslo souboru, které se používá při otevírání souboru. Rutina CLOSE to potřebuje k uzavření konkrétního souboru. Stejně jako ostatní rutiny OS ROM ani rutina CLOSE nebere argument, ačkoli hodnota použitá z akumulátoru je do jisté míry argument. Instrukce pro jazyk assembleru je jednoduše:
JSR ZAVŘENO
Vlastní nebo předdefinované podprogramy (rutiny) jazyka symbolických instrukcí 6502 nepřijímají argumenty. Argumenty však přicházejí neformálně vložením hodnot, které bude podprogram používat, do registrů mikroprocesoru.
Rutina CLRCHN
K rutině OS CLRCHN se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFCC. CLRCHN je zkratka pro CLEAR CHanneL. Když je logický soubor uzavřen, jeho parametry číslo logického souboru, číslo zařízení a možná sekundární adresa jsou odstraněny. Kanál pro logický soubor je tedy vymazán.
Manuál říká, že rutina OS CLRCHN vymaže všechny otevřené kanály a obnoví výchozí čísla zařízení a další výchozí hodnoty. Znamená to, že číslo zařízení pro periferní zařízení lze změnit? No, ne tak docela. Během inicializace operačního systému je bajtové umístění adresy $0099 uvedeno se štítkem DFLTI, který obsahuje aktuální číslo vstupního zařízení, když je počítač v provozu. Commodore-64 má přístup pouze k jedné periferii najednou. Během inicializace operačního systému je bajtové umístění adresy $009A uvedeno se štítkem DFLTO, který obsahuje aktuální číslo výstupního zařízení, když je počítač v provozu.
Když je volán podprogram CLRCHN, nastaví proměnnou DFLTI na 0 ($00), což je výchozí číslo vstupního zařízení (klávesnice). Nastaví proměnnou DFLTO na 3 ($03), což je výchozí číslo výstupního zařízení (obrazovka). Ostatní proměnné čísla zařízení se resetují podobně. To je význam resetování (nebo obnovení) vstupních/výstupních zařízení do normálu (výchozí hodnoty).
Manuál Commodore-64 říká, že po zavolání rutiny CLRCHN zůstávají otevřené logické soubory otevřené a mohou stále přenášet bajty (data). To znamená, že rutina CLRCHN neodstraní odpovídající záznamy v tabulkách souborů. Název CLRCHN je pro svůj význam poněkud nejednoznačný.
5.6 Odeslání postavy na obrazovku
Hlavní integrovaný obvod (IC) pro zobrazení znaků a grafiky na obrazovce se nazývá Video Interface Controller (čip), který je v Commodore-64 zkrácen jako VIC (ve skutečnosti VIC II pro VIC verze 2). Aby se informace (hodnoty) dostaly na obrazovku, musí před dosažením obrazovky projít přes VIC II.
Obrazovka se skládá z 25 řádků a 40 sloupců buněk znaků. Na obrazovce tak lze zobrazit 40 x 25 = 1000 znaků. VIC II čte odpovídajícím způsobem 1000 paměťových RAM po sobě jdoucích umístění bajtů pro znaky. Těchto 1000 míst dohromady se nazývá paměť obrazovky. Co jde do těchto 1000 míst, jsou kódy postav. U Commodore-64 se kódy znaků liší od kódů ASCII.
Znakový kód není znakový vzor. Existuje také to, co je známé jako charakter ROM. Znaková ROM se skládá z nejrůznějších vzorů znaků, z nichž některé odpovídají vzorům znaků na klávesnici. Znaková ROM se liší od paměti obrazovky. Když má být na obrazovce zobrazen znak, je kód znaku odeslán na pozici mezi 1000 pozicemi v paměti obrazovky. Odtud se vybere odpovídající vzor ze znakové ROM, který se má zobrazit na obrazovce. Výběr správného vzoru ve znakové ROM ze znakového kódu provádí VIC II (hardware).
Mnoho paměťových míst mezi $D000 a $DFFF má dva účely: používají se ke zpracování vstupních/výstupních operací jiných než obrazovka nebo se používají jako znaková ROM pro obrazovku. Jedná se o dva bloky paměti. Jedna je RAM a druhá je ROM pro ROM pro postavy. Výměna bank, aby se zpracovávaly buď vstup/výstup nebo vzory znaků (znaková ROM) se provádí softwarově (rutina OS v ROM od $ F000 do $ FFFF).
Poznámka : VIC má registry, které jsou adresovány adresami paměťového prostoru v rozsahu $D000 a $DFFF.
