Vytvořit sbírku
Před použitím indexů musíme vytvořit novou kolekci v našem MongoDB. Již jsme vytvořili jeden a vložili 10 dokumentů s názvem „Dummy“. Funkce find() MongoDB zobrazí všechny záznamy z kolekce „Dummy“ na obrazovce shellu MongoDB níže.
test> db.Dummy.find() 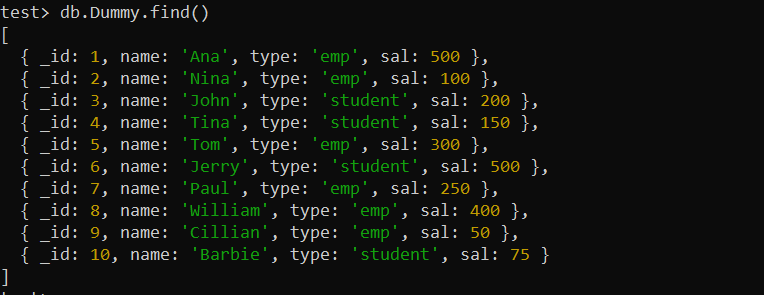
Vyberte Typ indexování
Před vytvořením indexu musíte nejprve určit sloupce, které se budou běžně používat v kritériích dotazu. Indexy fungují dobře ve sloupcích, které se často filtrují, třídí nebo prohledávají. Pole s velkou mohutností (mnoho různých hodnot) jsou často vynikajícími možnostmi indexování. Zde je několik příkladů kódu pro různé typy indexů.
Příklad 01: Index jednoho pole
Je to pravděpodobně nejzákladnější typ indexu, který indexuje jeden sloupec pro zvýšení rychlosti dotazování v tomto sloupci. Tento typ indexu se používá pro dotazy, ve kterých k dotazování na záznamy kolekce používáte jedno klíčové pole. Předpokládejme, že používáte pole „typ“ k dotazu na záznamy kolekce „Dummy“ ve funkci hledání, jak je uvedeno níže. Tento příkaz by prohledal celou kolekci, což může trvat dlouho, než se velké kolekce zpracují. Proto musíme optimalizovat výkon tohoto dotazu.
test> db.Dummy.find({type: 'emp' })
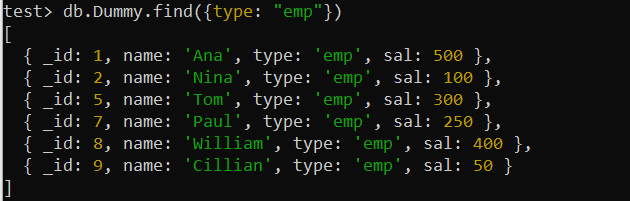
Záznamy kolekce Dummy výše byly nalezeny pomocí pole „type“, tj. obsahujícího podmínku. Proto lze index s jedním klíčem využít k optimalizaci vyhledávacího dotazu. Použijeme tedy funkci createIndex() MongoDB k vytvoření indexu v poli „type“ kolekce „Dummy“. Ilustrace použití tohoto dotazu ukazuje úspěšné vytvoření jednoklíčového indexu s názvem „typ_1“ v shellu.
test> db.Dummy.createIndex({ typ: 1 })Použijme dotaz find(), jakmile získá využití pole „type“. Operace bude nyní výrazně rychlejší než dříve používaná funkce find(), protože index je na místě, protože MongoDB může index využít k rychlému načtení záznamů s požadovaným názvem úlohy.
test> db.Dummy.find({type: 'emp' })
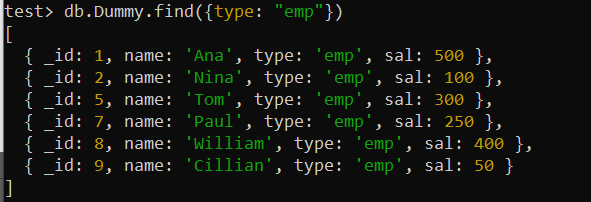
Příklad 02: Index sloučeniny
Za určitých okolností můžeme chtít hledat položky na základě různých kritérií. Implementace složeného indexu pro tato pole může pomoci zlepšit výkon dotazů. Řekněme, že tentokrát chcete hledat v kolekci „Dummy“ pomocí více polí obsahujících různé podmínky vyhledávání, jak se zobrazí dotaz. Tento dotaz hledal záznamy z kolekce, kde je pole „type“ nastaveno na „emp“ a pole „sal“ je větší než 350.
