Vícenásobné zpracování je srovnatelné s vícevláknovým zpracováním. Liší se však tím, že můžeme spustit pouze jedno vlákno najednou díky GIL, který se používá pro vytváření vláken. Multiprocessing je proces postupného provádění operací napříč několika jádry CPU. Vlákna nelze provozovat paralelně. Multiprocessing nám však umožňuje vytvořit procesy a spouštět je souběžně na různých jádrech CPU. Smyčka, jako je for-loop, je jedním z nejčastěji používaných skriptovacích jazyků. Opakujte stejnou práci s různými daty, dokud není dosaženo kritéria, jako je předem stanovený počet iterací. Cyklus provádí každou iteraci jednu po druhé.
Příklad 1: Využití For-Loop v modulu Python Multiprocessing Module
V tomto příkladu používáme for-loop a proces třídy modulu Python multiprocessing. Začneme velmi přímočarým příkladem, abyste rychle pochopili, jak funguje multiprocesní for-loop v Pythonu. Pomocí rozhraní, které je srovnatelné s modulem pro závitování, multiprocessing obsahuje vytváření procesů.
Použitím podprocesů spíše než vláken poskytuje multiprocesní balíček lokální i vzdálenou souběžnost, čímž se vyhne Global Interpreter Lock. Použijte for-loop, což může být objekt typu řetězec nebo n-tice, k neustálému procházení sekvencí. To funguje méně jako klíčové slovo v jiných programovacích jazycích a více jako metoda iterátoru nalezená v jiných programovacích jazycích. Spuštěním nového multiprocesingu můžete spustit smyčku for, která provádí proceduru souběžně.
Začněme implementací kódu pro spuštění kódu pomocí nástroje „spyder“. Věříme, že „spyder“ je také nejlepší pro provozování Pythonu. Importujeme proces multiprocessingového modulu, na kterém běží kód. Multiprocessing v konceptu Pythonu nazývaný „třída procesů“ vytváří nový proces Pythonu, dává mu metodu pro spouštění kódu a dává nadřazené aplikaci způsob, jak spouštění řídit. Třída Process obsahuje procedury start() a join(), obě jsou klíčové.
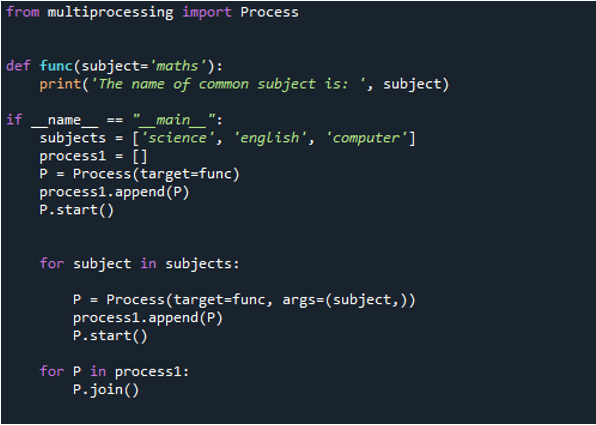
Dále definujeme uživatelem definovanou funkci nazvanou „func“. Protože se jedná o uživatelsky definovanou funkci, pojmenujeme ji podle vlastního výběru. Uvnitř těla této funkce předáme proměnnou „subject“ jako argument a hodnotu „maths“. Dále zavoláme funkci „print()“, předáme příkaz „Jméno společného subjektu je“ a také jeho argument „předmět“, který obsahuje hodnotu. Poté v následujícím kroku použijeme „if name== _main_“, které vám zabrání spustit kód, když je soubor importován jako modul, a umožní vám to pouze tehdy, když je obsah spuštěn jako skript.
Část podmínky, se kterou začínáte, může být ve většině případů považována za umístění poskytující obsah, který by měl být spuštěn pouze tehdy, když je váš soubor spuštěn jako skript. Potom použijeme předmět argumentu a uložíme do něj některé hodnoty, které jsou „věda“, „angličtina“ a „počítač“. Proces pak v následujícím kroku dostane název „process1[]“. Potom použijeme „process(target=func)“ k volání funkce v procesu. Target se používá k volání funkce a tento proces uložíme do proměnné „P“.