Rutina CHROUT
K rutině OS CHROUT se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFD2. Tato rutina, když je volána, vezme bajt, který programátor vložil do µP akumulátoru, a vytiskne jej na obrazovce, kde je kurzor. Segment kódu pro tisk znaku „E“ je například:
LDA # 05 $
CHROUT
0516 není ASCII kód pro „E“. Commodore-64 má své vlastní kódy znaků pro obrazovku, kde $05 znamená „E“. Číslo #$05 se uloží do paměti obrazovky, než jej VIC odešle na obrazovku. Tyto dva kódovací řádky by měly přijít po nastavení kanálu, otevření logického souboru a volání rutiny CHKOUT pro výstup. Kompletní kód je:
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 03 $; číslo zařízení pro obrazovku je 03 $
LDY #$FF ; žádná sekundární adresa
JSR SETLFS ; správně nastavit kanál
; žádné SETNAM, protože obrazovka nepotřebuje název
;
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro výstup
LDX #40 $; logické číslo souboru
JSR CHKOUT
;
; Výstup znaku na obrazovku
LDA # 05 $
JSR CHROUT
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
Před spuštěním jiného programu by měl být otvor uzavřen. Předpokládejme, že uživatel počítače zadá znak na klávesnici podle očekávání. Následující program vytiskne znak z klávesnice na obrazovku:
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 03 $; číslo zařízení pro obrazovku je 03 $
LDY #$FF ; žádná sekundární adresa
JSR SETLFS ; správně nastavit kanál
; žádné SETNAM, protože obrazovka nepotřebuje název
;
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro výstup
LDX #40 $; logické číslo souboru
JSR CHKOUT
;
; Zadejte znak z klávesnice
ČEKEJTE JSR GETIN ; vloží 00 $ do A, pokud je fronta klávesnice prázdná
CMP # 00 $; Pokud 00 $ šlo do A, pak Z je při srovnání 1
BEQ ČEKEJTE ; GETIN z fronty znovu, pokud 0 šla do akumulátoru
BNE PRNSCRN ; přejděte na PRNSCRN, pokud Z je 0, protože A již nemá $00
; Výstup znaku na obrazovku
PRNSCRN JSR CHROUT ; pošlete znak v A na obrazovku
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
Poznámka : WAIT a PRNSCRN jsou štítky, které identifikují adresy. Bajt z klávesnice, který přichází do µP akumulátoru, je kód ASCII. Odpovídající kód, který má Commodore-64 odeslat na obrazovku, se musí lišit. To není v předchozím programu pro jednoduchost zohledněno.
5.7 Odesílání a přijímání bajtů pro diskovou jednotku
V systémové jednotce (základní desce) Commodore-64 jsou dva Complex Interface Adapters s názvem VIA #1 a CIA #2. Každá CIA má dva paralelní porty, které se nazývají Port A a Port B. Na svislém povrchu na zadní straně systémové jednotky Commodre-64 je externí port, který se nazývá sériový port. Tento port má 6 pinů, z nichž jeden je pro data. Data vstupují nebo opouštějí systémovou jednotku v sérii, jeden bit po druhém.
Například osm paralelních bitů z interního portu A CIA #2 může vycházet ze systémové jednotky přes externí sériový port poté, co jsou převedeny na sériová data posuvným registrem v CIA. Osmibitová sériová data z externího sériového portu mohou jít do interního portu A CIA #2 poté, co jsou převedena na paralelní data posuvným registrem v CIA.
Systémová jednotka Commodore-64 (základní jednotka) používá externí diskovou jednotku s disketou. Tiskárnu lze k této diskové jednotce připojit řetězovým způsobem (zapojení zařízení do série jako řetězec). Datový kabel pro diskovou jednotku je připojen k externímu sériovému portu systémové jednotky Commodore-64. To znamená, že ke stejnému sériovému portu je připojena také tiskárna s řetězem. Tato dvě zařízení jsou označena dvěma různými čísly zařízení (typicky 8 a 4).
Odeslání nebo příjem dat pro diskovou jednotku se řídí stejným postupem, jaký byl popsán výše. to je:
- Nastavení názvu logického souboru (čísla), který je stejný jako skutečný diskový soubor pomocí rutiny SETNAM.
- Otevření logického souboru pomocí rutiny OPEN.
- Rozhodování, zda jde o vstup nebo výstup pomocí rutiny CHKOUT nebo CHKIN.
- Odeslání nebo příjem dat pomocí instrukce STA a/nebo LDA.
- Zavření logického souboru pomocí rutiny CLOSE.
Logický soubor musí být uzavřen. Zavřením logického souboru efektivně zavřete tento konkrétní kanál. Při nastavování kanálu pro diskovou jednotku rozhoduje o logickém čísle souboru programátor. Je to číslo mezi $ 00 a $ FF (včetně). Nemělo by to být číslo, které již bylo vybráno pro jakékoli jiné zařízení (nebo skutečný soubor). Číslo zařízení je 8, pokud existuje pouze jedna disková jednotka. Sekundární adresu (číslo) získáte z manuálu k diskové jednotce. Následující program používá 2. Program zapíše písmeno „E“ (ASCII) do souboru na disku s názvem „mydoc.doc“. Předpokládá se, že tento název začíná na adrese paměti $C101. Takže nižší bajt $01 musí být v registru X a vyšší bajt $C1 musí být v registru Y před voláním rutiny SETNAM. Registr A by také měl mít před voláním rutiny SETNAM číslo $09.
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 08 $; číslo zařízení pro první diskovou jednotku
LDY #$02 ; sekundární adresa
JSR SETLFS ; správně nastavit kanál
;
; Soubor na disku potřebuje název (již v paměti)
LDA # 09 $
LDX # 01 $
LDY#$C1
JSR SETNAM
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro výstup
LDX #40 $; logické číslo souboru
JSR CHKOUT ;pro psaní
;
; Výstupní znak na disk
LDA # 45 $
JSR CHROUT
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
Chcete-li načíst bajt z disku do registru µP Y, zopakujte předchozí program s následujícími změnami: Místo „JSR CHKOUT ; pro psaní“, použijte „JSR CHKIN ; ke čtení“. Nahraďte segment kódu za „; Výstupní znak na disk“ s následujícím:
; Vložte znak z disku
JSR CHRIS
K rutině OS CHRIN se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFCF. Tato rutina, když je volána, získá bajt z kanálu, který je již nastaven jako vstupní kanál, a vloží jej do registru µP A. Místo CHRIN lze také použít rutinu GETIN ROM OS.
Odeslání bajtu do tiskárny
Odeslání bajtu na tiskárnu se provádí podobným způsobem jako odeslání bajtu do souboru na disku.