K aplikaci podmínky na pole „sal“ byl použit logický operátor $gte. Po prohledání celé sbírky, která se skládá z 10 záznamů, byly vráceny celkem dva záznamy.
test> db.Dummy.find({type: 'emp' , prodej: {$gte: 350 } }) 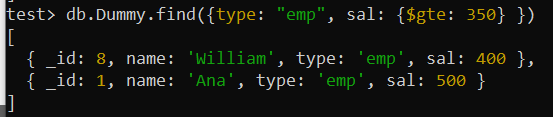
Vytvořme složený index pro výše uvedený dotaz. Tento složený index má pole „type“ a „sal“. Čísla „1“ a „-1“ představují vzestupné a sestupné pořadí pro pole „typ“ a „sal“. Pořadí sloupců složeného indexu je důležité a mělo by odpovídat vzorům dotazů. MongoDB dal tomuto složenému indexu, jak je zobrazen, název „type_1_sal_-1“.
test> db.Dummy.createIndex({ typ: 1 , vůle:- 1 }) 
Po použití stejného dotazu find() k vyhledání záznamů s hodnotou pole „typ“ jako „emp“ a hodnotou pole „sal“ větší než 350 jsme získali stejný výstup s mírnou změnou v pořadí. oproti předchozímu výsledku dotazu. Větší záznam hodnoty pro pole „sal“ je nyní na prvním místě, zatímco nejmenší je na nejnižším místě podle „-1“ nastavené pro pole „sal“ ve výše uvedeném složeném indexu.
test> db.Dummy.find({type: 'emp' , prodej: {$gte: 350 } }) 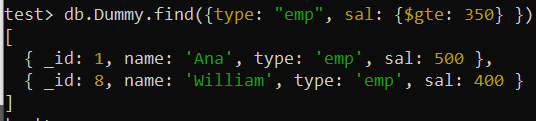
Příklad 03: Textový index
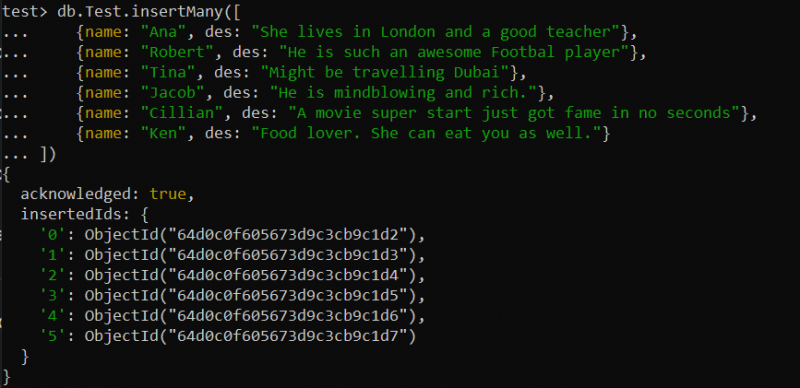
Někdy se můžete setkat se situací, kdy byste se měli zabývat velkým souborem dat, jako jsou velké popisy produktů, přísad atd. Textový index může být užitečný pro fulltextové vyhledávání ve velkém textovém poli. V naší testovací databázi jsme například vytvořili novou kolekci s názvem „Test“. Do této kolekce bylo vloženo celkem 6 záznamů pomocí funkce insertMany() podle dotazu find() níže.