Dále použijeme „process1“ k volání funkce „append()“, která přidá položku na konec seznamu, který máme ve funkci „func“. Protože je proces uložen v proměnné „P“, předáme této funkci jako její argument „P“. Nakonec použijeme funkci „start()“ s „P“ ke spuštění procesu. Poté metodu spustíme znovu, přičemž dodáme argument „předmět“ a v předmětu použijeme „pro“. Poté znovu pomocí „process1“ a „add()“ zahájíme proces. Proces pak běží a výstup je vrácen. Proceduře je pak řečeno, aby skončila pomocí techniky „join()“. Procesy, které nevolají proceduru „join()“, se neukončí. Jedním zásadním bodem je, že parametr klíčového slova „args“ musí být použit, pokud chcete během procesu poskytnout nějaké argumenty.
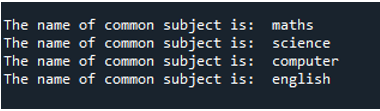
Nyní můžete ve výstupu vidět, že příkaz se zobrazí nejprve předáním hodnoty pro předmět „math“, kterou předáme do funkce „func“, protože ji nejprve zavoláme pomocí funkce „process“. Poté použijeme příkaz „append()“, abychom měli hodnoty, které již byly v seznamu, který je přidán na konec. Poté byly prezentovány „věda“, „počítač“ a „angličtina“. Ale jak vidíte, hodnoty nejsou ve správném pořadí. Je to proto, že tak učiní tak rychle, jak je procedura dokončena, a nahlásí svou zprávu.
Příklad 2: Konverze sekvenčního For-Loop na multiprocessingový paralelní For-Loop
V tomto příkladu je úloha smyčky s více zpracováním prováděna postupně, než je převedena na úlohu paralelní smyčky for-loop. Pomocí for-loops můžete procházet sekvencemi, jako je kolekce nebo řetězec, v pořadí, v jakém se vyskytují.
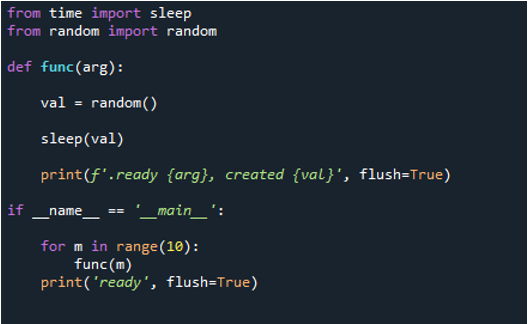
Nyní začneme implementovat kód. Nejprve importujeme „spánek“ z časového modulu. Pomocí procedury „sleep()“ v časovém modulu můžete pozastavit provádění volajícího vlákna na jak dlouho budete chtít. Poté použijeme „random“ z náhodného modulu, definujeme funkci s názvem „func“ a předáme klíčové slovo „argu“. Poté vytvoříme náhodnou hodnotu pomocí „val“ a nastavíme ji na „random“. Poté pomocí metody „sleep()“ na krátkou dobu zablokujeme a jako parametr předáme „val“. Poté, abychom zprávu odeslali, spustíme metodu „print()“, předáme slova „ready“ a klíčové slovo „arg“ jako její parametr, dále „vytvořeno“ a předáme hodnotu pomocí „val“.
Nakonec použijeme „flush“ a nastavíme jej na „True“. Uživatel se může rozhodnout, zda má či nemá výstup uložit do vyrovnávací paměti pomocí možnosti flush ve funkci tisku Pythonu. Výchozí hodnota tohoto parametru False znamená, že výstup nebude ukládán do vyrovnávací paměti. Výstup se zobrazí jako řada řádků za sebou, pokud nastavíte hodnotu true. Potom použijeme „if name== main“ k zabezpečení vstupních bodů. Dále provedeme úlohu postupně. Zde nastavíme rozsah na „10“, což znamená, že smyčka skončí po 10 iteracích. Dále zavoláme funkci „print()“, předáme jí vstupní příkaz „ready“ a použijeme volbu „flush=True“.