5.8 Rutina ULOŽENÍ OS
K rutině OS SAVE se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFD8. Rutina OS SAVE v ROM uloží (vypíše) část paměti na disk jako soubor (s názvem). Musí být známa počáteční adresa sekce v paměti. Koncová adresa sekce musí být také známa. Spodní bajt počáteční adresy je umístěn na stránce nula v paměti RAM na adrese $002B. Vyšší bajt počáteční adresy je umístěn na další bajtové paměťové místo na adrese $002C. Na stránce nula štítek TXTTAB odkazuje na tyto dvě adresy, ačkoli TXTTAB ve skutečnosti znamená adresu $002B. Spodní bajt koncové adresy je umístěn v registru µP X. Vyšší byte koncové adresy plus 1 je umístěn v registru µP Y. Registr µP A má hodnotu $2B pro TXTTAB ($002B). Díky tomu lze rutinu SAVE volat s následujícím:
JSR ULOŽIT
Část paměti, která má být uložena, může být program v jazyce symbolických instrukcí nebo dokument. Příkladem dokumentu může být dopis nebo esej. Chcete-li použít rutinu ukládání, je třeba dodržet následující postup:
- Nastavte kanál pomocí rutiny SETLFS.
- Pomocí rutiny SETNAM nastavte název logického souboru (číslo), který je stejný jako skutečný diskový soubor.
- Otevřete logický soubor pomocí rutiny OPEN.
- Vytvořte soubor pro výstup pomocí CHKOUT.
- Zde je kód pro uložení souboru, který končí „JSR SAVE“.
- Zavřete logický soubor pomocí rutiny CLOSE.
Následující program uloží soubor, který začíná z paměťových míst $C101 až $C200:
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 08 $; číslo zařízení pro první diskovou jednotku
LDY #$02 ; sekundární adresa
JSR SETLFS ; správně nastavit kanál
;
; Název souboru na disku (již v paměti za $ C301)
LDA # 09 $; délka názvu souboru
LDX # 01 $
LDY # $ C3
JSR SETNAM
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro výstup
LDX #40 $; logické číslo souboru
JSR CHKOUT ; pro psaní
;
; Výstupní soubor na disk
LDA # 01 $
STA $ 2 miliardy; TXTTAB
LDA # $ C1
STA $ 2C
LDX # 00 $
LDY#$C2
LDA # 2 miliardy $
JSR ULOŽIT
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
Všimněte si, že se jedná o program, který ukládá další část paměti (ne část programu) na disk (disketa pro Commodore-64).
5.9 Rutina NAČTENÍ OS
K rutině OS LOAD se přistupuje skokem (JSR) do tabulky skoků OS ROM na $FFD5. Když je část (velká oblast) paměti uložena na disk, je uložena s hlavičkou, která má počáteční adresu části v paměti. Podprogram OS LOAD načte bajty souboru do paměti. Při této operaci LOAD musí být hodnota akumulátoru 010 (00 $). Aby operace LOAD načetla počáteční adresu v hlavičce souboru na disku a vložila bajty souboru do paměti RAM počínaje touto adresou, musí být sekundární adresa kanálu 1 nebo 2 (následující program používá 2). Tato rutina vrací adresu plus 1 nejvyššího umístění RAM, které je načteno. To znamená, že dolní bajt poslední adresy souboru v RAM plus 1 je vložen do registru µP X a horní bajt poslední adresy souboru v RAM plus 1 je vložen do registru µP Y.
Pokud je načítání neúspěšné, registr µP A obsahuje číslo chyby (možná 4, 5, 8 nebo 9). Nastaví se také příznak C stavového registru mikroprocesoru (vyrobeno 1). Pokud je načítání úspěšné, není poslední hodnota registru A důležitá.
Nyní, v předchozí kapitole tohoto online kariérního kurzu, je první instrukce programu v assembleru na adrese v RAM, kde program začal. Nemusí to tak být. To znamená, že první instrukce programu nemusí být na začátku programu v RAM. Spouštěcí instrukce pro program může být kdekoli v souboru v paměti RAM. Programátorovi se doporučuje označit začátek instrukce v jazyce symbolických instrukcí START. Poté se program po načtení znovu spustí (spustí) s následující instrukcí assembleru:
JSR START
„JSR START“ je v programu v assembleru, který načte program, který má být spuštěn. Assembler, který načte jiný soubor assembleru a spustí načtený soubor, má následující kódovou proceduru:
- Nastavte kanál pomocí rutiny SETLFS.
- Pomocí rutiny SETNAM nastavte název logického souboru (číslo), který je stejný jako skutečný diskový soubor.
- Otevřete logický soubor pomocí rutiny OPEN.
- Udělejte z něj soubor pro vstup pomocí CHKIN.
- Kód pro načtení souboru jde sem a končí „JSR LOAD“.
- Zavřete logický soubor pomocí rutiny CLOSE.
Následující program načte soubor z disku a spustí jej:
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 08 $; číslo zařízení pro první diskovou jednotku
LDY #$02 ; sekundární adresa
JSR SETLFS ; správně nastavit kanál
;
; Název souboru na disku (již v paměti za $ C301)
LDA # 09 $; délka názvu souboru
LDX # 01 $
LDY#$C3
JSR SETNAM
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro vstup
LDX #40 $; logické číslo souboru
JSR CHKIN ; pro čtení
;
; Vstupní soubor z disku
LDA # 00 $
JSR LOAD
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
; Spusťte načtený program
JSR START
5.10 Modem a standard RS-232
Modem je zařízení (periferní zařízení), které převádí bity z počítače na odpovídající elektrické zvukové signály přenášené po telefonní lince. Na přijímací straně je modem před přijímajícím počítačem. Tento druhý modem převádí elektrické zvukové signály na bity pro přijímající počítač.