test> db.Test.insertMany([{název: 'ana' , z: 'Žije v Londýně a je dobrá učitelka' },
{název: 'Robert' , z: 'Je to úžasný fotbalista' },
{název: 'z' , z: 'Možná cestuje po Dubaji' },
{název: 'Jakub' , z: 'Je úžasný a bohatý.' },
{název: 'Cillian' , z: 'Super začátek filmu se proslavil během několika sekund' },
{název: 'ken' , z: 'Milovník jídla. Může sníst i tebe.' }
])
Nyní vytvoříme textový index v poli „Des“ této kolekce pomocí funkce createIndex() MongoDB. Klíčové slovo „text“ v hodnotě pole zobrazuje typ indexu, což je „textový“ index. Název indexu, des_text, byl vygenerován automaticky.
test> db.Test.createIndex({ des: 'text' })Nyní byla funkce find() použita k provedení „textového vyhledávání“ v kolekci prostřednictvím indexu „des_text“. Operátor $search byl použit k vyhledání slova „jídlo“ v záznamech sbírky a zobrazení tohoto konkrétního záznamu.
test> db.Test.find({ $text: { $search: 'jídlo' }}); 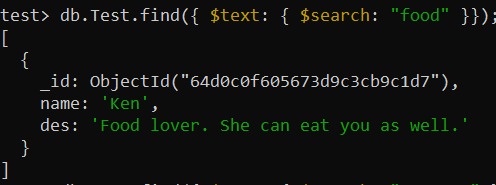
Ověřit indexy:
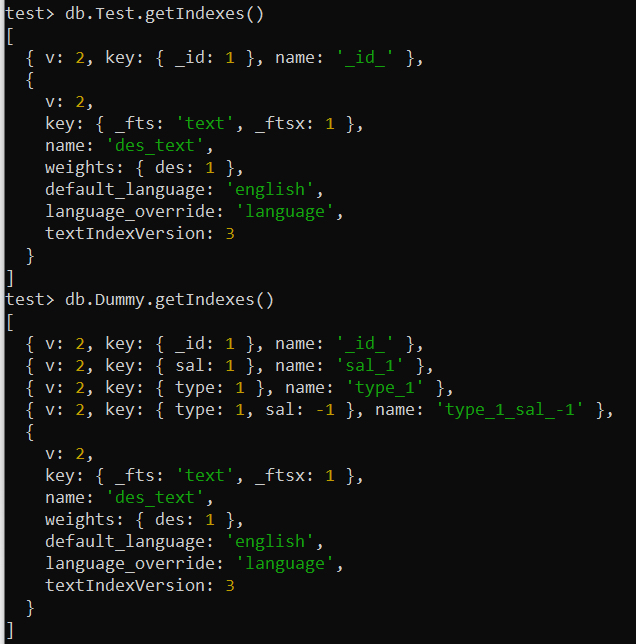
Můžete zkontrolovat a vypsat všechny použité indexy různých kolekcí ve vaší MongoDB. K tomu použijte metodu getIndexes() spolu s názvem kolekce na obrazovce prostředí MongoDB. Tento příkaz jsme použili samostatně pro kolekce „Test“ a „Dummy“. Na obrazovce se zobrazí všechny potřebné informace týkající se vestavěných a uživatelem definovaných indexů.
test> db.Test.getIndexes()test> db.Dummy.getIndexes()
Indexy poklesu:
Je čas odstranit indexy, které byly dříve vytvořeny pro kolekci pomocí funkce dropIndex() spolu se stejným názvem pole, na který byl index použit. Níže uvedený dotaz ukazuje, že jediný index byl odebrán.
test> db.Dummy.dropIndex({type: 1 }) 
Stejným způsobem lze vypustit složený index.
test> db.Dummy.drop index({type: 1 , vůle: 1 }) 
Závěr
Urychlením načítání dat z MongoDB je indexování zásadní pro zvýšení efektivity dotazů. Bez indexů musí MongoDB hledat odpovídající záznamy v celé kolekci, což se s rostoucí velikostí sady stává méně efektivní. Schopnost MongoDB rychle odhalit správné záznamy pomocí struktury indexové databáze urychluje zpracování dotazů při použití vhodného indexování.