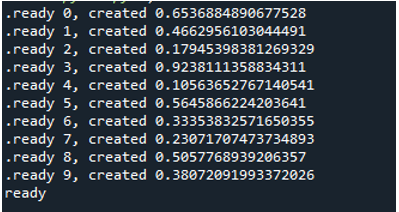
Nyní můžete vidět, že když spustíme kód, smyčka způsobí, že se funkce spustí „10“krát. Opakuje se 10krát, počínaje indexem nula a končící indexem devět. Každá zpráva obsahuje číslo úkolu, což je číslo funkce, které předáváme jako „argument“ a číslo vytvoření.
Tato sekvenční smyčka se nyní transformuje na paralelní for-loop s více zpracováním. Používáme stejný kód, ale chystáme se na nějaké další knihovny a funkce pro multiprocessing. Proto musíme importovat proces z multiprocessingu, jak jsme vysvětlili dříve. Dále vytvoříme funkci nazvanou „func“ a předáme klíčové slovo „arg“ před použitím „val=random“ k získání náhodného čísla.
Poté, po vyvolání metody „print()“ pro zobrazení zprávy a zadání parametru „val“ pro zdržení o malou tečku, použijeme funkci „if name= main“ k zabezpečení vstupních bodů. Poté vytvoříme proces a zavoláme funkci v procesu pomocí „process“ a předáme „target=func“. Poté předáme „func“, „arg“, předáme hodnotu „m“ a předáme rozsah „10“, což znamená, že smyčka ukončí funkci po „10“ iteracích. Poté proces spustíme pomocí metody „start()“ s „process“. Poté zavoláme metodu „join()“, abychom počkali na provedení procesu a dokončili celý proces poté.
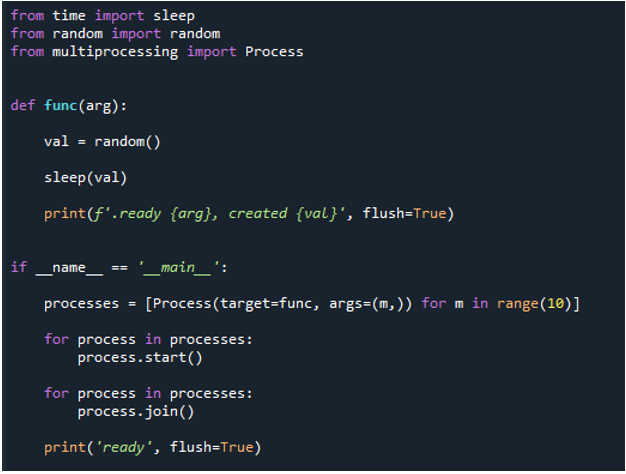
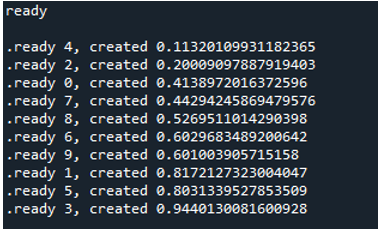
Proto, když spustíme kód, funkce zavolají hlavní proces a zahájí jejich provádění. Dělají se však, dokud nejsou splněny všechny úkoly. Vidíme to, protože každý úkol se provádí souběžně. Svou zprávu hlásí, jakmile je dokončena. To znamená, že ačkoli jsou zprávy mimo pořadí, smyčka skončí po dokončení všech „10“ iterací.
Závěr
V tomto článku jsme se zabývali multiprocesním for-loop v Pythonu. Představili jsme také dvě ilustrace. První obrázek ukazuje, jak využít for-loop v knihovně pro více zpracování smyček Pythonu. A druhý obrázek ukazuje, jak změnit sekvenční for-loop na paralelní multiprocessing for-loop. Před vytvořením skriptu pro multiprocesing v Pythonu musíme importovat modul multiprocessingu.