Modem musí být připojen k počítači na externím portu (na svislém povrchu počítače). Standard RS-232 označuje konkrétní typ konektoru, který připojuje modem k počítači (v minulosti). Jinými slovy, mnoho počítačů v minulosti mělo externí port, který byl konektorem RS-232 nebo konektorem kompatibilním s RS-232.
Systémová jednotka Commodore-64 (počítač) má na zadní vertikální ploše externí port, který se nazývá uživatelský port. Tento uživatelský port je kompatibilní s RS-232. Lze tam připojit modemové zařízení. Commodore-64 komunikuje s modemem přes tento uživatelský port. Operační systém ROM pro Commodore-64 má podprogramy pro komunikaci s modemem nazývané rutiny RS-232. Tyto rutiny mají položky v tabulce skoků.
Přenosová rychlost
Osmibitový bajt z počítače je před odesláním do modemu převeden na sérii osmi bitů. Opačný postup se provádí z modemu do počítače. Přenosová rychlost je počet bitů, které jsou přeneseny za sekundu v sérii.
Spodní část paměti
Termín „Bottom of Memory“ se nevztahuje na umístění bajtů paměti adresy 0000 $. Odkazuje na nejnižší místo RAM, kam může uživatel začít ukládat svá data a programy. Ve výchozím nastavení je to 0800 $. Připomeňme si z předchozí diskuse, že mnoho míst mezi $ 0800 a $ BFFF používá počítačový jazyk BASIC a jeho programátoři (uživatelé). Pouze $ C000 až $ CFFF adresová umístění jsou ponechána pro použití pro programy a data v assembleru; to jsou 4 kB z 64 kB paměti.
Horní část paměti
V těch dnech, kdy si klienti kupovali počítače Commodore-64, některé nepřišly se všemi paměťovými místy. Takové počítače měly ROM s operačním systémem od $E000 do $FFFF. Měli RAM od 0 000 $ do limitu, který není $ DFFF, vedle E 000 $. Limit byl pod $ DFFF a tento limit se nazývá „Top of Memory“. Top-of-memory tedy neodkazuje na umístění $FFFF.
Commodore-64 Buffer pro komunikaci RS-232
Vyrovnávací vyrovnávací paměť
Vyrovnávací paměť pro přenos RS-232 (výstup) zabírá 256 bajtů od horní části paměti směrem dolů. Ukazatel pro tuto vysílací vyrovnávací paměť je označen jako ROBUF. Tento ukazatel je na stránce nula s adresami $00F9 následovanými $00FA. ROBUF ve skutečnosti identifikuje $00F9. Pokud je tedy adresa pro začátek vyrovnávací paměti $BE00, nižší bajt $BE00, což je $00, je v umístění $00F9 a vyšší bajt $BE00, což je $BE, je v $00FA umístění.
Přijímání vyrovnávací paměti
Vyrovnávací paměť pro příjem RS-232 bajtů (vstup) zabírá 256 bajtů ze spodní části vysílací vyrovnávací paměti. Ukazatel pro tuto přijímací vyrovnávací paměť je označen jako RIBUF. Tento ukazatel je na stránce nula s adresami $00F7 následovanými $00F8. RIBUF ve skutečnosti identifikuje $00F7. Pokud je tedy adresa pro začátek vyrovnávací paměti $BF00, nižší bajt $BF00, což je $00, je v umístění $00F7 a vyšší bajt $BF00, což je $BF, je v $00F8. umístění. Takže 512 bajtů z horní části paměti se použije jako celková vyrovnávací paměť RAM RS-232.
Kanál RS-232
Když je modem připojen k (externímu) uživatelskému portu, komunikace s modemem je pouze komunikace RS-232. Postup pro vytvoření kompletního kanálu RS-232 je téměř stejný jako v předchozí diskusi, ale s jedním důležitým rozdílem: název souboru je kód a ne řetězec v paměti. Kód $0610 je dobrá volba. To znamená přenosovou rychlost 300 bitů/s a některé další technické parametry. Také neexistuje žádná sekundární adresa. Všimněte si, že číslo zařízení je 2. Postup pro nastavení kompletního kanálu RS-232 je:
- Nastavení kanálu pomocí rutiny SETLFS.
- Nastavení názvu logického souboru, $0610.
- Otevření logického souboru pomocí rutiny OPEN.
- Vytvoření souboru pro výstup pomocí CHKOUT nebo souboru pro vstup pomocí CHKIN.
- Odeslání jednotlivých bajtů pomocí CHROUT nebo příjem jednotlivých bajtů pomocí GETIN.
- Zavření logického souboru pomocí rutiny CLOSE.
K rutině OS GETIN se přistupuje přeskakováním (JSR) do tabulky skoků OS ROM na $FFE4. Tato rutina, když je volána, vezme bajt, který je odeslán do vyrovnávací paměti přijímače, a vloží (vrácení) jej do µP akumulátoru.
Následující program odešle bajt „E“ (ASCII) do modemu, který je připojen k uživatelskému portu kompatibilnímu s RS-232:
; Nastavení kanálu
LDA #40 $; logické číslo souboru
LDX # 02 $; číslo zařízení pro RS-232
LDY #$FF ; žádná sekundární adresa
JSR SETLFS ; správně nastavit kanál
;
; Název pro RS-232 je kód např. 0610 $
LDA # 02 $; délka kódu je 2 bajty
LDX #10 $
LDY # 06 $
JSR SETNAM
;
; Otevřete logický soubor
JSR OTEVŘENO
; Nastavte kanál pro výstup
LDX #40 $; logické číslo souboru
JSR CHKOUT
;
; Výstupní znak na RS-232, např. modem
LDA #45 $
JSR CHROUT
; Zavřete logický soubor
LDA #40 $
JSR ZAVŘENO
Pro příjem bajtu je kód velmi podobný, kromě toho, že „JSR CHKOUT“ je nahrazeno „JSR CHKIN“ a:
LDA #45 $
JSR CHROUT
je nahrazeno „JSR GETIN“ a výsledek bude umístěn do registru A.
