Syntax:
Klouzavý průměr můžeme vypočítat různými způsoby, které jsou následující:
Metoda 1:
NumPy. cumsum ( )Vrací součet prvků v daném poli. Klouzavý průměr můžeme vypočítat vydělením výstupu cumsum() velikostí pole.
Metoda 2:
NumPy. a . průměrný ( )Má následující parametry.
a: data ve formě pole, která mají být zprůměrována.
axis: její datový typ je int a je to volitelný parametr.
hmotnost: je to také pole a volitelný parametr. Může mít stejný tvar jako 1-D tvar. V případě jednoho rozměru musí mít stejnou délku jako pole „a“.
Všimněte si, že se zdá, že v NumPy neexistuje žádná standardní funkce pro výpočet klouzavého průměru, takže to lze provést některými jinými metodami.
Metoda 3:
Další metoda, kterou lze použít k výpočtu klouzavého průměru, je:
např. vinout se ( A , v , režimu = 'úplný' )V této syntaxi je a první vstupní rozměr a v je druhá vstupní rozměrová hodnota. Režim je volitelná hodnota, může být plná, stejná a platná.
Příklad č. 01:
Nyní, abychom více vysvětlili klouzavý průměr v Numpy, uveďme příklad. V tomto příkladu vyjmeme klouzavý průměr pole s funkcí convolve NumPy. Vezmeme tedy pole „a“ s 1,2,3,4,5 jako jeho prvky. Nyní zavoláme funkci np.convolve a uložíme její výstup do naší proměnné „b“. Poté vytiskneme hodnotu naší proměnné „b“. Tato funkce vypočítá pohyblivý součet našeho vstupního pole. Výstup vytiskneme, abychom viděli, zda je náš výstup správný nebo ne.
Poté převedeme náš výstup na klouzavý průměr pomocí stejné konvolvovací metody. Pro výpočet klouzavého průměru budeme muset klouzavý součet vydělit počtem vzorků. Ale hlavním problémem je, že jelikož se jedná o klouzavý průměr, počet vzorků se neustále mění v závislosti na místě, kde se nacházíme. Abychom tento problém vyřešili, jednoduše vytvoříme seznam jmenovatelů a musíme z něj udělat průměr.
Za tímto účelem jsme inicializovali další proměnnou „denom“ pro jmenovatele. Pro pochopení seznamu je to jednoduché pomocí triku s rozsahem. Naše pole má pět různých prvků, takže počet vzorků na každém místě se bude pohybovat od jedné do pěti a poté se sníží z pěti na jednu. Jednoduše tedy sečteme dva seznamy a uložíme je do našeho parametru „denom“. Nyní tuto proměnnou vytiskneme, abychom zkontrolovali, zda nám systém dal skutečné jmenovatele nebo ne. Poté náš pohyblivý součet vydělíme jmenovateli a vytiskneme jej uložením výstupu do proměnné „c“. Spusťte náš kód, abychom zkontrolovali výsledky.
import nemotorný tak jako např.A = [ 1 , dva , 3 , 4 , 5 ]
b = např. vinout se ( A , např. ty_jako ( A ) )
tisk ( 'Pohyblivý součet' , b )
název = seznam ( rozsah ( 1 , 5 ) ) + seznam ( rozsah ( 5 , 0 , - 1 ) )
tisk ( 'jmenovatelé' , název )
C = např. vinout se ( A , např. ty_jako ( A ) ) / název
tisk ( 'Klouzavý průměr' , C )
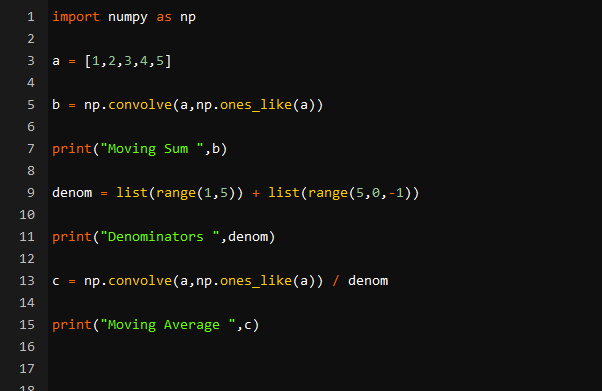
Po úspěšném provedení našeho kódu získáme následující výstup. V prvním řádku jsme vytiskli „Moving Sum“. Vidíme, že máme „1“ na začátku a „5“ na konci pole, stejně jako jsme měli v našem původním poli. Zbytek čísel jsou součty různých prvků našeho pole.
Například šest na třetím indexu pole pochází z přidání 1, 2 a 3 z našeho vstupního pole. Deset na čtvrtém indexu pochází z 1, 2, 3 a 4. Patnáctka pochází ze sečtení všech čísel dohromady a tak dále. Nyní, ve druhém řádku našeho výstupu, jsme vytiskli jmenovatele našeho pole.
Z našeho výstupu vidíme, že všechny jmenovatele jsou přesné, což znamená, že je můžeme rozdělit pomocí našeho pole pohyblivých součtů. Nyní přejděte na poslední řádek výstupu. V posledním řádku můžeme vidět, že první prvek našeho pole klouzavého průměru je 1. Průměr 1 je 1, takže náš první prvek je správný. Průměr 1+2/2 bude 1,5. Vidíme, že druhý prvek našeho výstupního pole je 1,5, takže druhý průměr je také správný. Průměr 1,2,3 bude 6/3=2. Také to dělá náš výstup správným. Z výstupu tedy můžeme říci, že jsme úspěšně vypočítali klouzavý průměr pole.
Závěr
V této příručce jsme se dozvěděli o klouzavých průměrech: co je klouzavý průměr, k čemu se používá a jak klouzavý průměr vypočítat. Podrobně jsme to studovali jak z matematického, tak z programátorského hlediska. V NumPy neexistuje žádná specifická funkce nebo proces pro výpočet klouzavého průměru. Existují však různé další funkce, s jejichž pomocí můžeme vypočítat klouzavý průměr. Udělali jsme příklad pro výpočet klouzavého průměru a popsali každý krok našeho příkladu. Klouzavé průměry jsou užitečným přístupem k předpovídání budoucích výsledků s pomocí existujících dat.