Nepřetržité odesílání nebo přijímání bajtů se provádí smyčkou pro odesílání nebo přijímání segmentu kódu.
Všimněte si, že vstup a výstup u Commodore je ve většině případů podobný, s výjimkou klávesnice, kde některé rutiny nevolá programátor, ale volá je operační systém.
5.11 Počítání a časování
Zvažte sekvenci odpočítávání, která je:
2, 1, 0
Toto je odpočítávání od 2 do 0. Nyní zvažte opakující se sekvenci odpočítávání:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Toto je opakované odpočítávání stejné sekvence. Sekvence se opakuje čtyřikrát. Čtyři časy znamenají, že čas je 4. V rámci jedné sekvence se počítá. Opakování stejné sekvence je načasování.
V systémové jednotce Commodore-64 jsou dva komplexní adaptéry rozhraní. Každá CIA má dva obvody čítače/časovače pojmenované Timer A (TA) a Timer B (TB). Čítací obvod se neliší od časovacího obvodu. Počítadlo nebo časovač v Commodore-64 odkazuje na stejnou věc. Ve skutečnosti každý z nich v podstatě odkazuje na jeden 16bitový registr, který vždy odpočítává do 0 při impulsech systémových hodin. Do 16bitového registru lze nastavit různé hodnoty. Čím větší je hodnota, tím déle trvá odpočítávání k nule. Pokaždé, když jeden z časovačů překročí nulu, IRQ signál přerušení je odeslán do mikroprocesoru. Když počítání klesne za nulu, nazývá se to podtečení.
V závislosti na tom, jak je naprogramován obvod časovače, může časovač běžet v jednorázovém režimu nebo v nepřetržitém režimu. Na předchozím obrázku jednorázový režim znamená „proveďte 2, 1, 0“ a zastavte se, zatímco hodinové pulsy pokračují. Nepřetržitý režim je jako „2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0 atd. který pokračuje s hodinovými impulsy. To znamená, že když překročí nulu, pokud není zadán žádný pokyn, sekvence odpočítávání se opakuje. Největší číslo je obvykle mnohem větší než 2.
Generuje časovač A (TA) CIA #1 IRQ v pravidelných intervalech (dobách trvání) provádět servis klávesnice. Ve skutečnosti je to standardně každou 1/60 sekundy. IRQ je odeslána do mikroprocesoru každou 1/60 sekundy. Je to jen když IRQ je odesláno, že program může přečíst hodnotu klíče z fronty klávesnice (bufferu). Pamatujte, že mikroprocesor má pouze jeden pin pro IRQ signál. Mikroprocesor má také pouze jeden pin pro NMI signál. Signál ¯NMI do mikroprocesoru vždy pochází z CIA #2.
16bitový registr časovače má dvě adresy paměti: jednu pro nižší bajt a jednu pro vyšší bajt. Každá CIA má dva časové obvody. Obě CIA jsou totožné. Pro CIA #1 jsou adresy pro dva časovače: DC04 a DC05 pro TA a DC06 a DC07 pro TB. Pro CIA #2 jsou adresy pro dva časovače: DD04 a DD05 pro TA a DD06 a DD07 pro TB.
Předpokládejme, že číslo 25510 má být odesláno do časovače TA CIA #2 pro odpočítávání. 25510 = 00000000111111112 je v šestnácti bitech. 00000000111111112 = $000FFF je v šestnáctkové soustavě. V tomto případě se do registru odešle $FF na adresu $DD04 a $00 se odešle do registru na adresu $DD05 – little endianness. Následující segment kódu odešle číslo do registru:
LDA # $ FF
STÁT $ DD04
LDA # 00 $
STÁT DD05 USD
Ačkoli registry v CIA mají adresy RAM, jsou fyzicky v CIA a CIA je samostatný IC od RAM nebo ROM.
To není vše! Když je časovači přiděleno číslo pro odpočítávání, jako u předchozího kódu, odpočítávání nezačne. Odpočítávání začíná, když byl do odpovídajícího řídicího registru pro časovač odeslán osmibitový bajt. První bit tohoto bajtu pro řídicí registr udává, zda má nebo nemá začít odpočítávání. Hodnota 0 pro tento první bit znamená zastavení odpočítávání, zatímco hodnota 1 znamená zahájení odpočítávání. Také byte musí udávat, zda je odpočítávání v režimu jednoho výstřelu (jednorázového) nebo v režimu volného běhu (nepřetržitý režim). Jednorázový režim odpočítává a zastaví se, když hodnota registru časovače klesne na nulu. V režimu volného chodu se odpočítávání opakuje po dosažení 0. Čtvrtý (index 3) bit bajtu, který je odeslán do řídicího registru, označuje režim: 0 znamená režim volného chodu a 1 znamená jednorázový režim.
Vhodné číslo pro zahájení počítání v režimu jednoho výstřelu je 000010012 = 09 $ v šestnáctkové soustavě. Vhodné číslo pro zahájení počítání v režimu volného běhu je 000000012 = 01 $ v šestnáctkové soustavě. Každý registr časovače má svůj vlastní řídicí registr. V CIA #1 má řídicí registr pro časovač A adresu RAM DC0E16 a řídicí registr pro časovač B má adresu RAM DC0F16. V CIA #2 má řídicí registr pro časovač A adresu RAM DD0E16 a řídicí registr pro časovač B má adresu RAM DD0F16. Chcete-li začít odpočítávat šestnáctibitové číslo v TA CIA #2, v jednorázovém režimu, použijte následující kód:
LDA # 09 $
STA $ DD0E
Chcete-li začít odpočítávat šestnáctibitové číslo v TA CIA #2, v režimu volného běhu, použijte následující kód:
LDA # 01 $
STA $ DD0E
5.12 IRQ a NMI Žádosti
Mikroprocesor 6502 má IRQ a NMI čáry (špendlíky). Jak CIA #1, tak CIA #2, každá má IRQ pin pro mikroprocesor. The IRQ kolík CIA #2 je připojen k NMI kolík µP. The IRQ kolík CIA #1 je připojen k IRQ kolík µP. To jsou jediné dvě přerušovací linky, které spojují mikroprocesor. Takže IRQ pin CIA #2 je NMI zdroj a může být také viděn jako linie ¯NMI.
CIA #1 má pět možných bezprostředních zdrojů generování IRQ signál pro µP. CIA #2 má stejnou strukturu jako CIA #1. Takže CIA č. 2 má stejných pět možných okamžitých zdrojů generování signálu přerušení, což je tentokrát NMI signál. Pamatujte, že když µP přijme NMI signál, pokud obsluhuje IRQ žádost, pozastaví ji a vyřídí NMI žádost. Když dokončí manipulaci s NMI žádost, poté obnoví zpracování IRQ žádost.
CIA #1 je normálně připojena externě ke klávesnici a hernímu zařízení, jako je joystick. Klávesnice využívá více portu A CIA #1 než port B. Herní zařízení využívá více CIA #1 portu B než jeho portu A. CIA #2 je normálně připojena externě k diskové jednotce (zapojená do tiskárny) a modem. Disková jednotka využívá více portu A CIA #2 (i když přes externí sériový port) než jeho port B. Modem (RS-232) využívá více CIA #2 portu B než jeho port A.
S tím vším, jak systémová jednotka ví, co způsobuje IRQ nebo NMI přerušit? CIA #1 a CIA #2 mají pět bezprostředních zdrojů přerušení. Pokud je signál přerušení do µP NMI , zdroj je jedním z bezprostředních pěti zdrojů od CIA #2. Pokud je signál přerušení do µP IRQ , zdroj je jedním z bezprostředních pěti zdrojů od CIA #1.
Další otázka zní: 'Jak systémová jednotka rozlišuje mezi pěti bezprostředními zdroji každé CIA?' Každá CIA má osmibitový registr, který se nazývá Interrupt Control Register (ICR). ICR obsluhuje oba přístavy CIA. Následující tabulka ukazuje významy osmi bitů registru řízení přerušení, počínaje bitem 0:
| Tabulka 5.13 Řídicí registr přerušení |
|
|---|---|
| Bit Index | Význam |
| 0 | Nastavte (provedeno 1) podtečením časovače A |
| 1 | Nastaveno podtečením časovače B |
| 2 | Nastavte, kdy se čas denního času rovná budíku |
| 3 | Nastavte, když je sériový port plný |
| 4 | Nastavení externím zařízením |
| 5 | Nepoužito (vyrobeno 0) |
| 6 | Nepoužito (vyrobeno 0) |
| 7 | Nastavte, když je nastaven kterýkoli z prvních pěti bitů |
Jak je vidět z tabulky, každý z bezprostředních zdrojů je reprezentován jedním z prvních pěti bitů. Když je tedy signál přerušení přijat na µP, musí být proveden kód, aby se načetl obsah registru řízení přerušení, aby se zjistil přesný zdroj přerušení. Adresa RAM pro ICR CIA #1 je DC0D16. Adresa RAM pro ICR CIA #2 je DD0D16. Chcete-li přečíst (vrátit) obsah ICR CIA #1 do µP akumulátoru, zadejte následující instrukce:
LDA $ DC0D
Chcete-li přečíst (vrátit) obsah ICR CIA #2 do µP akumulátoru, zadejte následující instrukce:
LDA DD0D $
5.13 Program na pozadí řízený přerušením
Klávesnice normálně přeruší mikroprocesor každou 1/60 sekundy. Představte si, že program běží a dosáhne pozice, kdy čeká na klávesu z klávesnice, než bude moci pokračovat segmenty kódu níže. Předpokládejme, že pokud není na klávesnici stisknuta žádná klávesa, program provede pouze malou smyčku a čeká na klávesu. Představte si, že program běží a právě po přerušení klávesnice očekává klávesu z klávesnice. V tu chvíli se celý počítač nepřímo zastaví a nedělá nic jiného než čekací smyčku. Představte si, že je klávesa klávesnice stisknuta těsně před dalším vydáním dalšího přerušení klávesnice. To znamená, že počítač nedělal asi jednu šedesátinu sekundy nic! To je dlouhá doba na to, aby počítač nic nedělal, dokonce ani v dobách Commodore-64. Počítač mohl za tu dobu (trvání) dělat něco jiného. V programu je mnoho takových trvání.
Druhý program může být napsán tak, aby pracoval v takových „nečinných“ dobách. O takovém programu se říká, že pracuje na pozadí hlavního (nebo prvního) programu. Snadný způsob, jak toho dosáhnout, je vynutit si modifikované zpracování přerušení BRK, když je z klávesnice očekávána klávesa.
Ukazatel pro instrukci BRK
Na po sobě jdoucích místech RAM adres $0316 a $0317 je ukazatel (vektor) pro aktuální instrukční rutinu BRK. Výchozí ukazatel je umístěn tam, když je počítač zapnutý operačním systémem v ROM. Tento výchozí ukazatel je adresa, která stále ukazuje na výchozí obslužnou rutinu instrukce BRK v operační paměti ROM. Ukazatel je 16bitová adresa. Nižší bajt ukazatele je umístěn do umístění bajtů adresy $0306 a vyšší bajt ukazatele je umístěn do umístění bajtů $0317.
Druhý program může být napsán tak, že když je systém „nečinný“, některé kódy druhého programu jsou systémem vykonávány. To znamená, že druhý program se musí skládat z podprogramů. Když je systém „nečinný“, který čeká na klávesu z klávesnice, provede se další podprogram pro druhý program. Interakce člověka s počítačem je pomalá ve srovnání s provozem systémové jednotky.
Tento problém je snadné vyřešit: Pokaždé, když musí počítač čekat na klávesu z klávesnice, vložte do kódu instrukci BRK a nahraďte ukazatel na $0316 (a $0317) ukazatelem dalšího podprogramu druhého ( vlastní) program. Tímto způsobem by oba programy běžely po dobu, která není o mnoho delší než doba trvání hlavního programu, který běží samostatně.
5.14 Sestavení a kompilace
Assembler nahradí všechny štítky adresami. Program v assembleru je normálně napsán tak, aby začínal na konkrétní adrese. Výsledek z assembleru (po sestavení) se nazývá „objektový kód“ se vším v binárním tvaru. Tento výsledek je spustitelný soubor, pokud je soubor program a ne dokument. Dokument není spustitelný.
Aplikace se skládá z více než jednoho programu (jazyk pro sestavení). Tam je obvykle hlavní program. Tato situace by neměla být zaměňována se situací pro programy na pozadí řízené přerušením. Všechny programy zde jsou programy v popředí, ale existuje první nebo hlavní program.
Pokud existuje více než jeden program v popředí, místo assembleru je potřeba kompilátor. Kompilátor sestaví každý z programů do objektového kódu. Nastal by však problém: některé segmenty kódu se budou překrývat, protože programy pravděpodobně píší různí lidé. Řešením kompilátoru je přesunout všechny překrývající se programy kromě prvního na paměťový prostor, aby se programy nepřekrývaly. Nyní, pokud jde o ukládání proměnných, některé adresy proměnných by se stále překrývaly. Řešením je zde nahradit překrývající se adresy novými adresami (kromě prvního programu), aby se již nepřekrývaly. Tímto způsobem se různé programy vejdou do různých částí (oblastí) paměti.
Díky tomu všemu je možné, aby jedna rutina v jednom programu vyvolala rutinu v jiném programu. Překladač tedy provede propojení. Propojení znamená mít počáteční adresu podprogramu v jednom programu a pak ji zavolat v jiném programu; obojí je součástí aplikace. Oba programy k tomu potřebují používat stejnou adresu. Konečným výsledkem je jeden velký objektový kód se vším v binárním (bitech).
5.15 Ukládání, načítání a spouštění programu
Jazyk symbolických instrukcí je normálně napsán v některém editorovém programu (který může být součástí programu assembler). Editor program udává, kde program začíná a končí v paměti (RAM). Rutina Kernal SAVE OS ROM Commodore-64 může uložit program z paměti na disk. Pouze vypíše část (blok) paměti, která může obsahovat volání instrukce na disk. Volající instrukci na SAVE je vhodné mít oddělenou od ukládaného programu, aby se program při načítání do paměti z disku znovu sám při spuštění neukládal. Načtení programu v assembleru z disku je jiný druh výzvy, protože program se nemůže načíst sám.
Program se nemůže načíst z disku na místo, kde začíná a končí v paměti RAM. Commodore-64 v té době byly běžně dodávány s tlumočníkem BASIC pro spuštění programů jazyka BASIC. Když je stroj (počítač) zapnutý, nastaví se příkazový řádek: PŘIPRAVENO. Odtud lze BASIC příkazy nebo instrukce zadávat stisknutím klávesy „Enter“ po zadání. BASIC příkaz (instrukce) pro načtení souboru je:
NAČÍST „název souboru“,8,1
Příkaz začíná BASIC rezervovaným slovem, které je LOAD. Následuje mezera a poté název souboru ve dvojitých uvozovkách. Následuje číslo zařízení 8, kterému předchází čárka. Za sekundární adresou disku, která je 1, následuje čárka. U takového souboru je počáteční adresa programu v assembleru v záhlaví souboru na disku. Když BASIC dokončí načítání programu, vrátí se poslední adresa RAM plus 1 programu. Slovo „vráceno“ zde znamená, že nižší bajt poslední adresy plus 1 je vložen do registru µP X a vyšší bajt poslední adresy plus 1 je vložen do registru µP Y.
Po načtení programu je nutné jej spustit (vykonat). Uživatel programu musí znát počáteční adresu pro spuštění v paměti. Opět je zde nutný další BASIC program. Je to příkaz SYS. Po provedení příkazu SYS se spustí (a zastaví) program assembleru. Pokud je za běhu potřeba nějaký vstup z klávesnice, program v jazyce symbolických instrukcí by to měl uživateli oznámit. Poté, co uživatel zadá data na klávesnici a stiskne klávesu „Enter“, program v jazyce symbolických instrukcí bude pokračovat v běhu pomocí zadávání z klávesnice bez zásahu překladače BASIC.
Za předpokladu, že začátek spouštěcí (spouštěcí) adresy RAM pro program v assembleru je C12316, C123 se před použitím s příkazem SYS převede na základní deset. Převod C12316 na základ deset je následující:
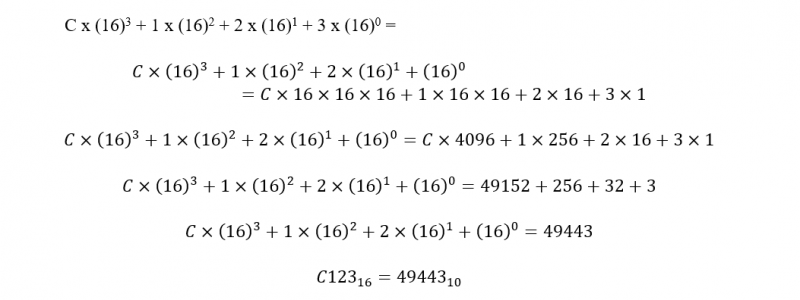
Takže příkaz BASIC SYS je:
SYS 49443
5.16 Zavádění pro Commodore-64
Zavádění pro Commodore-64 se skládá ze dvou fází: fáze resetování hardwaru a fáze inicializace operačního systému. Operačním systémem je jádro v ROM (a ne na disku). Existuje resetovací linka (ve skutečnosti RES ), který se připojuje ke kolíku na 6502 µP a ke stejnému názvu kolíku ve všech speciálních lodích, jako jsou CIA 1, CIA 2 a VIC II. Ve fázi resetu jsou díky této lince všechny registry v µP a ve speciálních čipech resetovány na 0 (vynulovány pro každý bit). Dále, hardwarem mikroprocesoru, ukazatel zásobníku a stavový registr procesoru jsou dány jejich počátečními hodnotami v mikroprocesoru. Čítač programu je pak uveden s hodnotou (adresou) v umístěních $FFFC a $FFFD. Připomeňme, že počítadlo programu obsahuje adresu další instrukce. Obsah (adresa), který je zde uložen, je pro podprogram, který zahajuje inicializaci softwaru. Vše zatím zajišťuje hardware mikroprocesoru. V této fázi se nedotkne celé paměti. Poté začíná další fáze inicializace.
Inicializace se provádí některými rutinami v ROM OS. Inicializace znamená předání počátečních nebo výchozích hodnot některým registrům ve speciálních čipech. Inicializace začíná zadáním počátečních nebo výchozích hodnot některým registrům ve speciálních čipech. IRQ , například musí začít vydávat každou 1/60 sekundy. Takže jeho odpovídající časovač v CIA #1 musí být nastaven na výchozí hodnotu.
Dále jádro provede test RAM. Testuje každé umístění odesláním bajtu na místo a jeho zpětným přečtením. Pokud existuje rozdíl, alespoň to umístění je špatné. Kernal také identifikuje horní část paměti a spodní část paměti a nastavuje odpovídající ukazatele na stránce 2. Pokud je horní část paměti $ DFFF, $ FF je vložen do umístění $ 0283 a $ DF je vložen do umístění $ 0284 bajtů. Jak $0283, tak $0284 mají označení HIRAM. Pokud je spodní část paměti $0800, $00 se vloží do pozice $0281 a $08 do pozice $0282. Jak $0281, tak $0282 mají označení LORAM. Test RAM ve skutečnosti začíná od 0300 $ až po horní část paměti (RAM).
Nakonec jsou vstupní/výstupní vektory (ukazatele) nastaveny na své výchozí hodnoty. Test RAM ve skutečnosti začíná od 0300 $ až po horní část paměti (RAM). To znamená, že stránka 0, stránka 1 a stránka 2 jsou inicializovány. Zejména stránka 0 má mnoho ukazatelů OS ROM a stránka 2 má mnoho ukazatelů BASIC. Tyto ukazatele se označují jako proměnné. Pamatujte, že stránka 1 je zásobník. Ukazatele se označují jako proměnné, protože mají jména (návěsky). V této fázi se vymaže paměť obrazovky pro obrazovku (monitor). To znamená odeslání kódu 20 $ za místo (což je shodou okolností stejné jako ASCII 20 $) na místa na obrazovce 1000 RAM. Nakonec Kernal spustí interpret BASIC a zobrazí příkazový řádek BASIC, který je READY v horní části monitoru (obrazovky).
5.17 Problémy
Čtenáři se doporučuje vyřešit všechny problémy v kapitole, než přejde k další kapitole.
- Napište kód assembleru, který učiní všechny bity CIA #2 portu A jako výstup a CIA #2 portu B jako vstup.
- Napište kód jazyka sestavení 6502, který čeká na klávesu klávesnice, dokud nebude stisknuta.
- Napište program v jazyce sestavení 6502, který odešle znak „E“ na obrazovku Commodore-64.
- Napište program v jazyce sestavení 6502, který vezme znak z klávesnice a odešle ho na obrazovku Commodore-64, ignoruje kód klíče a načasování.
- Napište program v jazyce sestavení 6502, který obdrží bajt z diskety Commodore-64.
- Napište program v jazyce sestavení 6502, který uloží soubor na disketu Commodore-64.
- Napište program v jazyce sestavení 6502, který načte soubor programu z diskety Commodore-64 a spustí jej.
- Napište program v jazyce sestavení 6502, který odešle bajt „E“ (ASCII) do modemu, který je připojen k uživatelskému portu Commodore-64 kompatibilnímu s RS-232.
- Vysvětlete, jak se v počítači Commodore-64 provádí počítání a časování.
- Vysvětlete, jak může systémová jednotka Commodore-64 identifikovat 10 různých zdrojů okamžitých požadavků na přerušení, včetně nemaskovatelných požadavků na přerušení.
- Vysvětlete, jak může program na pozadí běžet s programem v popředí v počítači Commodore-64.
- Stručně vysvětlete, jak lze programy v assembleru zkompilovat do jedné aplikace pro počítač Commodore-64.
- Stručně vysvětlete proces spouštění počítače Commodore-64.